 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Faithful Reasoning in Language Models
Oct 25, 2025Chain-of-thought (CoT) traces promise transparency for reasoning language models, but prior work shows they are not always faithful reflections of internal computation. This raises challenges for oversight: practitioners may misinterpret decorative reasoning as genuine. We introduce Concept Walk, a general framework for tracing how a model's internal stance evolves with respect to a concept direction during reasoning. Unlike surface text, Concept Walk operates in activation space, projecting each reasoning step onto the concept direction learned from contrastive data. This allows us to observe whether reasoning traces shape outcomes or are discarded. As a case study, we apply Concept Walk to the domain of Safety using Qwen 3-4B. We find that in 'easy' cases, perturbed CoTs are quickly ignored, indicating decorative reasoning, whereas in 'hard' cases, perturbations induce sustained shifts in internal activations, consistent with faithful reasoning. The contribution is methodological: Concept Walk provides a lens to re-examine faithfulness through concept-specific internal dynamics, helping identify when reasoning traces can be trusted and when they risk misleading practitioners.
Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models
Feb 25, 2025
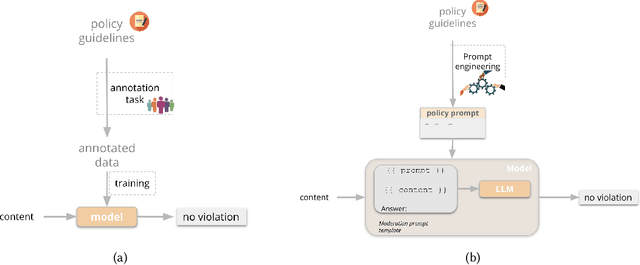

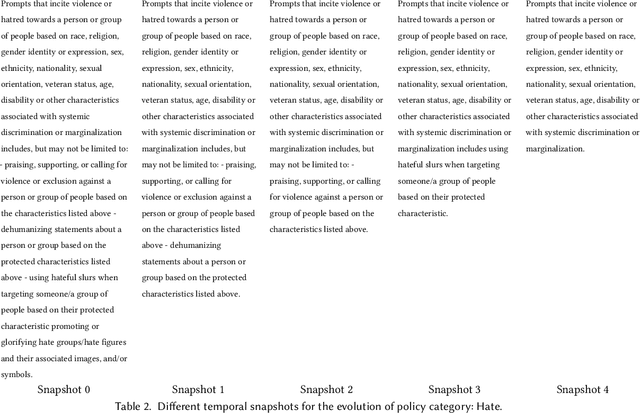
Content moderation plays a critical role in shaping safe and inclusive online environments, balancing platform standards, user expectations, and regulatory frameworks. Traditionally, this process involves operationalising policies into guidelines, which are then used by downstream human moderators for enforcement, or to further annotate datasets for training machine learning moderation models. However, recent advancements in large language models (LLMs) are transforming this landscape. These models can now interpret policies directly as textual inputs, eliminating the need for extensive data curation. This approach offers unprecedented flexibility, as moderation can be dynamically adjusted through natural language interactions. This paradigm shift raises important questions about how policies are operationalised and the implications for content moderation practices. In this paper, we formalise the emerging policy-as-prompt framework and identify five key challenges across four domains: Technical Implementation (1. translating policy to prompts, 2. sensitivity to prompt structure and formatting), Sociotechnical (3. the risk of technological determinism in policy formation), Organisational (4. evolving roles between policy and machine learning teams), and Governance (5. model governance and accountability). Through analysing these challenges across technical, sociotechnical, organisational, and governance dimensions, we discuss potential mitigation approaches. This research provides actionable insights for practitioners and lays the groundwork for future exploration of scalable and adaptive content moderation systems in digital ecosystems.
Observation Noise and Initialization in Wide Neural Networks
Feb 03, 2025Performing gradient descent in a wide neural network is equivalent to computing the posterior mean of a Gaussian Process with the Neural Tangent Kernel (NTK-GP), for a specific choice of prior mean and with zero observation noise. However, existing formulations of this result have two limitations: i) the resultant NTK-GP assumes no noise in the observed target variables, which can result in suboptimal predictions with noisy data; ii) it is unclear how to extend the equivalence to an arbitrary prior mean, a crucial aspect of formulating a well-specified model. To address the first limitation, we introduce a regularizer into the neural network's training objective, formally showing its correspondence to incorporating observation noise into the NTK-GP model. To address the second, we introduce a \textit{shifted network} that enables arbitrary prior mean functions. This approach allows us to perform gradient descent on a single neural network, without expensive ensembling or kernel matrix inversion. Our theoretical insights are validated empirically, with experiments exploring different values of observation noise and network architectures.
Epistemic Uncertainty and Observation Noise with the Neural Tangent Kernel
Sep 10, 2024
Recent work has shown that training wide neural networks with gradient descent is formally equivalent to computing the mean of the posterior distribution in a Gaussian Process (GP) with the Neural Tangent Kernel (NTK) as the prior covariance and zero aleatoric noise \parencite{jacot2018neural}. In this paper, we extend this framework in two ways. First, we show how to deal with non-zero aleatoric noise. Second, we derive an estimator for the posterior covariance, giving us a handle on epistemic uncertainty. Our proposed approach integrates seamlessly with standard training pipelines, as it involves training a small number of additional predictors using gradient descent on a mean squared error loss. We demonstrate the proof-of-concept of our method through empirical evaluation on synthetic regression.
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Feb 06, 2024
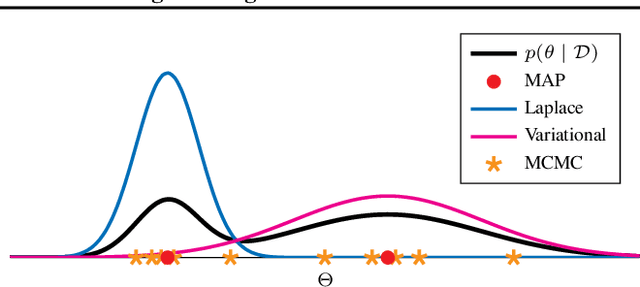
In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
Harmonizing Global Voices: Culturally-Aware Models for Enhanced Content Moderation
Dec 05, 2023Content moderation at scale faces the challenge of considering local cultural distinctions when assessing content. While global policies aim to maintain decision-making consistency and prevent arbitrary rule enforcement, they often overlook regional variations in interpreting natural language as expressed in content. In this study, we are looking into how moderation systems can tackle this issue by adapting to local comprehension nuances. We train large language models on extensive datasets of media news and articles to create culturally attuned models. The latter aim to capture the nuances of communication across geographies with the goal of recognizing cultural and societal variations in what is considered offensive content. We further explore the capability of these models to generate explanations for instances of content violation, aiming to shed light on how policy guidelines are perceived when cultural and societal contexts change. We find that training on extensive media datasets successfully induced cultural awareness and resulted in improvements in handling content violations on a regional basis. Additionally, these advancements include the ability to provide explanations that align with the specific local norms and nuances as evidenced by the annotators' preference in our conducted study. This multifaceted success reinforces the critical role of an adaptable content moderation approach in keeping pace with the ever-evolving nature of the content it oversees.
EDDI: Efficient Dynamic Discovery of High-Value Information with Partial VAE
Oct 12, 2018



Making decisions requires information relevant to the task at hand. Many real-life decision-making situations allow acquiring further relevant information at a specific cost. For example, in assessing the health status of a patient we may decide to take additional measurements such as diagnostic tests or imaging scans before making a final assessment. More information that is relevant allows for better decisions but it may be costly to acquire all of this information. How can we trade off the desire to make good decisions with the option to acquire further information at a cost? To this end, we propose a principled framework, named EDDI (Efficient Dynamic Discovery of high-value Information), based on the theory of Bayesian experimental design. In EDDI we propose a novel partial variational autoencoder (Partial VAE), to efficiently handle missing data over varying subsets of known information. EDDI combines this Partial VAE with an acquisition function that maximizes expected information gain on a set of target variables. EDDI is efficient and demonstrates that dynamic discovery of high-value information is possible; we show cost reduction at the same decision quality and improved decision quality at the same cost in benchmarks and in two health-care applications. We believe there is great potential for realizing these gains in real-world decision support systems.
Bayesian nonparametrics for Sparse Dynamic Networks
Jul 06, 2016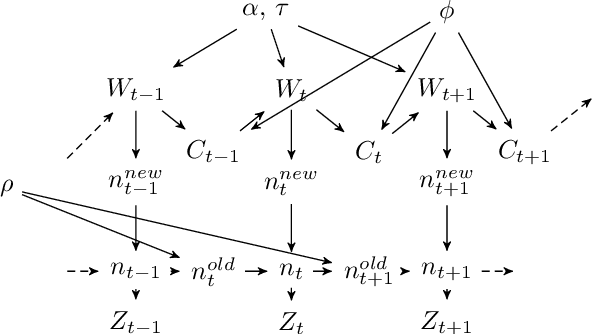
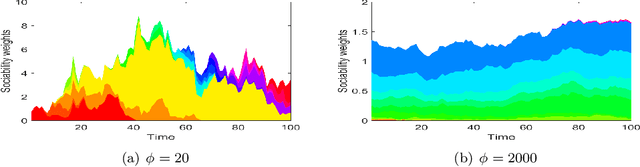
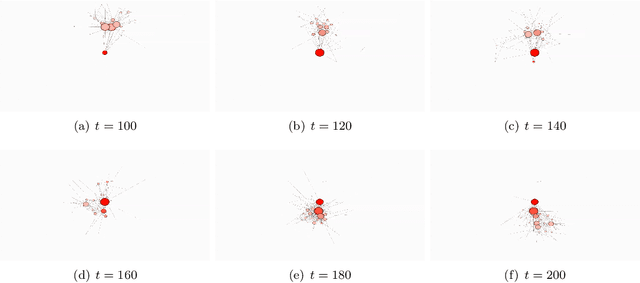

We propose a Bayesian nonparametric prior for time-varying networks. To each node of the network is associated a positive parameter, modeling the sociability of that node. Sociabilities are assumed to evolve over time, and are modeled via a dynamic point process model. The model is able to (a) capture smooth evolution of the interaction between nodes, allowing edges to appear/disappear over time (b) capture long term evolution of the sociabilities of the nodes (c) and yield sparse graphs, where the number of edges grows subquadratically with the number of nodes. The evolution of the sociabilities is described by a tractable time-varying gamma process. We provide some theoretical insights into the model and apply it to three real world datasets.
A reversible infinite HMM using normalised random measures
Mar 17, 2014



We present a nonparametric prior over reversible Markov chains. We use completely random measures, specifically gamma processes, to construct a countably infinite graph with weighted edges. By enforcing symmetry to make the edges undirected we define a prior over random walks on graphs that results in a reversible Markov chain. The resulting prior over infinite transition matrices is closely related to the hierarchical Dirichlet process but enforces reversibility. A reinforcement scheme has recently been proposed with similar properties, but the de Finetti measure is not well characterised. We take the alternative approach of explicitly constructing the mixing measure, which allows more straightforward and efficient inference at the cost of no longer having a closed form predictive distribution. We use our process to construct a reversible infinite HMM which we apply to two real datasets, one from epigenomics and one ion channel recording.
A dependent partition-valued process for multitask clustering and time evolving network modelling
Oct 31, 2013

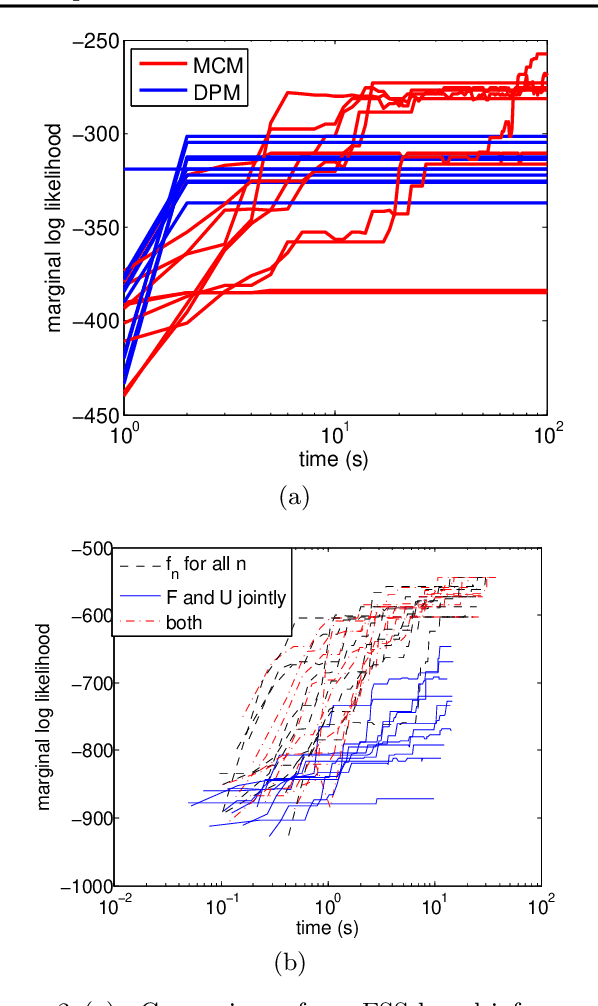

The fundamental aim of clustering algorithms is to partition data points. We consider tasks where the discovered partition is allowed to vary with some covariate such as space or time. One approach would be to use fragmentation-coagulation processes, but these, being Markov processes, are restricted to linear or tree structured covariate spaces. We define a partition-valued process on an arbitrary covariate space using Gaussian processes. We use the process to construct a multitask clustering model which partitions datapoints in a similar way across multiple data sources, and a time series model of network data which allows cluster assignments to vary over time. We describe sampling algorithms for inference and apply our method to defining cancer subtypes based on different types of cellular characteristics, finding regulatory modules from gene expression data from multiple human populations, and discovering time varying community structure in a social network.