 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Poisson Point Process Intensity Function Modeling and Estimation with Measure Transport
Jan 24, 2022

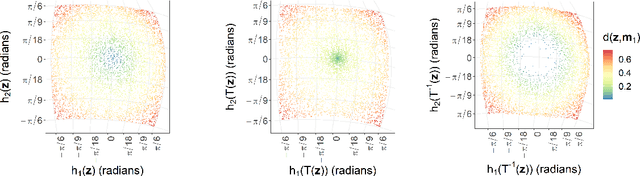
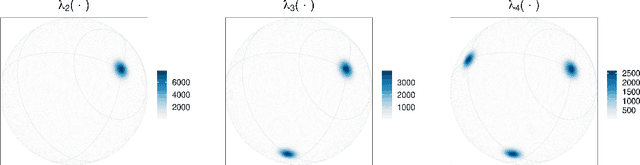
Recent years have seen an increased interest in the application of methods and techniques commonly associated with machine learning and artificial intelligence to spatial statistics. Here, in a celebration of the ten-year anniversary of the journal Spatial Statistics, we bring together normalizing flows, commonly used for density function estimation in machine learning, and spherical point processes, a topic of particular interest to the journal's readership, to present a new approach for modeling non-homogeneous Poisson process intensity functions on the sphere. The central idea of this framework is to build, and estimate, a flexible bijective map that transforms the underlying intensity function of interest on the sphere into a simpler, reference, intensity function, also on the sphere. Map estimation can be done efficiently using automatic differentiation and stochastic gradient descent, and uncertainty quantification can be done straightforwardly via nonparametric bootstrap. We investigate the viability of the proposed method in a simulation study, and illustrate its use in a proof-of-concept study where we model the intensity of cyclone events in the North Pacific Ocean. Our experiments reveal that normalizing flows present a flexible and straightforward way to model intensity functions on spheres, but that their potential to yield a good fit depends on the architecture of the bijective map, which can be difficult to establish in practice.
Fact Check: Analyzing Financial Events from Multilingual News Sources
Jun 30, 2021
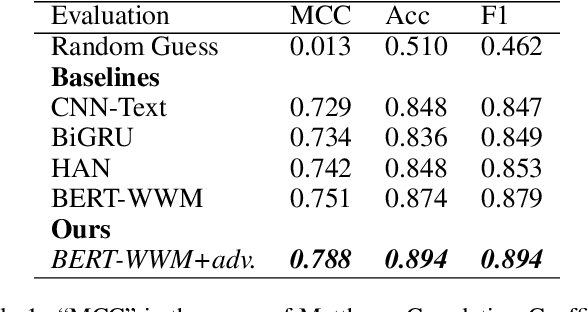
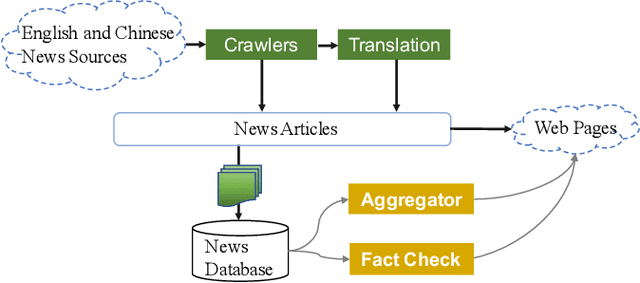
The explosion in the sheer magnitude and complexity of financial news data in recent years makes it increasingly challenging for investment analysts to extract valuable insights and perform analysis. We propose FactCheck in finance, a web-based news aggregator with deep learning models, to provide analysts with a holistic view of important financial events from multilingual news sources and extract events using an unsupervised clustering method. A web interface is provided to examine the credibility of news articles using a transformer-based fact-checker. The performance of the fact checker is evaluated using a dataset related to merger and acquisition (M\&A) events and is shown to outperform several strong baselines.
Posterior Regularisation on Bayesian Hierarchical Mixture Clustering
May 17, 2021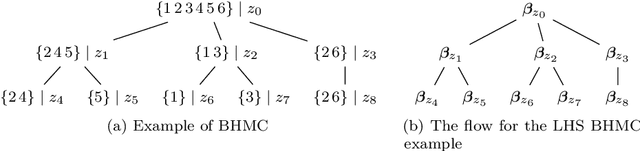

We study a recent inferential framework, named posterior regularisation, on the Bayesian hierarchical mixture clustering (BHMC) model. This framework facilitates a simple way to impose extra constraints on a Bayesian model to overcome some weakness of the original model. It narrows the search space of the parameters of the Bayesian model through a formalism that imposes certain constraints on the features of the found solutions. In this paper, in order to enhance the separation of clusters, we apply posterior regularisation to impose max-margin constraints on the nodes at every level of the hierarchy. This paper shows how the framework integrates with BHMC and achieves the expected improvements over the original Bayesian model.
Generating Plausible Counterfactual Explanations for Deep Transformers in Financial Text Classification
Oct 23, 2020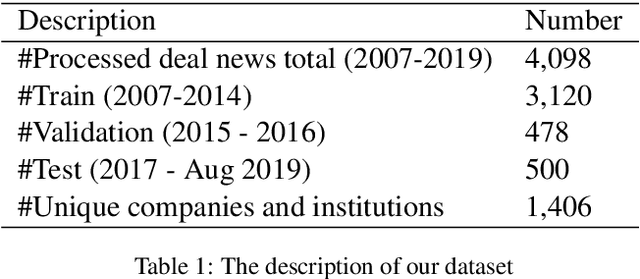
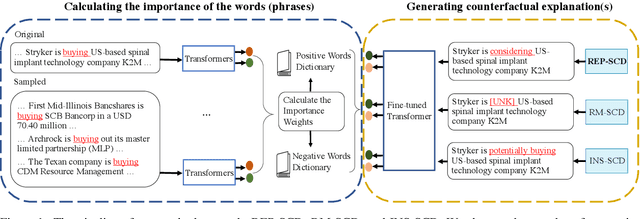
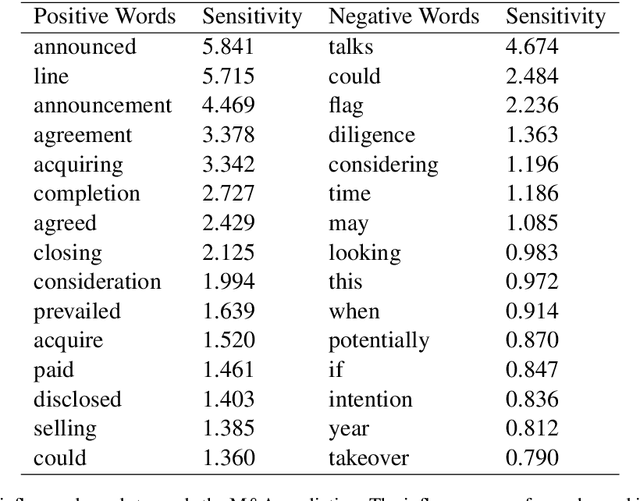
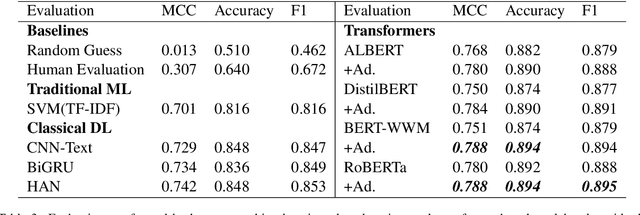
Corporate mergers and acquisitions (M&A) account for billions of dollars of investment globally every year, and offer an interesting and challenging domain for artificial intelligence. However, in these highly sensitive domains, it is crucial to not only have a highly robust and accurate model, but be able to generate useful explanations to garner a user's trust in the automated system. Regrettably, the recent research regarding eXplainable AI (XAI) in financial text classification has received little to no attention, and many current methods for generating textual-based explanations result in highly implausible explanations, which damage a user's trust in the system. To address these issues, this paper proposes a novel methodology for producing plausible counterfactual explanations, whilst exploring the regularization benefits of adversarial training on language models in the domain of FinTech. Exhaustive quantitative experiments demonstrate that not only does this approach improve the model accuracy when compared to the current state-of-the-art and human performance, but it also generates counterfactual explanations which are significantly more plausible based on human trials.
Deep Compositional Spatial Models
Jun 06, 2019
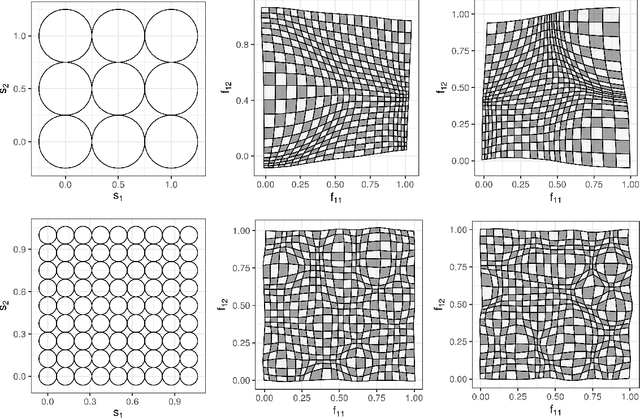

Nonstationary, anisotropic spatial processes are often used when modelling, analysing and predicting complex environmental phenomena. One such class of processes considers a stationary, isotropic process on a warped spatial domain. The warping function is generally difficult to fit and not constrained to be bijective, often resulting in 'space-folding.' Here, we propose modelling a bijective warping function through a composition of multiple elemental bijective functions in a deep-learning framework. We consider two cases; first, when these functions are known up to some weights that need to be estimated, and, second, when the weights in each layer are random. Inspired by recent methodological and technological advances in deep learning and deep Gaussian processes, we employ approximate Bayesian methods to make inference with these models using graphical processing units. Through simulation studies in one and two dimensions we show that the deep compositional spatial models are quick to fit, and are able to provide better predictions and uncertainty quantification than other deep stochastic models of similar complexity. We also show their remarkable capacity to model highly nonstationary, anisotropic spatial data using radiances from the MODIS instrument aboard the Aqua satellite.