 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Noisy Multilabel Predictions: Modeling Label Noise through Latent Space Shifts
Feb 20, 2025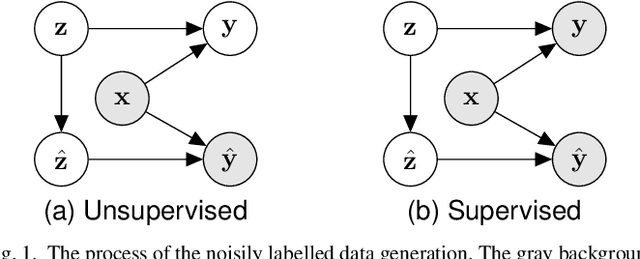



Noise in data appears to be inevitable in most real-world machine learning applications and would cause severe overfitting problems. Not only can data features contain noise, but labels are also prone to be noisy due to human input. In this paper, rather than noisy label learning in multiclass classifications, we instead focus on the less explored area of noisy label learning for multilabel classifications. Specifically, we investigate the post-correction of predictions generated from classifiers learned with noisy labels. The reasons are two-fold. Firstly, this approach can directly work with the trained models to save computational resources. Secondly, it could be applied on top of other noisy label correction techniques to achieve further improvements. To handle this problem, we appeal to deep generative approaches that are possible for uncertainty estimation. Our model posits that label noise arises from a stochastic shift in the latent variable, providing a more robust and beneficial means for noisy learning. We develop both unsupervised and semi-supervised learning methods for our model. The extensive empirical study presents solid evidence to that our approach is able to consistently improve the independent models and performs better than a number of existing methods across various noisy label settings. Moreover, a comprehensive empirical analysis of the proposed method is carried out to validate its robustness, including sensitivity analysis and an ablation study, among other elements.
Posterior Regularisation on Bayesian Hierarchical Mixture Clustering
May 17, 2021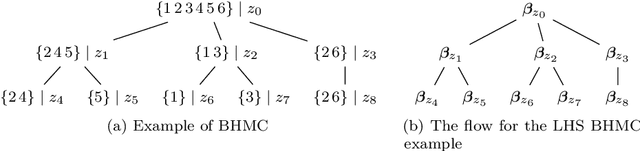

We study a recent inferential framework, named posterior regularisation, on the Bayesian hierarchical mixture clustering (BHMC) model. This framework facilitates a simple way to impose extra constraints on a Bayesian model to overcome some weakness of the original model. It narrows the search space of the parameters of the Bayesian model through a formalism that imposes certain constraints on the features of the found solutions. In this paper, in order to enhance the separation of clusters, we apply posterior regularisation to impose max-margin constraints on the nodes at every level of the hierarchy. This paper shows how the framework integrates with BHMC and achieves the expected improvements over the original Bayesian model.
Evaluating Hierarchies through A Partially Observable Markov Decision Processes Methodology
Aug 27, 2019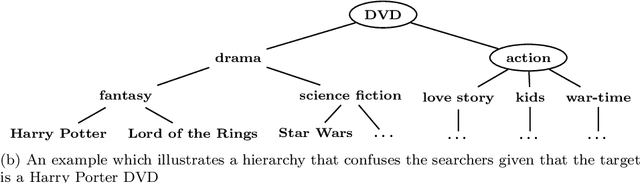
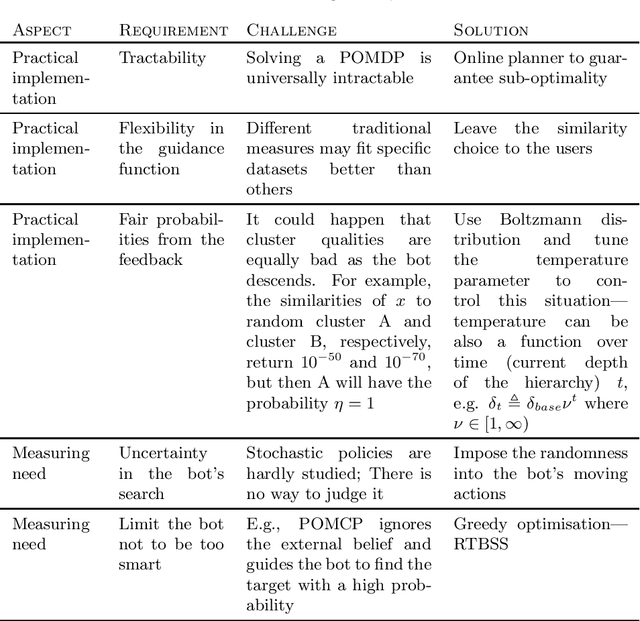
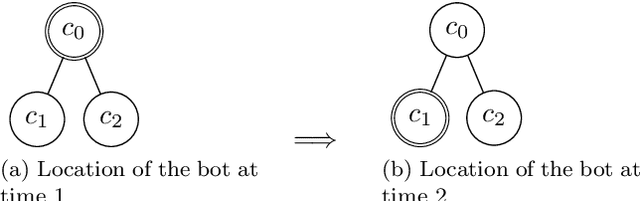

Hierarchical clustering has been shown to be valuable in many scenarios, e.g. catalogues, biology research, image processing, and so on. Despite its usefulness to many situations, there is no agreed methodology on how to properly evaluate the hierarchies produced from different techniques, particularly in the case where ground-truth labels are unavailable. This motivates us to propose a framework for assessing the quality of hierarchical clustering allocations which covers the case of no ground-truth information. Such a quality measurement is useful, for example, to assess the hierarchical structures used by online retailer websites to display their product catalogues. Differently to all the previous measures and metrics, our framework tackles the evaluation from a decision theoretic perspective. We model the process as a bot searching stochastically for items in the hierarchy and establish a measure representing the degree to which the hierarchy supports this search. We employ the concept of Partially Observable Markov Decision Processes (POMDP) to model the uncertainty, the decision making, and the cognitive return for searchers in such a scenario. In this paper, we fully discuss the modeling details and demonstrate its application on some datasets.
Using Model-based Overlapping Seed Expansion to detect highly overlapping community structure
Nov 17, 2010

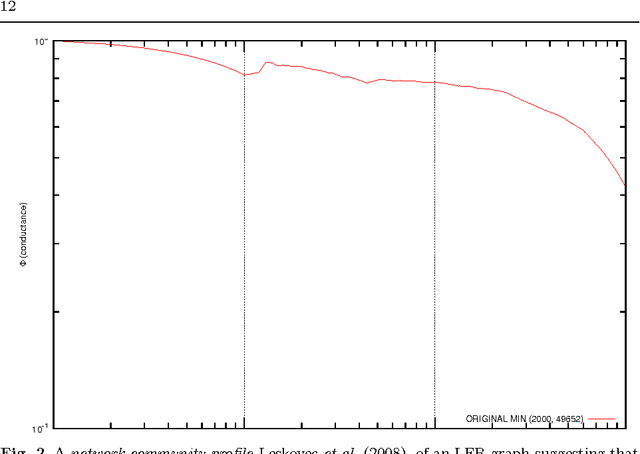
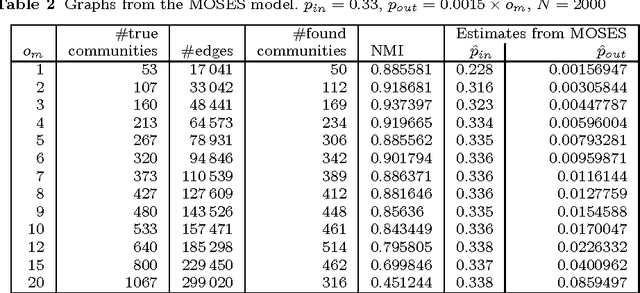
As research into community finding in social networks progresses, there is a need for algorithms capable of detecting overlapping community structure. Many algorithms have been proposed in recent years that are capable of assigning each node to more than a single community. The performance of these algorithms tends to degrade when the ground-truth contains a more highly overlapping community structure, with nodes assigned to more than two communities. Such highly overlapping structure is likely to exist in many social networks, such as Facebook friendship networks. In this paper we present a scalable algorithm, MOSES, based on a statistical model of community structure, which is capable of detecting highly overlapping community structure, especially when there is variance in the number of communities each node is in. In evaluation on synthetic data MOSES is found to be superior to existing algorithms, especially at high levels of overlap. We demonstrate MOSES on real social network data by analyzing the networks of friendship links between students of five US universities.