 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge
Aug 12, 2025



Evaluating personalized recommendations remains a central challenge, especially in long-form audio domains like podcasts, where traditional offline metrics suffer from exposure bias and online methods such as A/B testing are costly and operationally constrained. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) as offline judges to assess the quality of podcast recommendations in a scalable and interpretable manner. Our two-stage profile-aware approach first constructs natural-language user profiles distilled from 90 days of listening history. These profiles summarize both topical interests and behavioral patterns, serving as compact, interpretable representations of user preferences. Rather than prompting the LLM with raw data, we use these profiles to provide high-level, semantically rich context-enabling the LLM to reason more effectively about alignment between a user's interests and recommended episodes. This reduces input complexity and improves interpretability. The LLM is then prompted to deliver fine-grained pointwise and pairwise judgments based on the profile-episode match. In a controlled study with 47 participants, our profile-aware judge matched human judgments with high fidelity and outperformed or matched a variant using raw listening histories. The framework enables efficient, profile-aware evaluation for iterative testing and model selection in recommender systems.
Contextualizing Spotify's Audiobook List Recommendations with Descriptive Shelves
Apr 18, 2025In this paper, we propose a pipeline to generate contextualized list recommendations with descriptive shelves in the domain of audiobooks. By creating several shelves for topics the user has an affinity to, e.g. Uplifting Women's Fiction, we can help them explore their recommendations according to their interests and at the same time recommend a diverse set of items. To do so, we use Large Language Models (LLMs) to enrich each item's metadata based on a taxonomy created for this domain. Then we create diverse descriptive shelves for each user. A/B tests show improvements in user engagement and audiobook discovery metrics, demonstrating benefits for users and content creators.
Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval
Mar 31, 2025



In recent years, Large Language Models (LLMs) have enabled users to provide highly specific music recommendation requests using natural language prompts (e.g. "Can you recommend some old classics for slow dancing?"). In this setup, the recommended tracks are predicted by the LLM in an autoregressive way, i.e. the LLM generates the track titles one token at a time. While intuitive, this approach has several limitation. First, it is based on a general purpose tokenization that is optimized for words rather than for track titles. Second, it necessitates an additional entity resolution layer that matches the track title to the actual track identifier. Third, the number of decoding steps scales linearly with the length of the track title, slowing down inference. In this paper, we propose to address the task of prompt-based music recommendation as a generative retrieval task. Within this setting, we introduce novel, effective, and efficient representations of track identifiers that significantly outperform commonly used strategies. We introduce Text2Tracks, a generative retrieval model that learns a mapping from a user's music recommendation prompt to the relevant track IDs directly. Through an offline evaluation on a dataset of playlists with language inputs, we find that (1) the strategy to create IDs for music tracks is the most important factor for the effectiveness of Text2Tracks and semantic IDs significantly outperform commonly used strategies that rely on song titles as identifiers (2) provided with the right choice of track identifiers, Text2Tracks outperforms sparse and dense retrieval solutions trained to retrieve tracks from language prompts.
Towards Graph Foundation Models for Personalization
Mar 12, 2024In the realm of personalization, integrating diverse information sources such as consumption signals and content-based representations is becoming increasingly critical to build state-of-the-art solutions. In this regard, two of the biggest trends in research around this subject are Graph Neural Networks (GNNs) and Foundation Models (FMs). While GNNs emerged as a popular solution in industry for powering personalization at scale, FMs have only recently caught attention for their promising performance in personalization tasks like ranking and retrieval. In this paper, we present a graph-based foundation modeling approach tailored to personalization. Central to this approach is a Heterogeneous GNN (HGNN) designed to capture multi-hop content and consumption relationships across a range of recommendable item types. To ensure the generality required from a Foundation Model, we employ a Large Language Model (LLM) text-based featurization of nodes that accommodates all item types, and construct the graph using co-interaction signals, which inherently transcend content specificity. To facilitate practical generalization, we further couple the HGNN with an adaptation mechanism based on a two-tower (2T) architecture, which also operates agnostically to content type. This multi-stage approach ensures high scalability; while the HGNN produces general purpose embeddings, the 2T component models in a continuous space the sheer size of user-item interaction data. Our comprehensive approach has been rigorously tested and proven effective in delivering recommendations across a diverse array of products within a real-world, industrial audio streaming platform.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.
Improving Content Retrievability in Search with Controllable Query Generation
Mar 21, 2023An important goal of online platforms is to enable content discovery, i.e. allow users to find a catalog entity they were not familiar with. A pre-requisite to discover an entity, e.g. a book, with a search engine is that the entity is retrievable, i.e. there are queries for which the system will surface such entity in the top results. However, machine-learned search engines have a high retrievability bias, where the majority of the queries return the same entities. This happens partly due to the predominance of narrow intent queries, where users create queries using the title of an already known entity, e.g. in book search 'harry potter'. The amount of broad queries where users want to discover new entities, e.g. in music search 'chill lyrical electronica with an atmospheric feeling to it', and have a higher tolerance to what they might find, is small in comparison. We focus here on two factors that have a negative impact on the retrievability of the entities (I) the training data used for dense retrieval models and (II) the distribution of narrow and broad intent queries issued in the system. We propose CtrlQGen, a method that generates queries for a chosen underlying intent-narrow or broad. We can use CtrlQGen to improve factor (I) by generating training data for dense retrieval models comprised of diverse synthetic queries. CtrlQGen can also be used to deal with factor (II) by suggesting queries with broader intents to users. Our results on datasets from the domains of music, podcasts, and books reveal that we can significantly decrease the retrievability bias of a dense retrieval model when using CtrlQGen. First, by using the generated queries as training data for dense models we make 9% of the entities retrievable (go from zero to non-zero retrievability). Second, by suggesting broader queries to users, we can make 12% of the entities retrievable in the best case.
Episodes Discovery Recommendation with Multi-Source Augmentations
Jan 17, 2023



Recommender systems (RS) commonly retrieve potential candidate items for users from a massive number of items by modeling user interests based on historical interactions. However, historical interaction data is highly sparse, and most items are long-tail items, which limits the representation learning for item discovery. This problem is further augmented by the discovery of novel or cold-start items. For example, after a user displays interest in bitcoin financial investment shows in the podcast space, a recommender system may want to suggest, e.g., a newly released blockchain episode from a more technical show. Episode correlations help the discovery, especially when interaction data of episodes is limited. Accordingly, we build upon the classical Two-Tower model and introduce the novel Multi-Source Augmentations using a Contrastive Learning framework (MSACL) to enhance episode embedding learning by incorporating positive episodes from numerous correlated semantics. Extensive experiments on a real-world podcast recommendation dataset from a large audio streaming platform demonstrate the effectiveness of the proposed framework for user podcast exploration and cold-start episode recommendation.
Sequential Recommendation via Stochastic Self-Attention
Jan 16, 2022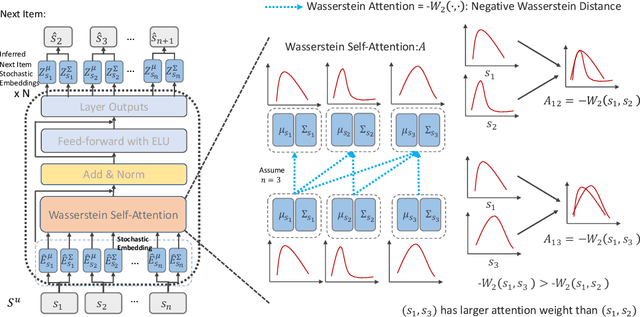
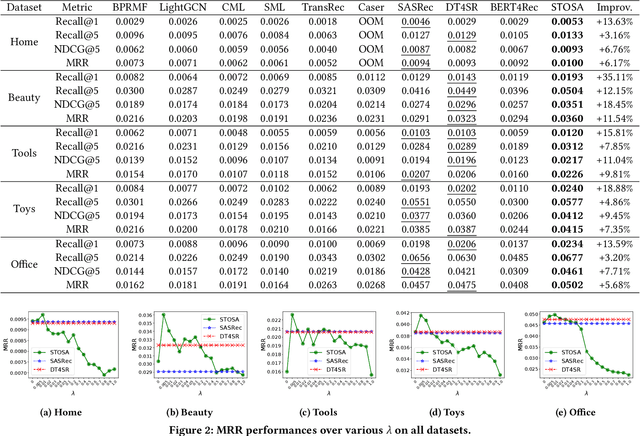

Sequential recommendation models the dynamics of a user's previous behaviors in order to forecast the next item, and has drawn a lot of attention. Transformer-based approaches, which embed items as vectors and use dot-product self-attention to measure the relationship between items, demonstrate superior capabilities among existing sequential methods. However, users' real-world sequential behaviors are \textit{\textbf{uncertain}} rather than deterministic, posing a significant challenge to present techniques. We further suggest that dot-product-based approaches cannot fully capture \textit{\textbf{collaborative transitivity}}, which can be derived in item-item transitions inside sequences and is beneficial for cold start items. We further argue that BPR loss has no constraint on positive and sampled negative items, which misleads the optimization. We propose a novel \textbf{STO}chastic \textbf{S}elf-\textbf{A}ttention~(STOSA) to overcome these issues. STOSA, in particular, embeds each item as a stochastic Gaussian distribution, the covariance of which encodes the uncertainty. We devise a novel Wasserstein Self-Attention module to characterize item-item position-wise relationships in sequences, which effectively incorporates uncertainty into model training. Wasserstein attentions also enlighten the collaborative transitivity learning as it satisfies triangle inequality. Moreover, we introduce a novel regularization term to the ranking loss, which assures the dissimilarity between positive and the negative items. Extensive experiments on five real-world benchmark datasets demonstrate the superiority of the proposed model over state-of-the-art baselines, especially on cold start items. The code is available in \url{https://github.com/zfan20/STOSA}.
Trajectory Based Podcast Recommendation
Sep 08, 2020
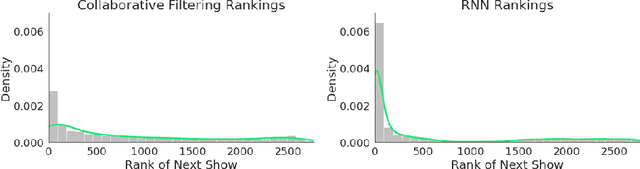

Podcast recommendation is a growing area of research that presents new challenges and opportunities. Individuals interact with podcasts in a way that is distinct from most other media; and primary to our concerns is distinct from music consumption. We show that successful and consistent recommendations can be made by viewing users as moving through the podcast library sequentially. Recommendations for future podcasts are then made using the trajectory taken from their sequential behavior. Our experiments provide evidence that user behavior is confined to local trends, and that listening patterns tend to be found over short sequences of similar types of shows. Ultimately, our approach gives a450%increase in effectiveness over a collaborative filtering baseline.