 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENDE: Transfer Entropy Neural Diffusion Estimation
Oct 15, 2025Transfer entropy measures directed information flow in time series, and it has become a fundamental quantity in applications spanning neuroscience, finance, and complex systems analysis. However, existing estimation methods suffer from the curse of dimensionality, require restrictive distributional assumptions, or need exponentially large datasets for reliable convergence. We address these limitations in the literature by proposing TENDE (Transfer Entropy Neural Diffusion Estimation), a novel approach that leverages score-based diffusion models to estimate transfer entropy through conditional mutual information. By learning score functions of the relevant conditional distributions, TENDE provides flexible, scalable estimation while making minimal assumptions about the underlying data-generating process. We demonstrate superior accuracy and robustness compared to existing neural estimators and other state-of-the-art approaches across synthetic benchmarks and real data.
Universal Adaptive Environment Discovery
Oct 14, 2025An open problem in Machine Learning is how to avoid models to exploit spurious correlations in the data; a famous example is the background-label shortcut in the Waterbirds dataset. A common remedy is to train a model across multiple environments; in the Waterbirds dataset, this corresponds to training by randomizing the background. However, selecting the right environments is a challenging problem, given that these are rarely known a priori. We propose Universal Adaptive Environment Discovery (UAED), a unified framework that learns a distribution over data transformations that instantiate environments, and optimizes any robust objective averaged over this learned distribution. UAED yields adaptive variants of IRM, REx, GroupDRO, and CORAL without predefined groups or manual environment design. We provide a theoretical analysis by providing PAC-Bayes bounds and by showing robustness to test environment distributions under standard conditions. Empirically, UAED discovers interpretable environment distributions and improves worst-case accuracy on standard benchmarks, while remaining competitive on mean accuracy. Our results indicate that making environments adaptive is a practical route to out-of-distribution generalization.
Scaling Laws for Uncertainty in Deep Learning
Jun 11, 2025Deep learning has recently revealed the existence of scaling laws, demonstrating that model performance follows predictable trends based on dataset and model sizes. Inspired by these findings and fascinating phenomena emerging in the over-parameterized regime, we examine a parallel direction: do similar scaling laws govern predictive uncertainties in deep learning? In identifiable parametric models, such scaling laws can be derived in a straightforward manner by treating model parameters in a Bayesian way. In this case, for example, we obtain $O(1/N)$ contraction rates for epistemic uncertainty with respect to the number of data $N$. However, in over-parameterized models, these guarantees do not hold, leading to largely unexplored behaviors. In this work, we empirically show the existence of scaling laws associated with various measures of predictive uncertainty with respect to dataset and model sizes. Through experiments on vision and language tasks, we observe such scaling laws for in- and out-of-distribution predictive uncertainty estimated through popular approximate Bayesian inference and ensemble methods. Besides the elegance of scaling laws and the practical utility of extrapolating uncertainties to larger data or models, this work provides strong evidence to dispel recurring skepticism against Bayesian approaches: "In many applications of deep learning we have so much data available: what do we need Bayes for?". Our findings show that "so much data" is typically not enough to make epistemic uncertainty negligible.
Variational Inference for Quantum HyperNetworks
Jun 06, 2025Binary Neural Networks (BiNNs), which employ single-bit precision weights, have emerged as a promising solution to reduce memory usage and power consumption while maintaining competitive performance in large-scale systems. However, training BiNNs remains a significant challenge due to the limitations of conventional training algorithms. Quantum HyperNetworks offer a novel paradigm for enhancing the optimization of BiNN by leveraging quantum computing. Specifically, a Variational Quantum Algorithm is employed to generate binary weights through quantum circuit measurements, while key quantum phenomena such as superposition and entanglement facilitate the exploration of a broader solution space. In this work, we establish a connection between this approach and Bayesian inference by deriving the Evidence Lower Bound (ELBO), when direct access to the output distribution is available (i.e., in simulations), and introducing a surrogate ELBO based on the Maximum Mean Discrepancy (MMD) metric for scenarios involving implicit distributions, as commonly encountered in practice. Our experimental results demonstrate that the proposed methods outperform standard Maximum Likelihood Estimation (MLE), improving trainability and generalization.
Optimizing Data Augmentation through Bayesian Model Selection
May 27, 2025Data Augmentation (DA) has become an essential tool to improve robustness and generalization of modern machine learning. However, when deciding on DA strategies it is critical to choose parameters carefully, and this can be a daunting task which is traditionally left to trial-and-error or expensive optimization based on validation performance. In this paper, we counter these limitations by proposing a novel framework for optimizing DA. In particular, we take a probabilistic view of DA, which leads to the interpretation of augmentation parameters as model (hyper)-parameters, and the optimization of the marginal likelihood with respect to these parameters as a Bayesian model selection problem. Due to its intractability, we derive a tractable Evidence Lower BOund (ELBO), which allows us to optimize augmentation parameters jointly with model parameters. We provide extensive theoretical results on variational approximation quality, generalization guarantees, invariance properties, and connections to empirical Bayes. Through experiments on computer vision tasks, we show that our approach improves calibration and yields robust performance over fixed or no augmentation. Our work provides a rigorous foundation for optimizing DA through Bayesian principles with significant potential for robust machine learning.
Zero-shot Model-based Reinforcement Learning using Large Language Models
Oct 15, 2024



The emerging zero-shot capabilities of Large Language Models (LLMs) have led to their applications in areas extending well beyond natural language processing tasks. In reinforcement learning, while LLMs have been extensively used in text-based environments, their integration with continuous state spaces remains understudied. In this paper, we investigate how pre-trained LLMs can be leveraged to predict in context the dynamics of continuous Markov decision processes. We identify handling multivariate data and incorporating the control signal as key challenges that limit the potential of LLMs' deployment in this setup and propose Disentangled In-Context Learning (DICL) to address them. We present proof-of-concept applications in two reinforcement learning settings: model-based policy evaluation and data-augmented off-policy reinforcement learning, supported by theoretical analysis of the proposed methods. Our experiments further demonstrate that our approach produces well-calibrated uncertainty estimates. We release the code at https://github.com/abenechehab/dicl.
Robust Classification by Coupling Data Mollification with Label Smoothing
Jun 03, 2024



Introducing training-time augmentations is a key technique to enhance generalization and prepare deep neural networks against test-time corruptions. Inspired by the success of generative diffusion models, we propose a novel approach coupling data augmentation, in the form of image noising and blurring, with label smoothing to align predicted label confidences with image degradation. The method is simple to implement, introduces negligible overheads, and can be combined with existing augmentations. We demonstrate improved robustness and uncertainty quantification on the corrupted image benchmarks of the CIFAR and TinyImageNet datasets.
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Feb 06, 2024
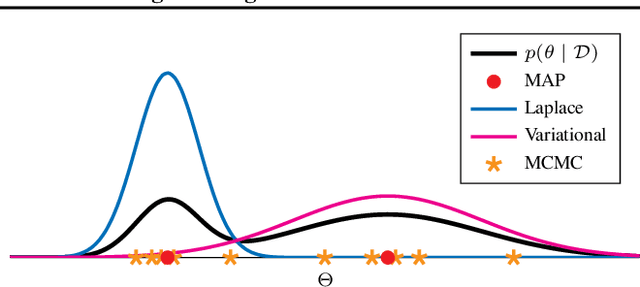
In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
A Multi-step Loss Function for Robust Learning of the Dynamics in Model-based Reinforcement Learning
Feb 05, 2024In model-based reinforcement learning, most algorithms rely on simulating trajectories from one-step models of the dynamics learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as the length of the trajectory grows. In this paper we tackle this issue by using a multi-step objective to train one-step models. Our objective is a weighted sum of the mean squared error (MSE) loss at various future horizons. We find that this new loss is particularly useful when the data is noisy (additive Gaussian noise in the observations), which is often the case in real-life environments. To support the multi-step loss, first we study its properties in two tractable cases: i) uni-dimensional linear system, and ii) two-parameter non-linear system. Second, we show in a variety of tasks (environments or datasets) that the models learned with this loss achieve a significant improvement in terms of the averaged R2-score on future prediction horizons. Finally, in the pure batch reinforcement learning setting, we demonstrate that one-step models serve as strong baselines when dynamics are deterministic, while multi-step models would be more advantageous in the presence of noise, highlighting the potential of our approach in real-world applications.
Variational DAG Estimation via State Augmentation With Stochastic Permutations
Feb 04, 2024



Estimating the structure of a Bayesian network, in the form of a directed acyclic graph (DAG), from observational data is a statistically and computationally hard problem with essential applications in areas such as causal discovery. Bayesian approaches are a promising direction for solving this task, as they allow for uncertainty quantification and deal with well-known identifiability issues. From a probabilistic inference perspective, the main challenges are (i) representing distributions over graphs that satisfy the DAG constraint and (ii) estimating a posterior over the underlying combinatorial space. We propose an approach that addresses these challenges by formulating a joint distribution on an augmented space of DAGs and permutations. We carry out posterior estimation via variational inference, where we exploit continuous relaxations of discrete distributions. We show that our approach can outperform competitive Bayesian and non-Bayesian benchmarks on a range of synthetic and real datasets.