 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Asset Embeddings from Financial Time Series
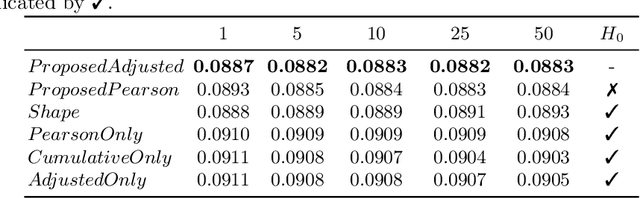
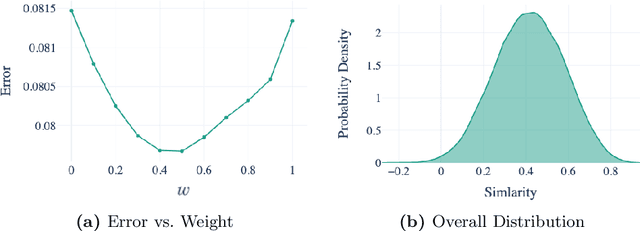
Jul 26, 2024Representation learning has emerged as a powerful paradigm for extracting valuable latent features from complex, high-dimensional data. In financial domains, learning informative representations for assets can be used for tasks like sector classification, and risk management. However, the complex and stochastic nature of financial markets poses unique challenges. We propose a novel contrastive learning framework to generate asset embeddings from financial time series data. Our approach leverages the similarity of asset returns over many subwindows to generate informative positive and negative samples, using a statistical sampling strategy based on hypothesis testing to address the noisy nature of financial data. We explore various contrastive loss functions that capture the relationships between assets in different ways to learn a discriminative representation space. Experiments on real-world datasets demonstrate the effectiveness of the learned asset embeddings on benchmark industry classification and portfolio optimization tasks. In each case our novel approaches significantly outperform existing baselines highlighting the potential for contrastive learning to capture meaningful and actionable relationships in financial data.
The Role of Document Embedding in Research Paper Recommender Systems: To Breakdown or to Bolster Disciplinary Borders?
Sep 26, 2023



In the extensive recommender systems literature, novelty and diversity have been identified as key properties of useful recommendations. However, these properties have received limited attention in the specific sub-field of research paper recommender systems. In this work, we argue for the importance of offering novel and diverse research paper recommendations to scientists. This approach aims to reduce siloed reading, break down filter bubbles, and promote interdisciplinary research. We propose a novel framework for evaluating the novelty and diversity of research paper recommendations that leverages methods from network analysis and natural language processing. Using this framework, we show that the choice of representational method within a larger research paper recommendation system can have a measurable impact on the nature of downstream recommendations, specifically on their novelty and diversity. We introduce a novel paper embedding method, which we demonstrate offers more innovative and diverse recommendations without sacrificing precision, compared to other state-of-the-art baselines.
Industry Classification Using a Novel Financial Time-Series Case Representation
Apr 29, 2023


The financial domain has proven to be a fertile source of challenging machine learning problems across a variety of tasks including prediction, clustering, and classification. Researchers can access an abundance of time-series data and even modest performance improvements can be translated into significant additional value. In this work, we consider the use of case-based reasoning for an important task in this domain, by using historical stock returns time-series data for industry sector classification. We discuss why time-series data can present some significant representational challenges for conventional case-based reasoning approaches, and in response, we propose a novel representation based on stock returns embeddings, which can be readily calculated from raw stock returns data. We argue that this representation is well suited to case-based reasoning and evaluate our approach using a large-scale public dataset for the industry sector classification task, demonstrating substantial performance improvements over several baselines using more conventional representations.
Item Graph Convolution Collaborative Filtering for Inductive Recommendations
Mar 28, 2023Graph Convolutional Networks (GCN) have been recently employed as core component in the construction of recommender system algorithms, interpreting user-item interactions as the edges of a bipartite graph. However, in the absence of side information, the majority of existing models adopt an approach of randomly initialising the user embeddings and optimising them throughout the training process. This strategy makes these algorithms inherently transductive, curtailing their ability to generate predictions for users that were unseen at training time. To address this issue, we propose a convolution-based algorithm, which is inductive from the user perspective, while at the same time, depending only on implicit user-item interaction data. We propose the construction of an item-item graph through a weighted projection of the bipartite interaction network and to employ convolution to inject higher order associations into item embeddings, while constructing user representations as weighted sums of the items with which they have interacted. Despite not training individual embeddings for each user our approach achieves state of-the-art recommendation performance with respect to transductive baselines on four real-world datasets, showing at the same time robust inductive performance.
Stock Embeddings: Learning Distributed Representations for Financial Assets
Feb 14, 2022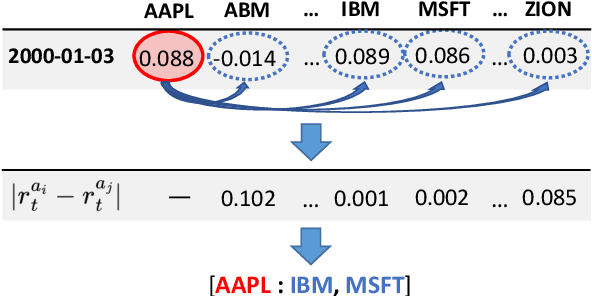
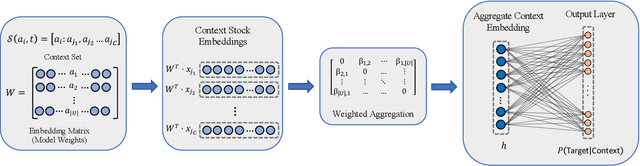
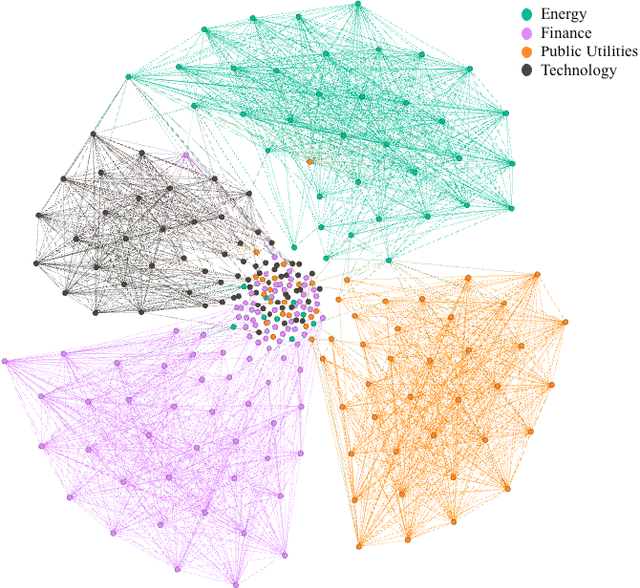
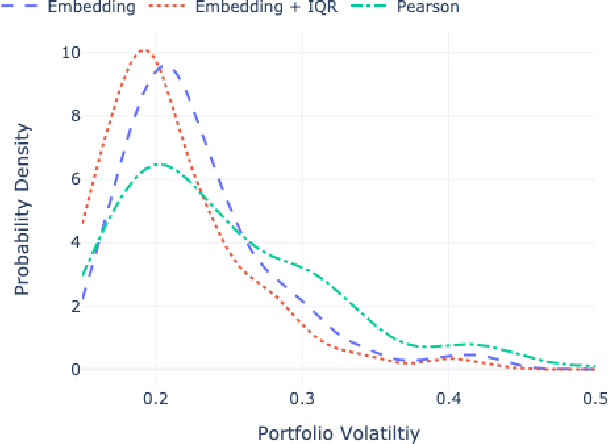
Identifying meaningful relationships between the price movements of financial assets is a challenging but important problem in a variety of financial applications. However with recent research, particularly those using machine learning and deep learning techniques, focused mostly on price forecasting, the literature investigating the modelling of asset correlations has lagged somewhat. To address this, inspired by recent successes in natural language processing, we propose a neural model for training stock embeddings, which harnesses the dynamics of historical returns data in order to learn the nuanced relationships that exist between financial assets. We describe our approach in detail and discuss a number of ways that it can be used in the financial domain. Furthermore, we present the evaluation results to demonstrate the utility of this approach, compared to several important benchmarks, in two real-world financial analytics tasks.
NumHTML: Numeric-Oriented Hierarchical Transformer Model for Multi-task Financial Forecasting
Jan 05, 2022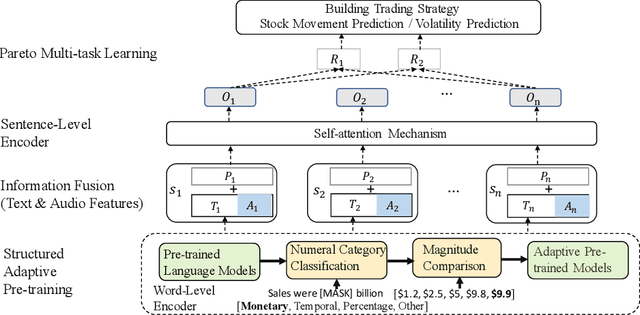
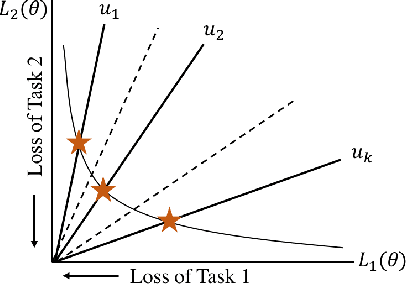

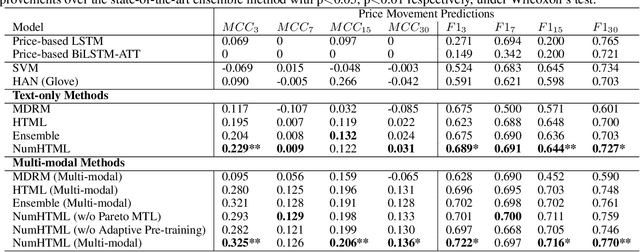
Financial forecasting has been an important and active area of machine learning research because of the challenges it presents and the potential rewards that even minor improvements in prediction accuracy or forecasting may entail. Traditionally, financial forecasting has heavily relied on quantitative indicators and metrics derived from structured financial statements. Earnings conference call data, including text and audio, is an important source of unstructured data that has been used for various prediction tasks using deep earning and related approaches. However, current deep learning-based methods are limited in the way that they deal with numeric data; numbers are typically treated as plain-text tokens without taking advantage of their underlying numeric structure. This paper describes a numeric-oriented hierarchical transformer model to predict stock returns, and financial risk using multi-modal aligned earnings calls data by taking advantage of the different categories of numbers (monetary, temporal, percentages etc.) and their magnitude. We present the results of a comprehensive evaluation of NumHTML against several state-of-the-art baselines using a real-world publicly available dataset. The results indicate that NumHTML significantly outperforms the current state-of-the-art across a variety of evaluation metrics and that it has the potential to offer significant financial gains in a practical trading context.
Investigating Health-Aware Smart-Nudging with Machine Learning to Help People Pursue Healthier Eating-Habits
Oct 05, 2021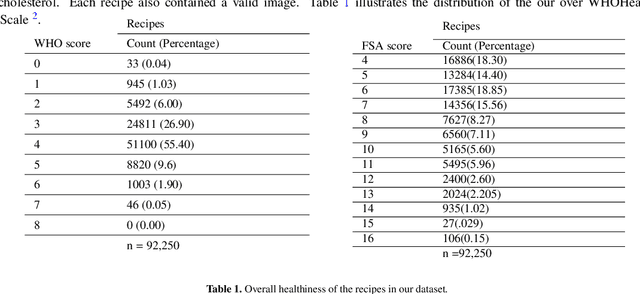

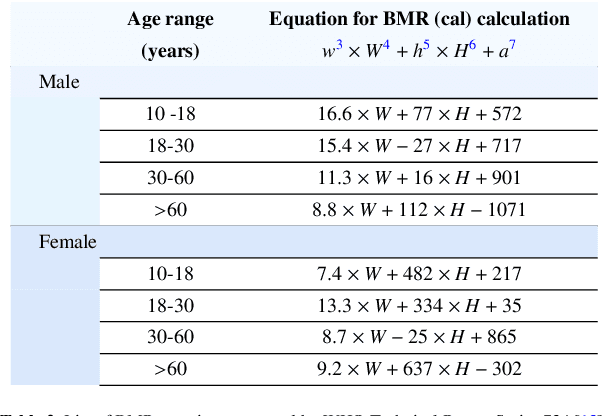

Food-choices and eating-habits directly contribute to our long-term health. This makes the food recommender system a potential tool to address the global crisis of obesity and malnutrition. Over the past decade, artificial-intelligence and medical researchers became more invested in researching tools that can guide and help people make healthy and thoughtful decisions around food and diet. In many typical (Recommender System) RS domains, smart nudges have been proven effective in shaping users' consumption patterns. In recent years, knowledgeable nudging and incentifying choices started getting attention in the food domain as well. To develop smart nudging for promoting healthier food choices, we combined Machine Learning and RS technology with food-healthiness guidelines from recognized health organizations, such as the World Health Organization, Food Standards Agency, and the National Health Service United Kingdom. In this paper, we discuss our research on, persuasive visualization for making users aware of the healthiness of the recommended recipes. Here, we propose three novel nudging technology, the WHO-BubbleSlider, the FSA-ColorCoading, and the DRCI-MLCP, that encourage users to choose healthier recipes. We also propose a Topic Modeling based portion-size recommendation algorithm. To evaluate our proposed smart-nudges, we conducted an online user study with 96 participants and 92250 recipes. Results showed that, during the food decision-making process, appropriate healthiness cues make users more likely to click, browse, and choose healthier recipes over less healthy ones.
Measuring Financial Time Series Similarity With a View to Identifying Profitable Stock Market Opportunities
Jul 07, 2021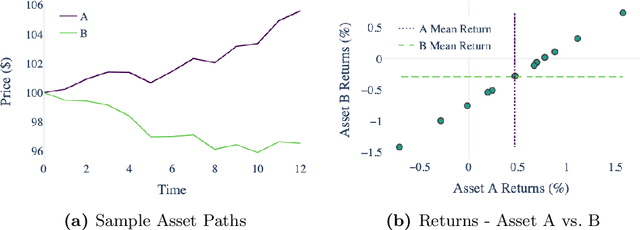
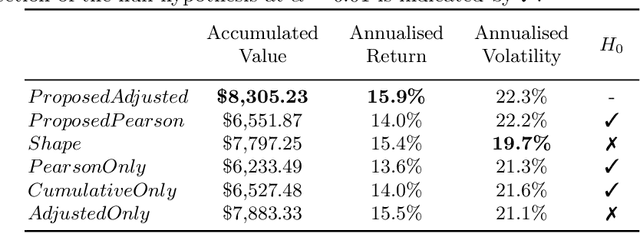
Forecasting stock returns is a challenging problem due to the highly stochastic nature of the market and the vast array of factors and events that can influence trading volume and prices. Nevertheless it has proven to be an attractive target for machine learning research because of the potential for even modest levels of prediction accuracy to deliver significant benefits. In this paper, we describe a case-based reasoning approach to predicting stock market returns using only historical pricing data. We argue that one of the impediments for case-based stock prediction has been the lack of a suitable similarity metric when it comes to identifying similar pricing histories as the basis for a future prediction -- traditional Euclidean and correlation based approaches are not effective for a variety of reasons -- and in this regard, a key contribution of this work is the development of a novel similarity metric for comparing historical pricing data. We demonstrate the benefits of this metric and the case-based approach in a real-world application in comparison to a variety of conventional benchmarks.
Fact Check: Analyzing Financial Events from Multilingual News Sources
Jun 30, 2021
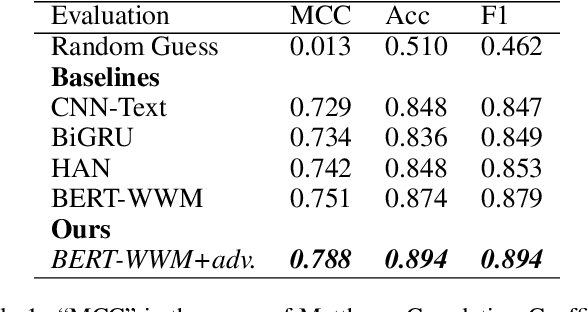
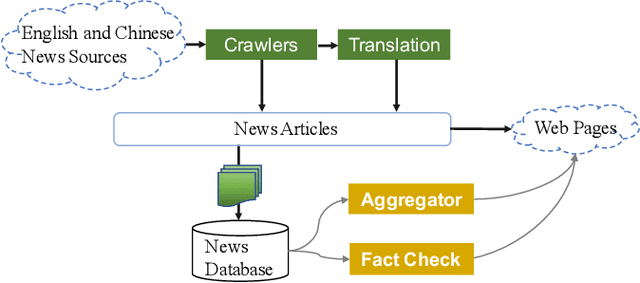
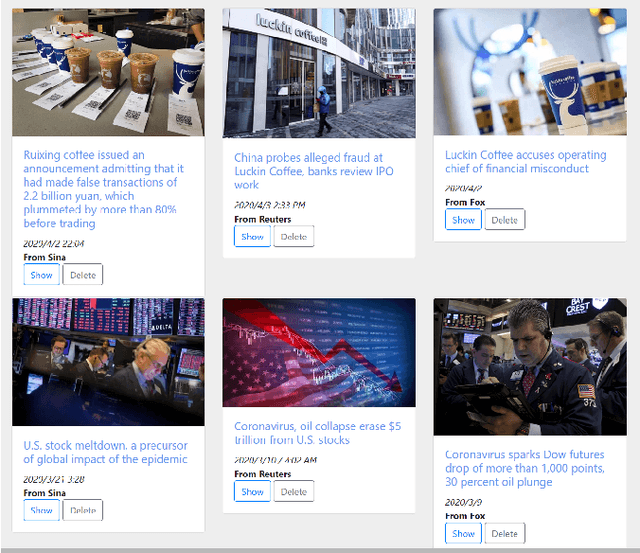
The explosion in the sheer magnitude and complexity of financial news data in recent years makes it increasingly challenging for investment analysts to extract valuable insights and perform analysis. We propose FactCheck in finance, a web-based news aggregator with deep learning models, to provide analysts with a holistic view of important financial events from multilingual news sources and extract events using an unsupervised clustering method. A web interface is provided to examine the credibility of news articles using a transformer-based fact-checker. The performance of the fact checker is evaluated using a dataset related to merger and acquisition (M\&A) events and is shown to outperform several strong baselines.
Exploring the Efficacy of Automatically Generated Counterfactuals for Sentiment Analysis
Jun 30, 2021

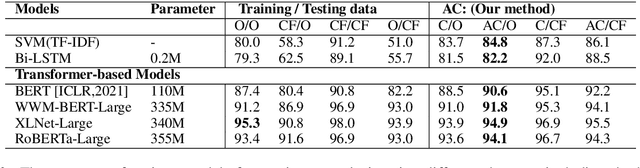

While state-of-the-art NLP models have been achieving the excellent performance of a wide range of tasks in recent years, important questions are being raised about their robustness and their underlying sensitivity to systematic biases that may exist in their training and test data. Such issues come to be manifest in performance problems when faced with out-of-distribution data in the field. One recent solution has been to use counterfactually augmented datasets in order to reduce any reliance on spurious patterns that may exist in the original data. Producing high-quality augmented data can be costly and time-consuming as it usually needs to involve human feedback and crowdsourcing efforts. In this work, we propose an alternative by describing and evaluating an approach to automatically generating counterfactual data for data augmentation and explanation. A comprehensive evaluation on several different datasets and using a variety of state-of-the-art benchmarks demonstrate how our approach can achieve significant improvements in model performance when compared to models training on the original data and even when compared to models trained with the benefit of human-generated augmented data.