 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dependent partition-valued process for multitask clustering and time evolving network modelling
Paper and Code
Oct 31, 2013

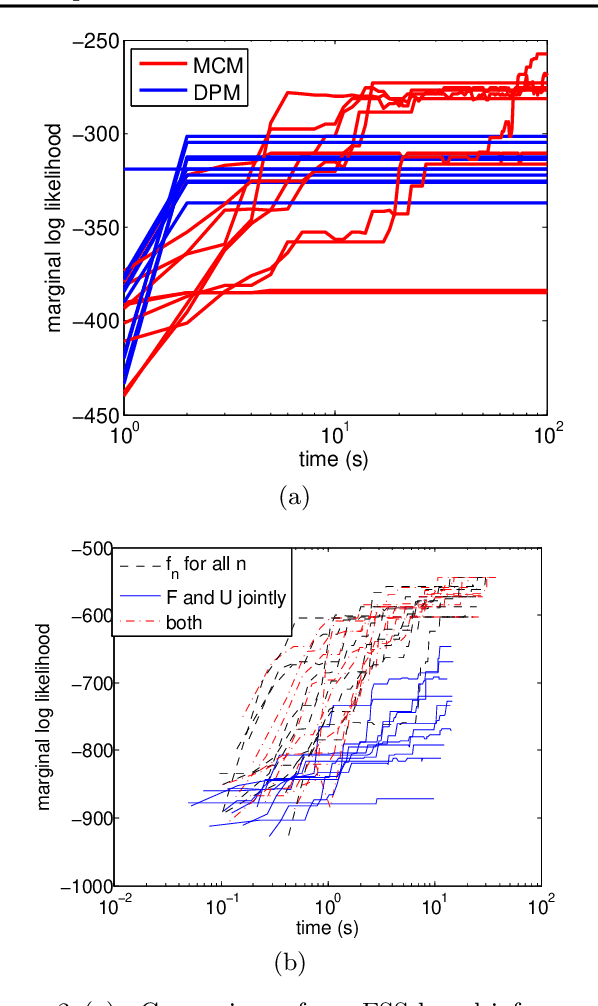

The fundamental aim of clustering algorithms is to partition data points. We consider tasks where the discovered partition is allowed to vary with some covariate such as space or time. One approach would be to use fragmentation-coagulation processes, but these, being Markov processes, are restricted to linear or tree structured covariate spaces. We define a partition-valued process on an arbitrary covariate space using Gaussian processes. We use the process to construct a multitask clustering model which partitions datapoints in a similar way across multiple data sources, and a time series model of network data which allows cluster assignments to vary over time. We describe sampling algorithms for inference and apply our method to defining cancer subtypes based on different types of cellular characteristics, finding regulatory modules from gene expression data from multiple human populations, and discovering time varying community structure in a social network.