 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Deception: Color Visual Illusions and Diffusion Models
Dec 13, 2024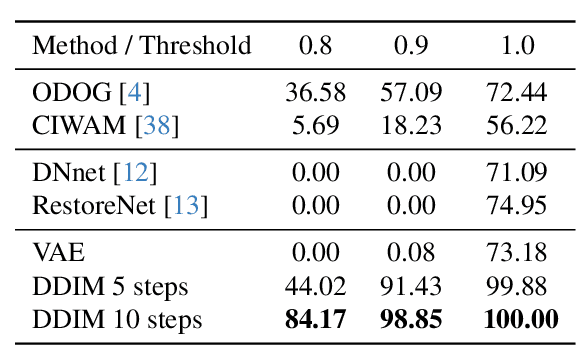
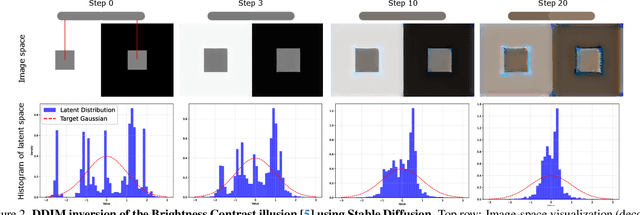
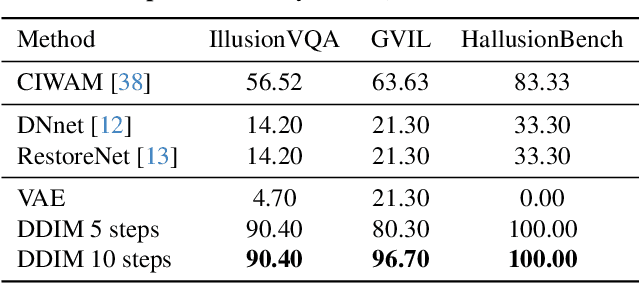
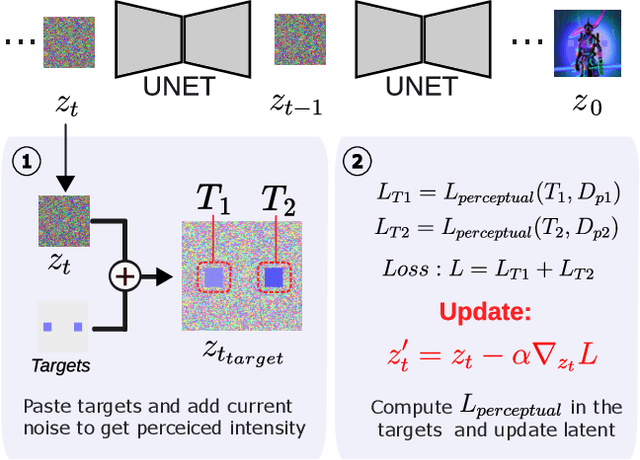
Visual illusions in humans arise when interpreting out-of-distribution stimuli: if the observer is adapted to certain statistics, perception of outliers deviates from reality. Recent studies have shown that artificial neural networks (ANNs) can also be deceived by visual illusions. This revelation raises profound questions about the nature of visual information. Why are two independent systems, both human brains and ANNs, susceptible to the same illusions? Should any ANN be capable of perceiving visual illusions? Are these perceptions a feature or a flaw? In this work, we study how visual illusions are encoded in diffusion models. Remarkably, we show that they present human-like brightness/color shifts in their latent space. We use this fact to demonstrate that diffusion models can predict visual illusions. Furthermore, we also show how to generate new unseen visual illusions in realistic images using text-to-image diffusion models. We validate this ability through psychophysical experiments that show how our model-generated illusions also fool humans.
Exemplar-free Continual Representation Learning via Learnable Drift Compensation
Jul 11, 2024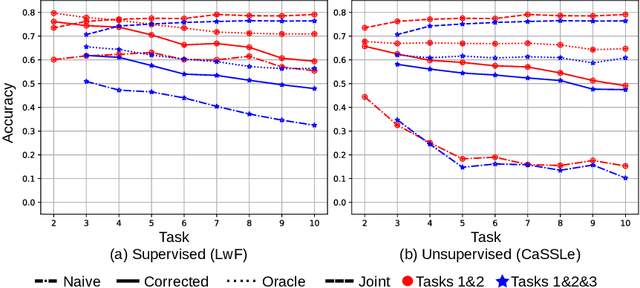
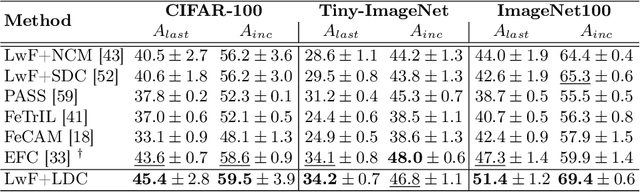

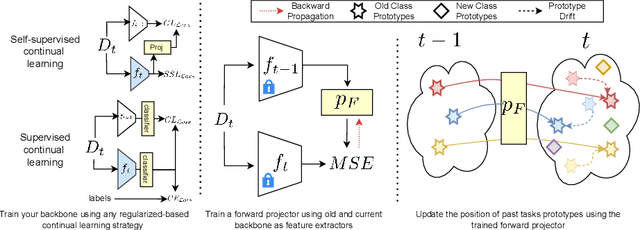
Exemplar-free class-incremental learning using a backbone trained from scratch and starting from a small first task presents a significant challenge for continual representation learning. Prototype-based approaches, when continually updated, face the critical issue of semantic drift due to which the old class prototypes drift to different positions in the new feature space. Through an analysis of prototype-based continual learning, we show that forgetting is not due to diminished discriminative power of the feature extractor, and can potentially be corrected by drift compensation. To address this, we propose Learnable Drift Compensation (LDC), which can effectively mitigate drift in any moving backbone, whether supervised or unsupervised. LDC is fast and straightforward to integrate on top of existing continual learning approaches. Furthermore, we showcase how LDC can be applied in combination with self-supervised CL methods, resulting in the first exemplar-free semi-supervised continual learning approach. We achieve state-of-the-art performance in both supervised and semi-supervised settings across multiple datasets. Code is available at \url{https://github.com/alviur/ldc}.
FedFNN: Faster Training Convergence Through Update Predictions in Federated Recommender Systems
Sep 14, 2023



Federated Learning (FL) has emerged as a key approach for distributed machine learning, enhancing online personalization while ensuring user data privacy. Instead of sending private data to a central server as in traditional approaches, FL decentralizes computations: devices train locally and share updates with a global server. A primary challenge in this setting is achieving fast and accurate model training - vital for recommendation systems where delays can compromise user engagement. This paper introduces FedFNN, an algorithm that accelerates decentralized model training. In FL, only a subset of users are involved in each training epoch. FedFNN employs supervised learning to predict weight updates from unsampled users, using updates from the sampled set. Our evaluations, using real and synthetic data, show: 1. FedFNN achieves training speeds 5x faster than leading methods, maintaining or improving accuracy; 2. the algorithm's performance is consistent regardless of client cluster variations; 3. FedFNN outperforms other methods in scenarios with limited client availability, converging more quickly.
Plasticity-Optimized Complementary Networks for Unsupervised Continual Learning
Sep 12, 2023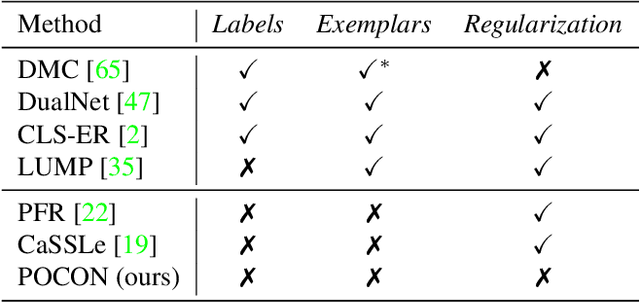
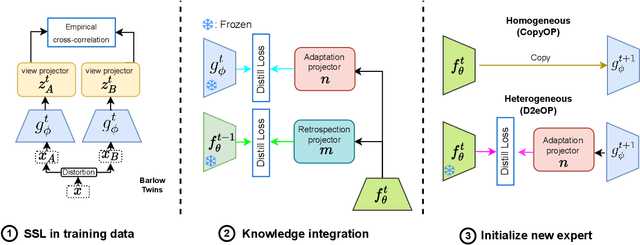
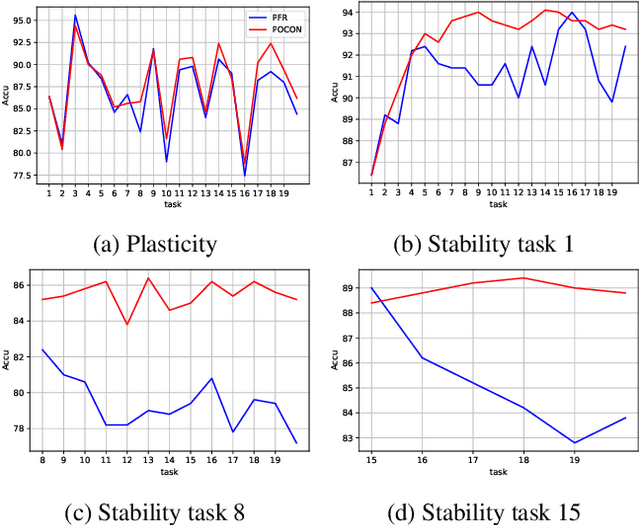
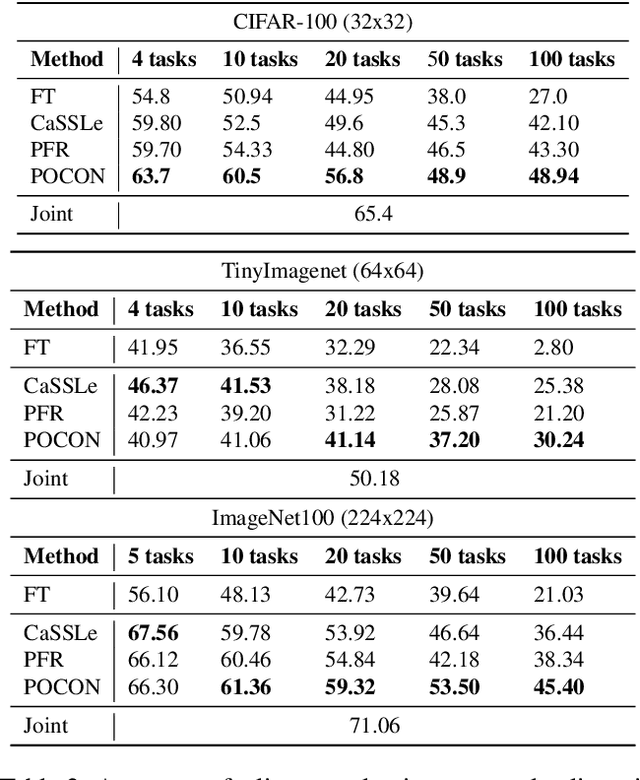
Continuous unsupervised representation learning (CURL) research has greatly benefited from improvements in self-supervised learning (SSL) techniques. As a result, existing CURL methods using SSL can learn high-quality representations without any labels, but with a notable performance drop when learning on a many-tasks data stream. We hypothesize that this is caused by the regularization losses that are imposed to prevent forgetting, leading to a suboptimal plasticity-stability trade-off: they either do not adapt fully to the incoming data (low plasticity), or incur significant forgetting when allowed to fully adapt to a new SSL pretext-task (low stability). In this work, we propose to train an expert network that is relieved of the duty of keeping the previous knowledge and can focus on performing optimally on the new tasks (optimizing plasticity). In the second phase, we combine this new knowledge with the previous network in an adaptation-retrospection phase to avoid forgetting and initialize a new expert with the knowledge of the old network. We perform several experiments showing that our proposed approach outperforms other CURL exemplar-free methods in few- and many-task split settings. Furthermore, we show how to adapt our approach to semi-supervised continual learning (Semi-SCL) and show that we surpass the accuracy of other exemplar-free Semi-SCL methods and reach the results of some others that use exemplars.
Exploiting Graph Structured Cross-Domain Representation for Multi-Domain Recommendation
Feb 22, 2023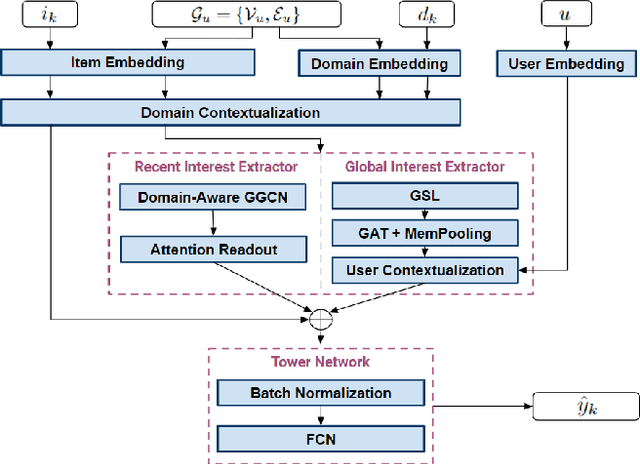
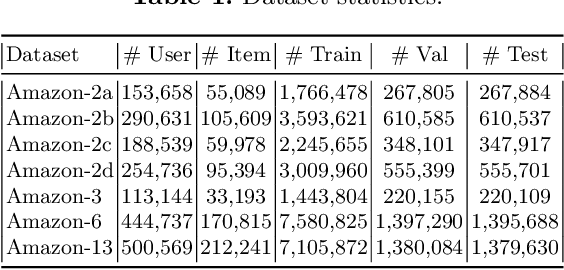
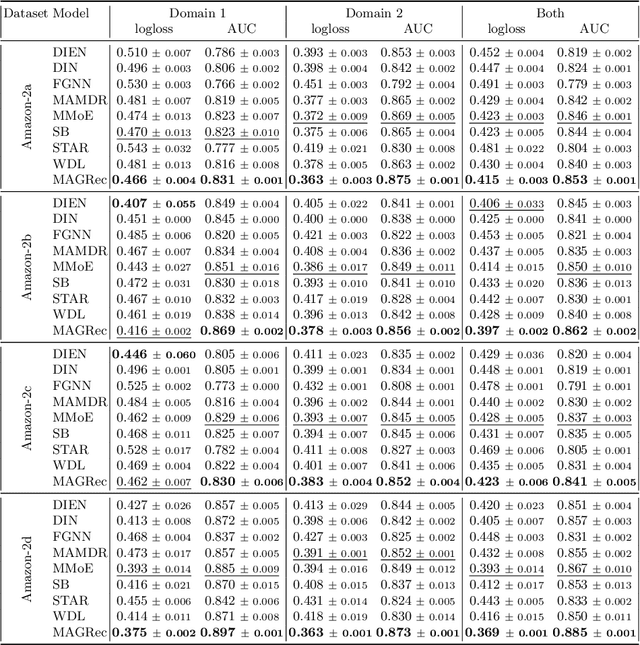
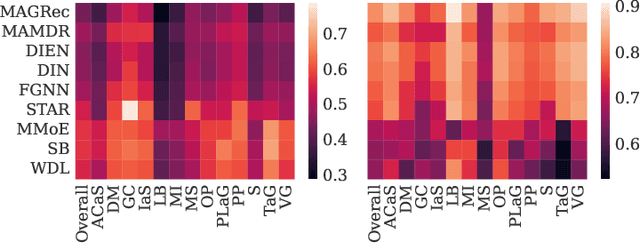
Multi-domain recommender systems benefit from cross-domain representation learning and positive knowledge transfer. Both can be achieved by introducing a specific modeling of input data (i.e. disjoint history) or trying dedicated training regimes. At the same time, treating domains as separate input sources becomes a limitation as it does not capture the interplay that naturally exists between domains. In this work, we efficiently learn multi-domain representation of sequential users' interactions using graph neural networks. We use temporal intra- and inter-domain interactions as contextual information for our method called MAGRec (short for Multi-domAin Graph-based Recommender). To better capture all relations in a multi-domain setting, we learn two graph-based sequential representations simultaneously: domain-guided for recent user interest, and general for long-term interest. This approach helps to mitigate the negative knowledge transfer problem from multiple domains and improve overall representation. We perform experiments on publicly available datasets in different scenarios where MAGRec consistently outperforms state-of-the-art methods. Furthermore, we provide an ablation study and discuss further extensions of our method.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021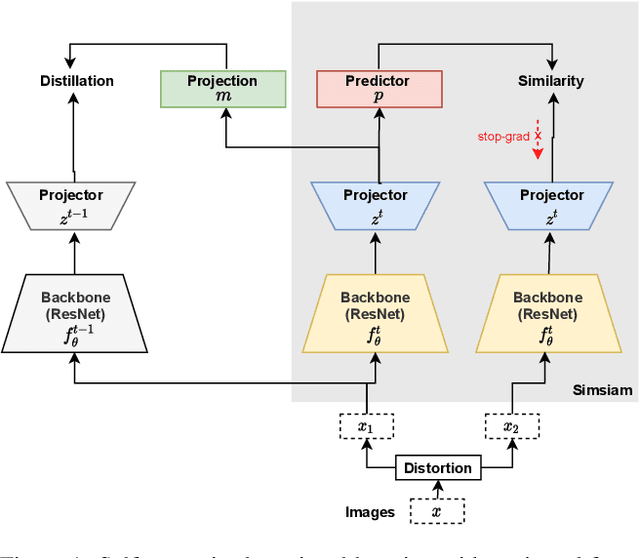
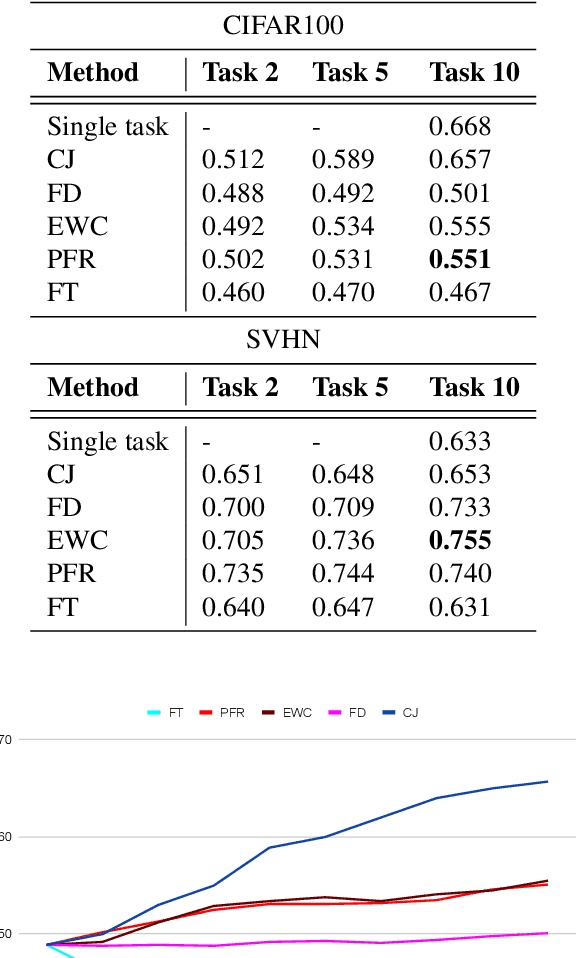
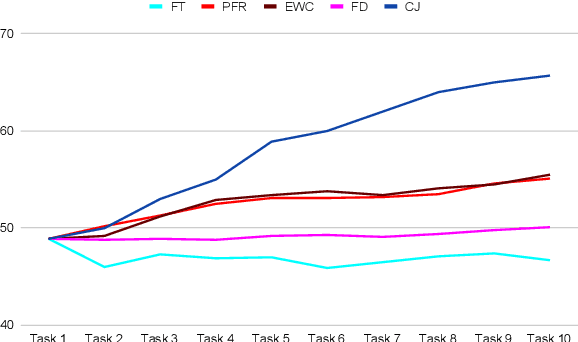
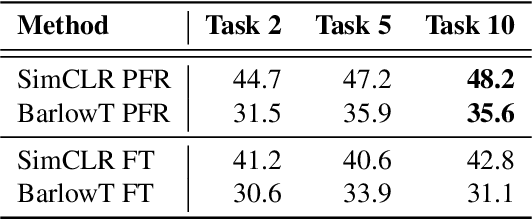
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.
Reducing Label Effort: Self-Supervised meets Active Learning
Aug 25, 2021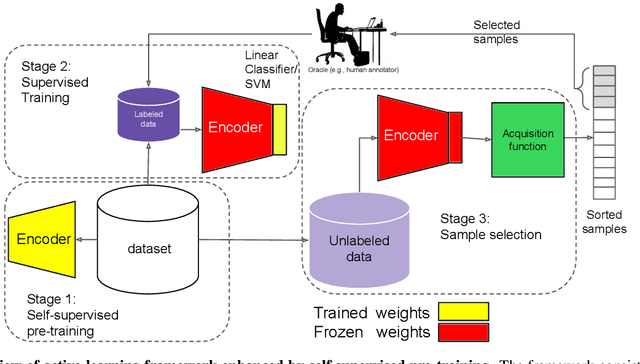
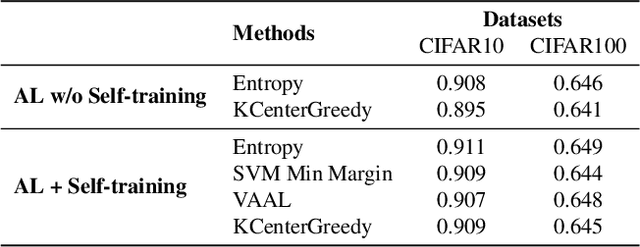
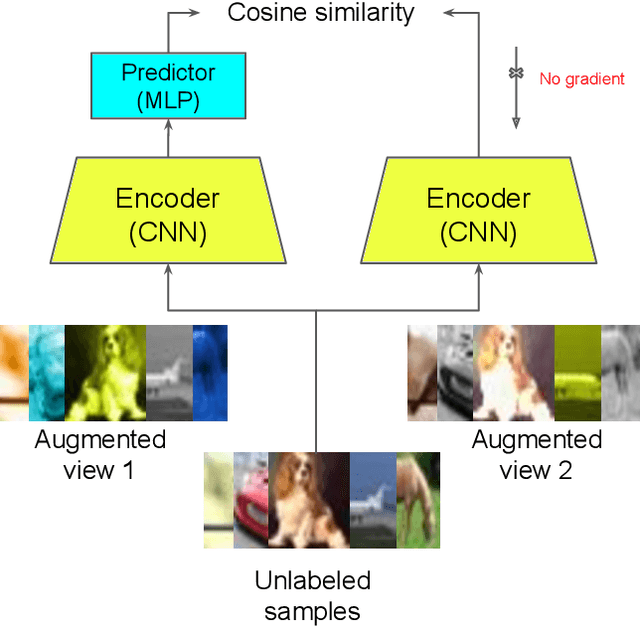
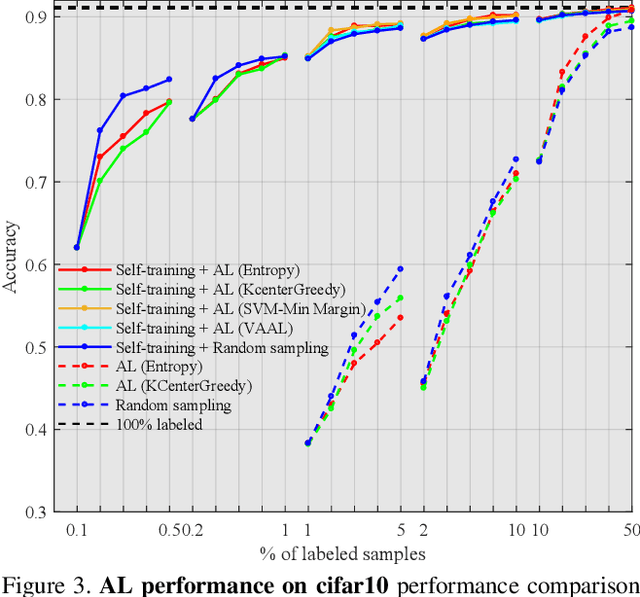
Active learning is a paradigm aimed at reducing the annotation effort by training the model on actively selected informative and/or representative samples. Another paradigm to reduce the annotation effort is self-training that learns from a large amount of unlabeled data in an unsupervised way and fine-tunes on few labeled samples. Recent developments in self-training have achieved very impressive results rivaling supervised learning on some datasets. The current work focuses on whether the two paradigms can benefit from each other. We studied object recognition datasets including CIFAR10, CIFAR100 and Tiny ImageNet with several labeling budgets for the evaluations. Our experiments reveal that self-training is remarkably more efficient than active learning at reducing the labeling effort, that for a low labeling budget, active learning offers no benefit to self-training, and finally that the combination of active learning and self-training is fruitful when the labeling budget is high. The performance gap between active learning trained either with self-training or from scratch diminishes as we approach to the point where almost half of the dataset is labeled.
Class-incremental learning: survey and performance evaluation
Oct 28, 2020
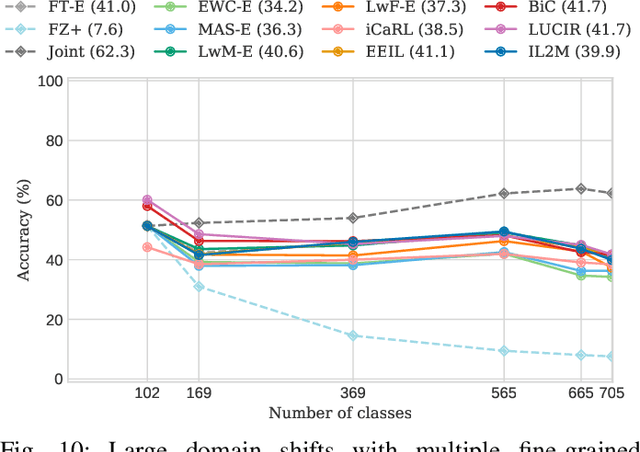
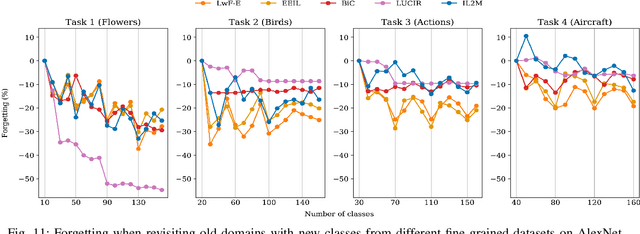
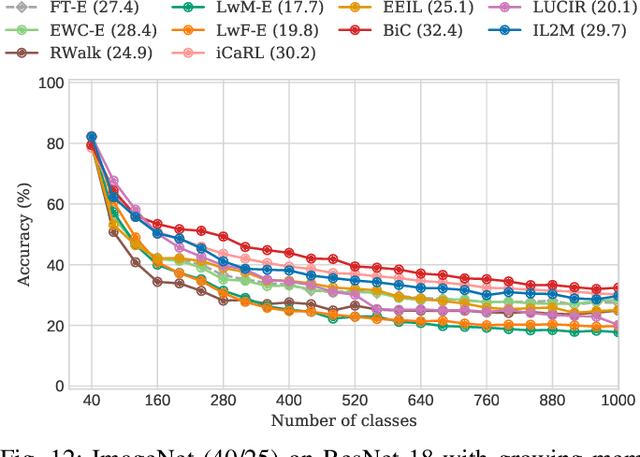
For future learning systems incremental learning is desirable, because it allows for: efficient resource usage by eliminating the need to retrain from scratch at the arrival of new data; reduced memory usage by preventing or limiting the amount of data required to be stored -- also important when privacy limitations are imposed; and learning that more closely resembles human learning. The main challenge for incremental learning is catastrophic forgetting, which refers to the precipitous drop in performance on previously learned tasks after learning a new one. Incremental learning of deep neural networks has seen explosive growth in recent years. Initial work focused on task incremental learning, where a task-ID is provided at inference time. Recently we have seen a shift towards class-incremental learning where the learner must classify at inference time between all classes seen in previous tasks without recourse to a task-ID. In this paper, we provide a complete survey of existing methods for incremental learning, and in particular we perform an extensive experimental evaluation on twelve class-incremental methods. We consider several new experimental scenarios, including a comparison of class-incremental methods on multiple large-scale datasets, investigation into small and large domain shifts, and comparison on various network architectures.
Orderless Recurrent Models for Multi-label Classification
Nov 25, 2019
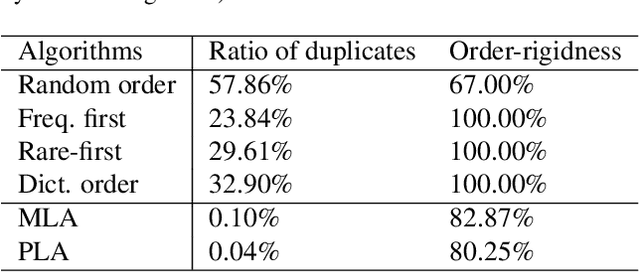
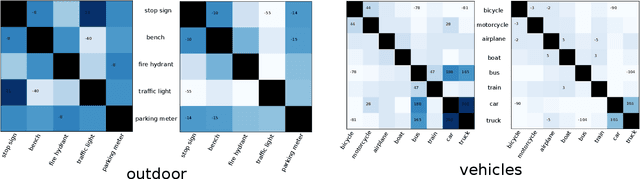
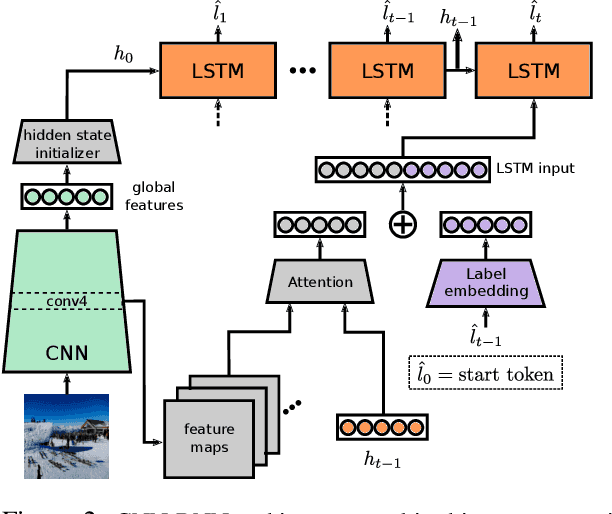
Recurrent neural networks (RNN) are popular for many computer vision tasks, including multi-label classification. Since RNNs produce sequential outputs, labels need to be ordered for the multi-label classification task. Current approaches sort labels according to their frequency, typically ordering them in either rare-first or frequent-first. These imposed orderings do not take into account that the natural order to generate the labels can change for each image, e.g.\ first the dominant object before summing up the smaller objects in the image. Therefore, in this paper, we propose ways to dynamically order the ground truth labels with the predicted label sequence. This allows for the faster training of more optimal LSTM models for multi-label classification. Analysis evidences that our method does not suffer from duplicate generation, something which is common for other models. Furthermore, it outperforms other CNN-RNN models, and we show that a standard architecture of an image encoder and language decoder trained with our proposed loss obtains the state-of-the-art results on the challenging MS-COCO, WIDER Attribute and PA-100K and competitive results on NUS-WIDE.