 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Faithful Reasoning in Language Models
Oct 25, 2025Chain-of-thought (CoT) traces promise transparency for reasoning language models, but prior work shows they are not always faithful reflections of internal computation. This raises challenges for oversight: practitioners may misinterpret decorative reasoning as genuine. We introduce Concept Walk, a general framework for tracing how a model's internal stance evolves with respect to a concept direction during reasoning. Unlike surface text, Concept Walk operates in activation space, projecting each reasoning step onto the concept direction learned from contrastive data. This allows us to observe whether reasoning traces shape outcomes or are discarded. As a case study, we apply Concept Walk to the domain of Safety using Qwen 3-4B. We find that in 'easy' cases, perturbed CoTs are quickly ignored, indicating decorative reasoning, whereas in 'hard' cases, perturbations induce sustained shifts in internal activations, consistent with faithful reasoning. The contribution is methodological: Concept Walk provides a lens to re-examine faithfulness through concept-specific internal dynamics, helping identify when reasoning traces can be trusted and when they risk misleading practitioners.
Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval
Mar 31, 2025



In recent years, Large Language Models (LLMs) have enabled users to provide highly specific music recommendation requests using natural language prompts (e.g. "Can you recommend some old classics for slow dancing?"). In this setup, the recommended tracks are predicted by the LLM in an autoregressive way, i.e. the LLM generates the track titles one token at a time. While intuitive, this approach has several limitation. First, it is based on a general purpose tokenization that is optimized for words rather than for track titles. Second, it necessitates an additional entity resolution layer that matches the track title to the actual track identifier. Third, the number of decoding steps scales linearly with the length of the track title, slowing down inference. In this paper, we propose to address the task of prompt-based music recommendation as a generative retrieval task. Within this setting, we introduce novel, effective, and efficient representations of track identifiers that significantly outperform commonly used strategies. We introduce Text2Tracks, a generative retrieval model that learns a mapping from a user's music recommendation prompt to the relevant track IDs directly. Through an offline evaluation on a dataset of playlists with language inputs, we find that (1) the strategy to create IDs for music tracks is the most important factor for the effectiveness of Text2Tracks and semantic IDs significantly outperform commonly used strategies that rely on song titles as identifiers (2) provided with the right choice of track identifiers, Text2Tracks outperforms sparse and dense retrieval solutions trained to retrieve tracks from language prompts.
Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models
Feb 25, 2025
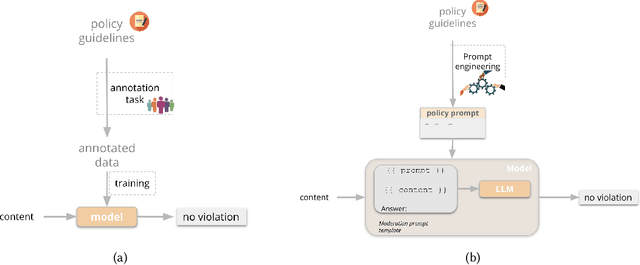

Content moderation plays a critical role in shaping safe and inclusive online environments, balancing platform standards, user expectations, and regulatory frameworks. Traditionally, this process involves operationalising policies into guidelines, which are then used by downstream human moderators for enforcement, or to further annotate datasets for training machine learning moderation models. However, recent advancements in large language models (LLMs) are transforming this landscape. These models can now interpret policies directly as textual inputs, eliminating the need for extensive data curation. This approach offers unprecedented flexibility, as moderation can be dynamically adjusted through natural language interactions. This paradigm shift raises important questions about how policies are operationalised and the implications for content moderation practices. In this paper, we formalise the emerging policy-as-prompt framework and identify five key challenges across four domains: Technical Implementation (1. translating policy to prompts, 2. sensitivity to prompt structure and formatting), Sociotechnical (3. the risk of technological determinism in policy formation), Organisational (4. evolving roles between policy and machine learning teams), and Governance (5. model governance and accountability). Through analysing these challenges across technical, sociotechnical, organisational, and governance dimensions, we discuss potential mitigation approaches. This research provides actionable insights for practitioners and lays the groundwork for future exploration of scalable and adaptive content moderation systems in digital ecosystems.
Harmonizing Global Voices: Culturally-Aware Models for Enhanced Content Moderation
Dec 05, 2023Content moderation at scale faces the challenge of considering local cultural distinctions when assessing content. While global policies aim to maintain decision-making consistency and prevent arbitrary rule enforcement, they often overlook regional variations in interpreting natural language as expressed in content. In this study, we are looking into how moderation systems can tackle this issue by adapting to local comprehension nuances. We train large language models on extensive datasets of media news and articles to create culturally attuned models. The latter aim to capture the nuances of communication across geographies with the goal of recognizing cultural and societal variations in what is considered offensive content. We further explore the capability of these models to generate explanations for instances of content violation, aiming to shed light on how policy guidelines are perceived when cultural and societal contexts change. We find that training on extensive media datasets successfully induced cultural awareness and resulted in improvements in handling content violations on a regional basis. Additionally, these advancements include the ability to provide explanations that align with the specific local norms and nuances as evidenced by the annotators' preference in our conducted study. This multifaceted success reinforces the critical role of an adaptable content moderation approach in keeping pace with the ever-evolving nature of the content it oversees.