 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
Evaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge
Aug 12, 2025



Evaluating personalized recommendations remains a central challenge, especially in long-form audio domains like podcasts, where traditional offline metrics suffer from exposure bias and online methods such as A/B testing are costly and operationally constrained. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) as offline judges to assess the quality of podcast recommendations in a scalable and interpretable manner. Our two-stage profile-aware approach first constructs natural-language user profiles distilled from 90 days of listening history. These profiles summarize both topical interests and behavioral patterns, serving as compact, interpretable representations of user preferences. Rather than prompting the LLM with raw data, we use these profiles to provide high-level, semantically rich context-enabling the LLM to reason more effectively about alignment between a user's interests and recommended episodes. This reduces input complexity and improves interpretability. The LLM is then prompted to deliver fine-grained pointwise and pairwise judgments based on the profile-episode match. In a controlled study with 47 participants, our profile-aware judge matched human judgments with high fidelity and outperformed or matched a variant using raw listening histories. The framework enables efficient, profile-aware evaluation for iterative testing and model selection in recommender systems.
Graph-Convolution-Beta-VAE for Synthetic Abdominal Aorta Aneurysm Generation
Jun 16, 2025

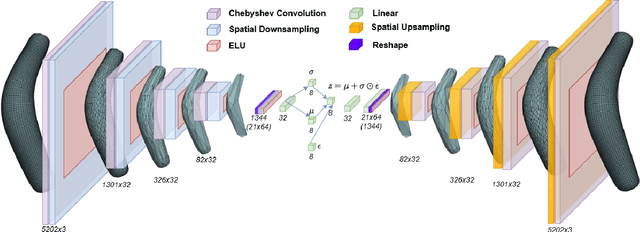

Synthetic data generation plays a crucial role in medical research by mitigating privacy concerns and enabling large-scale patient data analysis. This study presents a beta-Variational Autoencoder Graph Convolutional Neural Network framework for generating synthetic Abdominal Aorta Aneurysms (AAA). Using a small real-world dataset, our approach extracts key anatomical features and captures complex statistical relationships within a compact disentangled latent space. To address data limitations, low-impact data augmentation based on Procrustes analysis was employed, preserving anatomical integrity. The generation strategies, both deterministic and stochastic, manage to enhance data diversity while ensuring realism. Compared to PCA-based approaches, our model performs more robustly on unseen data by capturing complex, nonlinear anatomical variations. This enables more comprehensive clinical and statistical analyses than the original dataset alone. The resulting synthetic AAA dataset preserves patient privacy while providing a scalable foundation for medical research, device testing, and computational modeling.
Policy-as-Prompt: Rethinking Content Moderation in the Age of Large Language Models
Feb 25, 2025
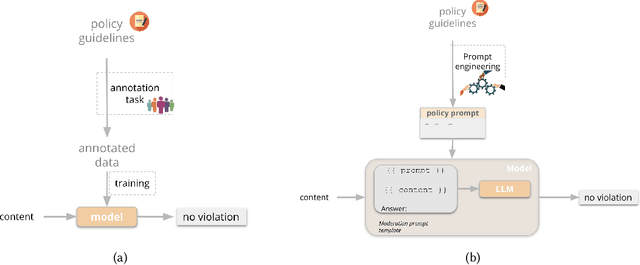

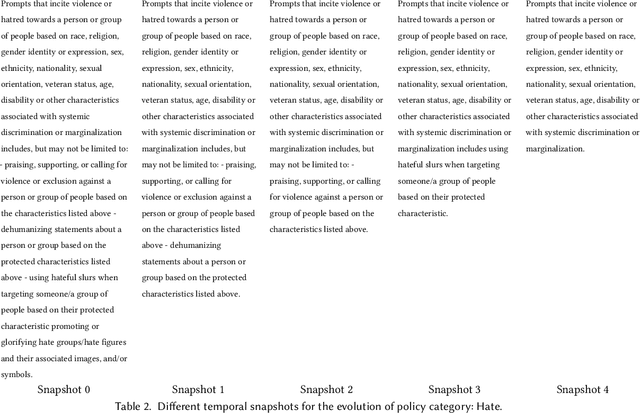
Content moderation plays a critical role in shaping safe and inclusive online environments, balancing platform standards, user expectations, and regulatory frameworks. Traditionally, this process involves operationalising policies into guidelines, which are then used by downstream human moderators for enforcement, or to further annotate datasets for training machine learning moderation models. However, recent advancements in large language models (LLMs) are transforming this landscape. These models can now interpret policies directly as textual inputs, eliminating the need for extensive data curation. This approach offers unprecedented flexibility, as moderation can be dynamically adjusted through natural language interactions. This paradigm shift raises important questions about how policies are operationalised and the implications for content moderation practices. In this paper, we formalise the emerging policy-as-prompt framework and identify five key challenges across four domains: Technical Implementation (1. translating policy to prompts, 2. sensitivity to prompt structure and formatting), Sociotechnical (3. the risk of technological determinism in policy formation), Organisational (4. evolving roles between policy and machine learning teams), and Governance (5. model governance and accountability). Through analysing these challenges across technical, sociotechnical, organisational, and governance dimensions, we discuss potential mitigation approaches. This research provides actionable insights for practitioners and lays the groundwork for future exploration of scalable and adaptive content moderation systems in digital ecosystems.
IOHunter: Graph Foundation Model to Uncover Online Information Operations
Dec 19, 2024



Social media platforms have become vital spaces for public discourse, serving as modern agor\'as where a wide range of voices influence societal narratives. However, their open nature also makes them vulnerable to exploitation by malicious actors, including state-sponsored entities, who can conduct information operations (IOs) to manipulate public opinion. The spread of misinformation, false news, and misleading claims threatens democratic processes and societal cohesion, making it crucial to develop methods for the timely detection of inauthentic activity to protect the integrity of online discourse. In this work, we introduce a methodology designed to identify users orchestrating information operations, a.k.a. \textit{IO drivers}, across various influence campaigns. Our framework, named \texttt{IOHunter}, leverages the combined strengths of Language Models and Graph Neural Networks to improve generalization in \emph{supervised}, \emph{scarcely-supervised}, and \emph{cross-IO} contexts. Our approach achieves state-of-the-art performance across multiple sets of IOs originating from six countries, significantly surpassing existing approaches. This research marks a step toward developing Graph Foundation Models specifically tailored for the task of IO detection on social media platforms.
Algorithmic Drift: A Simulation Framework to Study the Effects of Recommender Systems on User Preferences
Sep 24, 2024



Digital platforms such as social media and e-commerce websites adopt Recommender Systems to provide value to the user. However, the social consequences deriving from their adoption are still unclear. Many scholars argue that recommenders may lead to detrimental effects, such as bias-amplification deriving from the feedback loop between algorithmic suggestions and users' choices. Nonetheless, the extent to which recommenders influence changes in users leaning remains uncertain. In this context, it is important to provide a controlled environment for evaluating the recommendation algorithm before deployment. To address this, we propose a stochastic simulation framework that mimics user-recommender system interactions in a long-term scenario. In particular, we simulate the user choices by formalizing a user model, which comprises behavioral aspects, such as the user resistance towards the recommendation algorithm and their inertia in relying on the received suggestions. Additionally, we introduce two novel metrics for quantifying the algorithm's impact on user preferences, specifically in terms of drift over time. We conduct an extensive evaluation on multiple synthetic datasets, aiming at testing the robustness of our framework when considering different scenarios and hyper-parameters setting. The experimental results prove that the proposed methodology is effective in detecting and quantifying the drift over the users preferences by means of the simulation. All the code and data used to perform the experiments are publicly available.
Fair Augmentation for Graph Collaborative Filtering
Aug 22, 2024
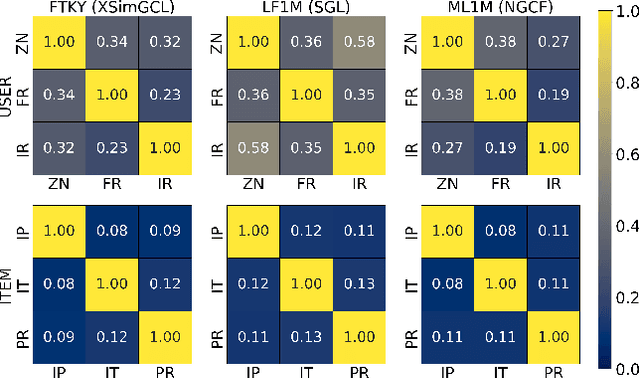


Recent developments in recommendation have harnessed the collaborative power of graph neural networks (GNNs) in learning users' preferences from user-item networks. Despite emerging regulations addressing fairness of automated systems, unfairness issues in graph collaborative filtering remain underexplored, especially from the consumer's perspective. Despite numerous contributions on consumer unfairness, only a few of these works have delved into GNNs. A notable gap exists in the formalization of the latest mitigation algorithms, as well as in their effectiveness and reliability on cutting-edge models. This paper serves as a solid response to recent research highlighting unfairness issues in graph collaborative filtering by reproducing one of the latest mitigation methods. The reproduced technique adjusts the system fairness level by learning a fair graph augmentation. Under an experimental setup based on 11 GNNs, 5 non-GNN models, and 5 real-world networks across diverse domains, our investigation reveals that fair graph augmentation is consistently effective on high-utility models and large datasets. Experiments on the transferability of the fair augmented graph open new issues for future recommendation studies. Source code: https://github.com/jackmedda/FA4GCF.
Diffusion Model for Slate Recommendation
Aug 13, 2024



Slate recommendation is a technique commonly used on streaming platforms and e-commerce sites to present multiple items together. A significant challenge with slate recommendation is managing the complex combinatorial choice space. Traditional methods often simplify this problem by assuming users engage with only one item at a time. However, this simplification does not reflect the reality, as users often interact with multiple items simultaneously. In this paper, we address the general slate recommendation problem, which accounts for simultaneous engagement with multiple items. We propose a generative approach using Diffusion Models, leveraging their ability to learn structures in high-dimensional data. Our model generates high-quality slates that maximize user satisfaction by overcoming the challenges of the combinatorial choice space. Furthermore, our approach enhances the diversity of recommendations. Extensive offline evaluations on applications such as music playlist generation and e-commerce bundle recommendations show that our model outperforms state-of-the-art baselines in both relevance and diversity.
Towards Graph Foundation Models for Personalization
Mar 12, 2024In the realm of personalization, integrating diverse information sources such as consumption signals and content-based representations is becoming increasingly critical to build state-of-the-art solutions. In this regard, two of the biggest trends in research around this subject are Graph Neural Networks (GNNs) and Foundation Models (FMs). While GNNs emerged as a popular solution in industry for powering personalization at scale, FMs have only recently caught attention for their promising performance in personalization tasks like ranking and retrieval. In this paper, we present a graph-based foundation modeling approach tailored to personalization. Central to this approach is a Heterogeneous GNN (HGNN) designed to capture multi-hop content and consumption relationships across a range of recommendable item types. To ensure the generality required from a Foundation Model, we employ a Large Language Model (LLM) text-based featurization of nodes that accommodates all item types, and construct the graph using co-interaction signals, which inherently transcend content specificity. To facilitate practical generalization, we further couple the HGNN with an adaptation mechanism based on a two-tower (2T) architecture, which also operates agnostically to content type. This multi-stage approach ensures high scalability; while the HGNN produces general purpose embeddings, the 2T component models in a continuous space the sheer size of user-item interaction data. Our comprehensive approach has been rigorously tested and proven effective in delivering recommendations across a diverse array of products within a real-world, industrial audio streaming platform.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Mar 08, 2024In the ever-evolving digital audio landscape, Spotify, well-known for its music and talk content, has recently introduced audiobooks to its vast user base. While promising, this move presents significant challenges for personalized recommendations. Unlike music and podcasts, audiobooks, initially available for a fee, cannot be easily skimmed before purchase, posing higher stakes for the relevance of recommendations. Furthermore, introducing a new content type into an existing platform confronts extreme data sparsity, as most users are unfamiliar with this new content type. Lastly, recommending content to millions of users requires the model to react fast and be scalable. To address these challenges, we leverage podcast and music user preferences and introduce 2T-HGNN, a scalable recommendation system comprising Heterogeneous Graph Neural Networks (HGNNs) and a Two Tower (2T) model. This novel approach uncovers nuanced item relationships while ensuring low latency and complexity. We decouple users from the HGNN graph and propose an innovative multi-link neighbor sampler. These choices, together with the 2T component, significantly reduce the complexity of the HGNN model. Empirical evaluations involving millions of users show significant improvement in the quality of personalized recommendations, resulting in a +46% increase in new audiobooks start rate and a +23% boost in streaming rates. Intriguingly, our model's impact extends beyond audiobooks, benefiting established products like podcasts.