 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
Generalized User Representations for Transfer Learning
Mar 01, 2024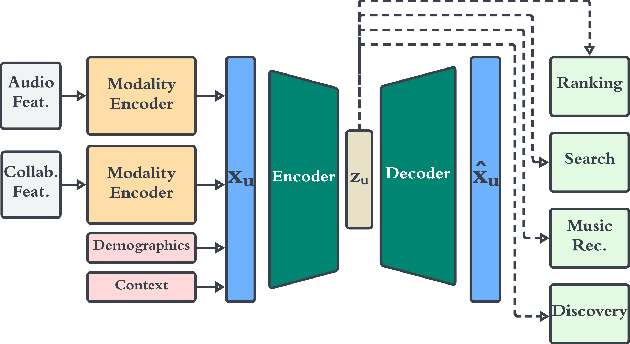

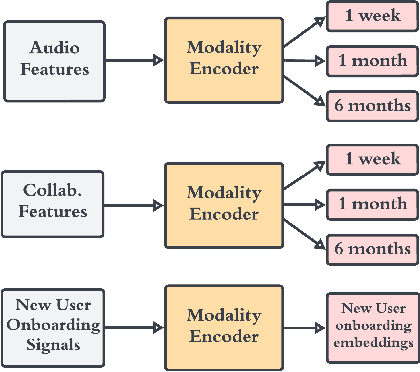
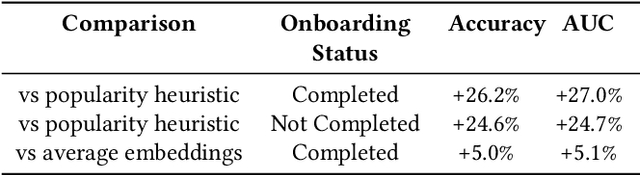
We present a novel framework for user representation in large-scale recommender systems, aiming at effectively representing diverse user taste in a generalized manner. Our approach employs a two-stage methodology combining representation learning and transfer learning. The representation learning model uses an autoencoder that compresses various user features into a representation space. In the second stage, downstream task-specific models leverage user representations via transfer learning instead of curating user features individually. We further augment this methodology on the representation's input features to increase flexibility and enable reaction to user events, including new user experiences, in Near-Real Time. Additionally, we propose a novel solution to manage deployment of this framework in production models, allowing downstream models to work independently. We validate the performance of our framework through rigorous offline and online experiments within a large-scale system, showcasing its remarkable efficacy across multiple evaluation tasks. Finally, we show how the proposed framework can significantly reduce infrastructure costs compared to alternative approaches.
Model Selection for Production System via Automated Online Experiments
May 27, 2021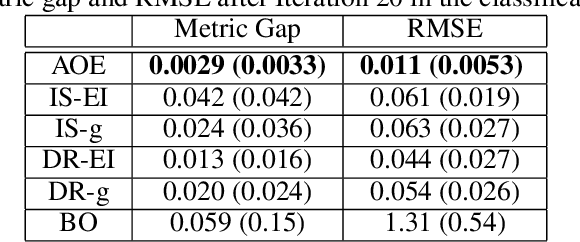
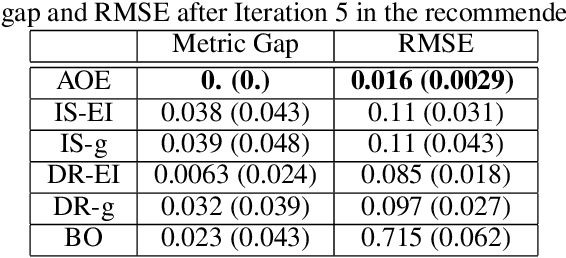
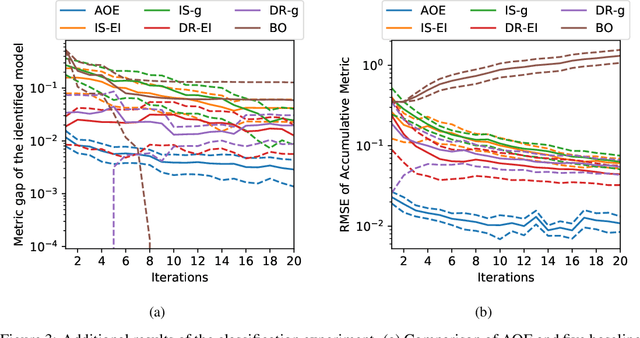
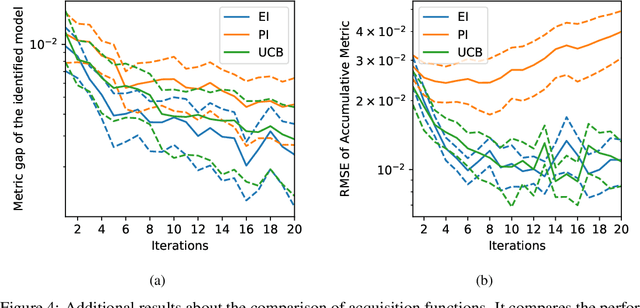
A challenge that machine learning practitioners in the industry face is the task of selecting the best model to deploy in production. As a model is often an intermediate component of a production system, online controlled experiments such as A/B tests yield the most reliable estimation of the effectiveness of the whole system, but can only compare two or a few models due to budget constraints. We propose an automated online experimentation mechanism that can efficiently perform model selection from a large pool of models with a small number of online experiments. We derive the probability distribution of the metric of interest that contains the model uncertainty from our Bayesian surrogate model trained using historical logs. Our method efficiently identifies the best model by sequentially selecting and deploying a list of models from the candidate set that balance exploration-exploitation. Using simulations based on real data, we demonstrate the effectiveness of our method on two different tasks.
Trajectory Based Podcast Recommendation
Sep 08, 2020
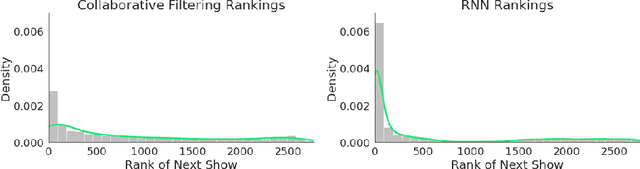

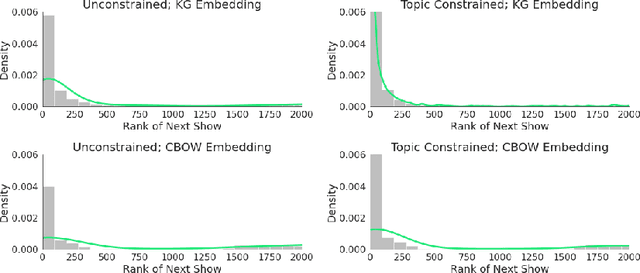
Podcast recommendation is a growing area of research that presents new challenges and opportunities. Individuals interact with podcasts in a way that is distinct from most other media; and primary to our concerns is distinct from music consumption. We show that successful and consistent recommendations can be made by viewing users as moving through the podcast library sequentially. Recommendations for future podcasts are then made using the trajectory taken from their sequential behavior. Our experiments provide evidence that user behavior is confined to local trends, and that listening patterns tend to be found over short sequences of similar types of shows. Ultimately, our approach gives a450%increase in effectiveness over a collaborative filtering baseline.
Mixed Membership Recurrent Neural Networks
Dec 23, 2018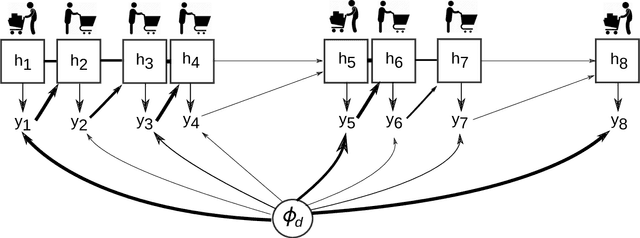
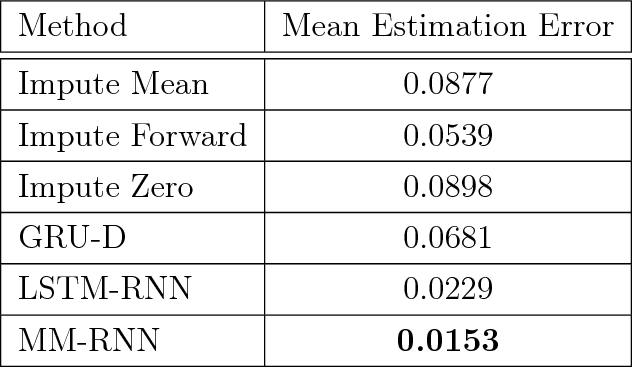
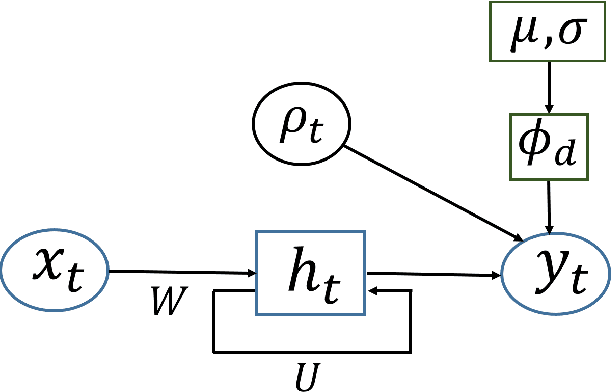
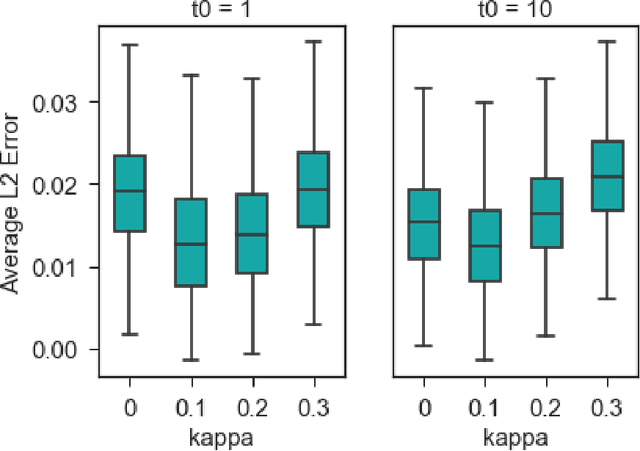
Models for sequential data such as the recurrent neural network (RNN) often implicitly model a sequence as having a fixed time interval between observations and do not account for group-level effects when multiple sequences are observed. We propose a model for grouped sequential data based on the RNN that accounts for varying time intervals between observations in a sequence by learning a group-level base parameter to which each sequence can revert. Our approach is motivated by the mixed membership framework, and we show how it can be used for dynamic topic modeling in which the distribution on topics (not the topics themselves) are evolving in time. We demonstrate our approach on a dataset of 3.4 million online grocery shopping orders made by 206K customers.