 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Forget Its Variance! The Minimum Path Variance Principle for Accurate and Stable Score-Based Density Ratio Estimation
Jan 31, 2026Score-based methods have emerged as a powerful framework for density ratio estimation (DRE), but they face an important paradox in that, while theoretically path-independent, their practical performance depends critically on the chosen path schedule. We resolve this issue by proving that tractable training objectives differ from the ideal, ground-truth objective by a crucial, overlooked term: the path variance of the time score. To address this, we propose MinPV (\textbf{Min}imum \textbf{P}ath \textbf{V}ariance) Principle, which introduces a principled heuristic to minimize the overlooked path variance. Our key contribution is the derivation of a closed-form expression for the variance, turning an intractable problem into a tractable optimization. By parameterizing the path with a flexible Kumaraswamy Mixture Model, our method learns a data-adaptive, low-variance path without heuristic selection. This principled optimization of the complete objective yields more accurate and stable estimators, establishing new state-of-the-art results on challenging benchmarks.
Any-Step Density Ratio Estimation via Interval-Annealed Secant Alignment
Sep 05, 2025
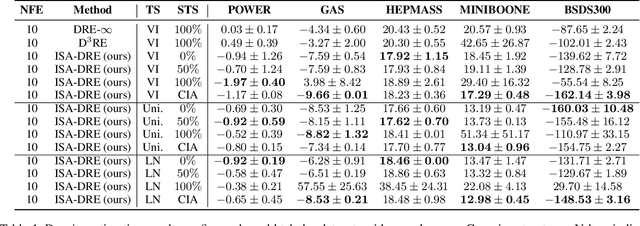
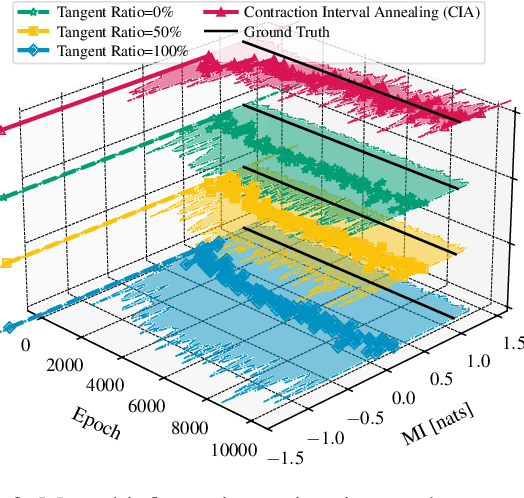
Estimating density ratios is a fundamental problem in machine learning, but existing methods often trade off accuracy for efficiency. We propose \textit{Interval-annealed Secant Alignment Density Ratio Estimation (ISA-DRE)}, a framework that enables accurate, any-step estimation without numerical integration. Instead of modeling infinitesimal tangents as in prior methods, ISA-DRE learns a global secant function, defined as the expectation of all tangents over an interval, with provably lower variance, making it more suitable for neural approximation. This is made possible by the \emph{Secant Alignment Identity}, a self-consistency condition that formally connects the secant with its underlying tangent representations. To mitigate instability during early training, we introduce \emph{Contraction Interval Annealing}, a curriculum strategy that gradually expands the alignment interval during training. This process induces a contraction mapping, which improves convergence and training stability. Empirically, ISA-DRE achieves competitive accuracy with significantly fewer function evaluations compared to prior methods, resulting in much faster inference and making it well suited for real-time and interactive applications.
Neural Bridge Processes
Aug 10, 2025Learning stochastic functions from partially observed context-target pairs is a fundamental problem in probabilistic modeling. Traditional models like Gaussian Processes (GPs) face scalability issues with large datasets and assume Gaussianity, limiting their applicability. While Neural Processes (NPs) offer more flexibility, they struggle with capturing complex, multi-modal target distributions. Neural Diffusion Processes (NDPs) enhance expressivity through a learned diffusion process but rely solely on conditional signals in the denoising network, resulting in weak input coupling from an unconditional forward process and semantic mismatch at the diffusion endpoint. In this work, we propose Neural Bridge Processes (NBPs), a novel method for modeling stochastic functions where inputs x act as dynamic anchors for the entire diffusion trajectory. By reformulating the forward kernel to explicitly depend on x, NBP enforces a constrained path that strictly terminates at the supervised target. This approach not only provides stronger gradient signals but also guarantees endpoint coherence. We validate NBPs on synthetic data, EEG signal regression and image regression tasks, achieving substantial improvements over baselines. These results underscore the effectiveness of DDPM-style bridge sampling in enhancing both performance and theoretical consistency for structured prediction tasks.
Dequantified Diffusion Schrödinger Bridge for Density Ratio Estimation
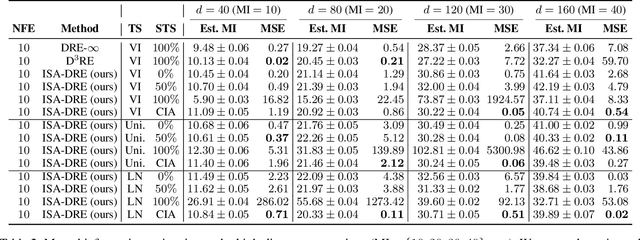
May 08, 2025Density ratio estimation is fundamental to tasks involving $f$-divergences, yet existing methods often fail under significantly different distributions or inadequately overlap supports, suffering from the \textit{density-chasm} and the \textit{support-chasm} problems. Additionally, prior approaches yield divergent time scores near boundaries, leading to instability. We propose $\text{D}^3\text{RE}$, a unified framework for robust and efficient density ratio estimation. It introduces the Dequantified Diffusion-Bridge Interpolant (DDBI), which expands support coverage and stabilizes time scores via diffusion bridges and Gaussian dequantization. Building on DDBI, the Dequantified Schr\"odinger-Bridge Interpolant (DSBI) incorporates optimal transport to solve the Schr\"odinger bridge problem, enhancing accuracy and efficiency. Our method offers uniform approximation and bounded time scores in theory, and outperforms baselines empirically in mutual information and density estimation tasks.
Gaussian Process Tilted Nonparametric Density Estimation using Fisher Divergence Score Matching
Apr 04, 2025We present three Fisher divergence (FD) minimization algorithms for learning Gaussian process (GP) based score models for lower dimensional density estimation problems. The density is formed by multiplying a base multivariate normal distribution with an exponentiated GP refinement, and so we refer to it as a GP-tilted nonparametric density. By representing the GP part of the score as a linear function using the random Fourier feature (RFF) approximation, we show that all learning problems can be solved in closed form. This includes the basic and noise conditional versions of the Fisher divergence, as well as a novel alternative to noise conditional FD models based on variational inference (VI). Here, we propose using an ELBO-like optimization of the approximate posterior with which we derive a Fisher variational predictive distribution. The RFF representation of the GP, which is functionally equivalent to a single layer neural network score model with cosine activation, provides a unique linear form for which all expectations are in closed form. The Gaussian base also helps with tractability of the VI approximation. We demonstrate our three learning algorithms, as well as a MAP baseline algorithm, on several low dimensional density estimation problems. The closed-form nature of the learning problem removes the reliance on iterative algorithms, making this technique particularly well-suited to large data sets.
Information Geometry and Beta Link for Optimizing Sparse Variational Student-t Processes
Aug 13, 2024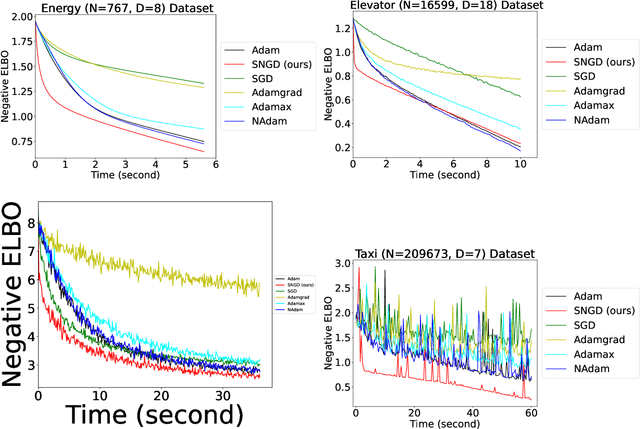
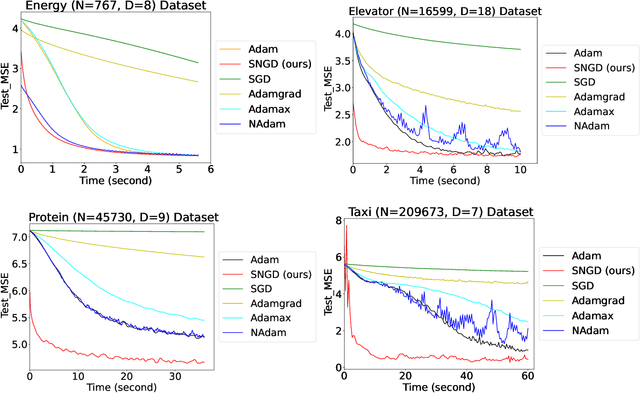
Recently, a sparse version of Student-t Processes, termed sparse variational Student-t Processes, has been proposed to enhance computational efficiency and flexibility for real-world datasets using stochastic gradient descent. However, traditional gradient descent methods like Adam may not fully exploit the parameter space geometry, potentially leading to slower convergence and suboptimal performance. To mitigate these issues, we adopt natural gradient methods from information geometry for variational parameter optimization of Student-t Processes. This approach leverages the curvature and structure of the parameter space, utilizing tools such as the Fisher information matrix which is linked to the Beta function in our model. This method provides robust mathematical support for the natural gradient algorithm when using Student's t-distribution as the variational distribution. Additionally, we present a mini-batch algorithm for efficiently computing natural gradients. Experimental results across four benchmark datasets demonstrate that our method consistently accelerates convergence speed.
Fully Bayesian Differential Gaussian Processes through Stochastic Differential Equations
Aug 12, 2024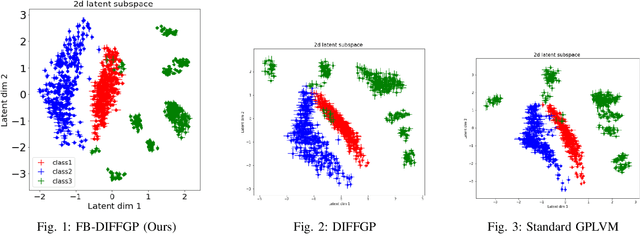

Traditional deep Gaussian processes model the data evolution using a discrete hierarchy, whereas differential Gaussian processes (DIFFGPs) represent the evolution as an infinitely deep Gaussian process. However, prior DIFFGP methods often overlook the uncertainty of kernel hyperparameters and assume them to be fixed and time-invariant, failing to leverage the unique synergy between continuous-time models and approximate inference. In this work, we propose a fully Bayesian approach that treats the kernel hyperparameters as random variables and constructs coupled stochastic differential equations (SDEs) to learn their posterior distribution and that of inducing points. By incorporating estimation uncertainty on hyperparameters, our method enhances the model's flexibility and adaptability to complex dynamics. Additionally, our approach provides a time-varying, comprehensive, and realistic posterior approximation through coupling variables using SDE methods. Experimental results demonstrate the advantages of our method over traditional approaches, showcasing its superior performance in terms of flexibility, accuracy, and other metrics. Our work opens up exciting research avenues for advancing Bayesian inference and offers a powerful modeling tool for continuous-time Gaussian processes.
Flexible Bayesian Last Layer Models Using Implicit Priors and Diffusion Posterior Sampling
Aug 07, 2024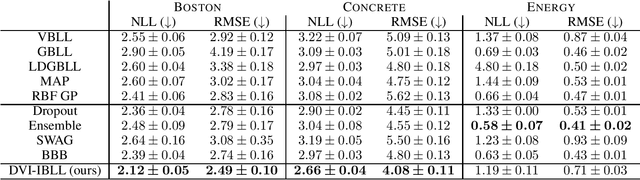
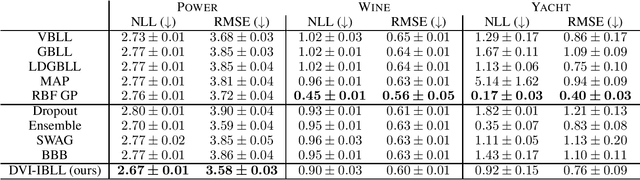
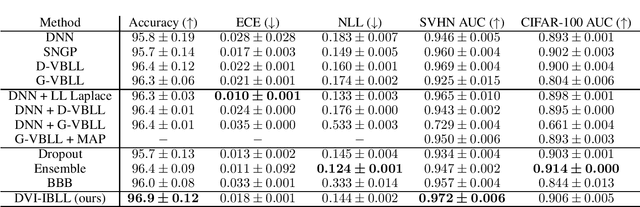
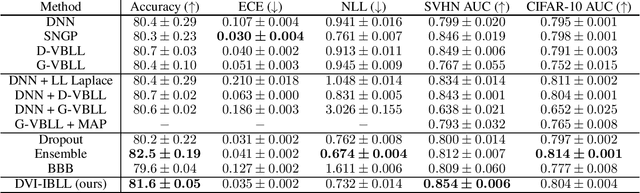
Bayesian Last Layer (BLL) models focus solely on uncertainty in the output layer of neural networks, demonstrating comparable performance to more complex Bayesian models. However, the use of Gaussian priors for last layer weights in Bayesian Last Layer (BLL) models limits their expressive capacity when faced with non-Gaussian, outlier-rich, or high-dimensional datasets. To address this shortfall, we introduce a novel approach that combines diffusion techniques and implicit priors for variational learning of Bayesian last layer weights. This method leverages implicit distributions for modeling weight priors in BLL, coupled with diffusion samplers for approximating true posterior predictions, thereby establishing a comprehensive Bayesian prior and posterior estimation strategy. By delivering an explicit and computationally efficient variational lower bound, our method aims to augment the expressive abilities of BLL models, enhancing model accuracy, calibration, and out-of-distribution detection proficiency. Through detailed exploration and experimental validation, We showcase the method's potential for improving predictive accuracy and uncertainty quantification while ensuring computational efficiency.
Sparse Inducing Points in Deep Gaussian Processes: Enhancing Modeling with Denoising Diffusion Variational Inference
Jul 24, 2024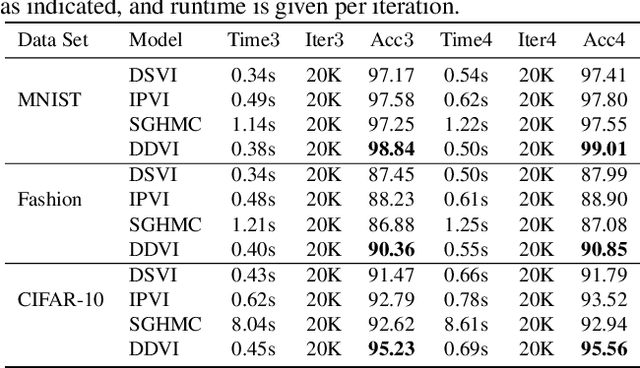
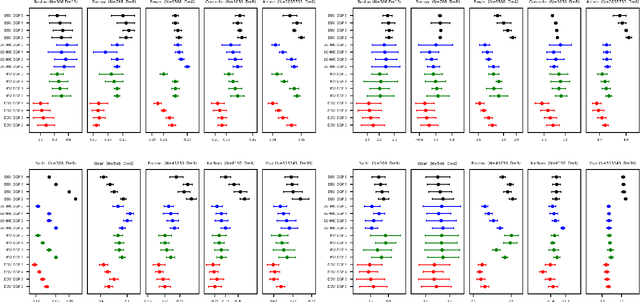
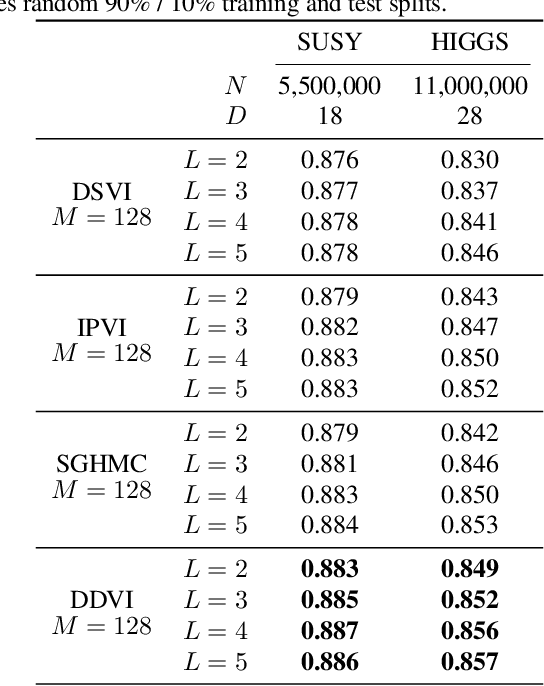

Deep Gaussian processes (DGPs) provide a robust paradigm for Bayesian deep learning. In DGPs, a set of sparse integration locations called inducing points are selected to approximate the posterior distribution of the model. This is done to reduce computational complexity and improve model efficiency. However, inferring the posterior distribution of inducing points is not straightforward. Traditional variational inference approaches to posterior approximation often lead to significant bias. To address this issue, we propose an alternative method called Denoising Diffusion Variational Inference (DDVI) that uses a denoising diffusion stochastic differential equation (SDE) to generate posterior samples of inducing variables. We rely on score matching methods for denoising diffusion model to approximate score functions with a neural network. Furthermore, by combining classical mathematical theory of SDEs with the minimization of KL divergence between the approximate and true processes, we propose a novel explicit variational lower bound for the marginal likelihood function of DGP. Through experiments on various datasets and comparisons with baseline methods, we empirically demonstrate the effectiveness of DDVI for posterior inference of inducing points for DGP models.
Entropy-Informed Weighting Channel Normalizing Flow
Jul 06, 2024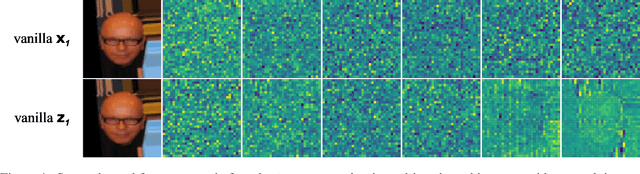
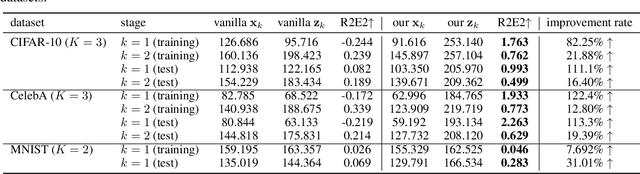
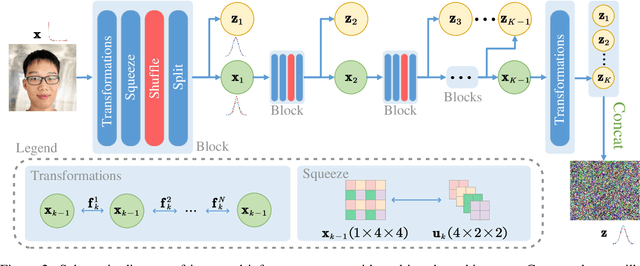
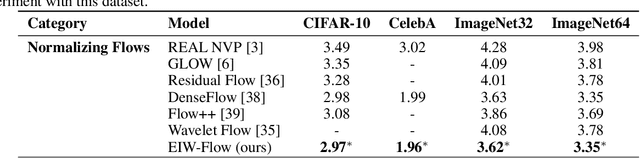
Normalizing Flows (NFs) have gained popularity among deep generative models due to their ability to provide exact likelihood estimation and efficient sampling. However, a crucial limitation of NFs is their substantial memory requirements, arising from maintaining the dimension of the latent space equal to that of the input space. Multi-scale architectures bypass this limitation by progressively reducing the dimension of latent variables while ensuring reversibility. Existing multi-scale architectures split the latent variables in a simple, static manner at the channel level, compromising NFs' expressive power. To address this issue, we propose a regularized and feature-dependent $\mathtt{Shuffle}$ operation and integrate it into vanilla multi-scale architecture. This operation heuristically generates channel-wise weights and adaptively shuffles latent variables before splitting them with these weights. We observe that such operation guides the variables to evolve in the direction of entropy increase, hence we refer to NFs with the $\mathtt{Shuffle}$ operation as \emph{Entropy-Informed Weighting Channel Normalizing Flow} (EIW-Flow). Experimental results indicate that the EIW-Flow achieves state-of-the-art density estimation results and comparable sample quality on CIFAR-10, CelebA and ImageNet datasets, with negligible additional computational overhead.