 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticity-Optimized Complementary Networks for Unsupervised Continual Learning
Paper and Code
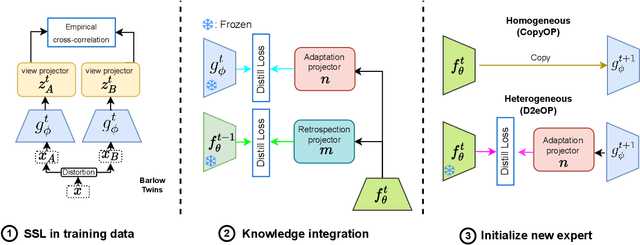
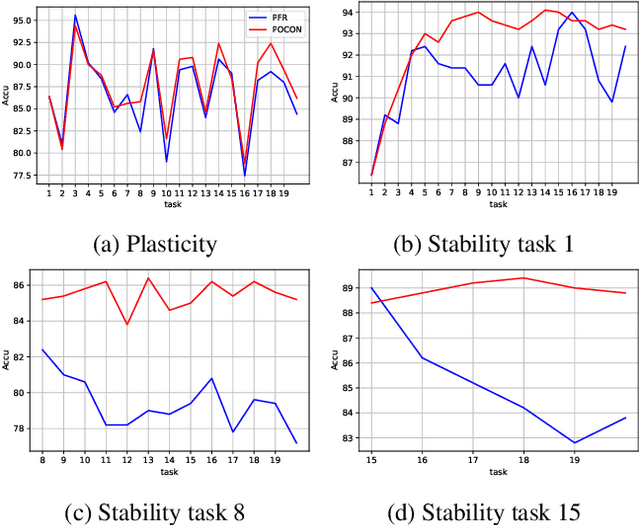
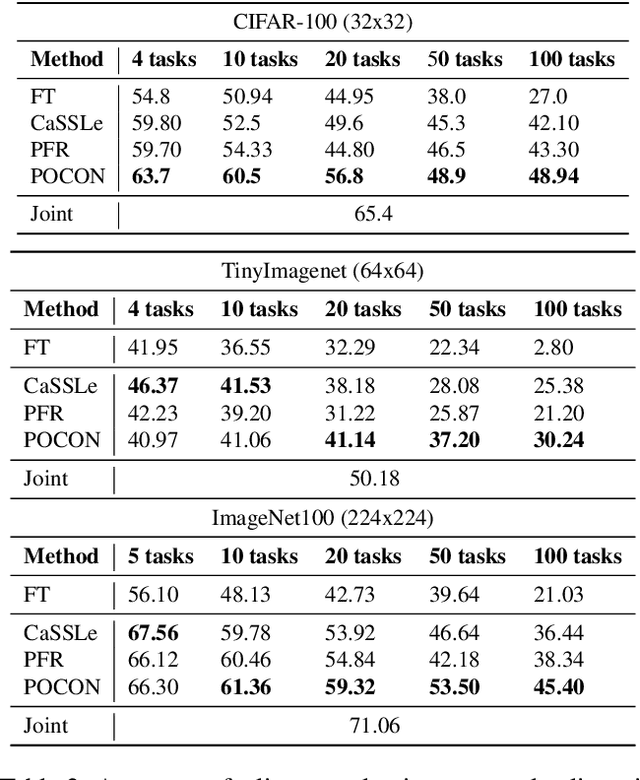
Continuous unsupervised representation learning (CURL) research has greatly benefited from improvements in self-supervised learning (SSL) techniques. As a result, existing CURL methods using SSL can learn high-quality representations without any labels, but with a notable performance drop when learning on a many-tasks data stream. We hypothesize that this is caused by the regularization losses that are imposed to prevent forgetting, leading to a suboptimal plasticity-stability trade-off: they either do not adapt fully to the incoming data (low plasticity), or incur significant forgetting when allowed to fully adapt to a new SSL pretext-task (low stability). In this work, we propose to train an expert network that is relieved of the duty of keeping the previous knowledge and can focus on performing optimally on the new tasks (optimizing plasticity). In the second phase, we combine this new knowledge with the previous network in an adaptation-retrospection phase to avoid forgetting and initialize a new expert with the knowledge of the old network. We perform several experiments showing that our proposed approach outperforms other CURL exemplar-free methods in few- and many-task split settings. Furthermore, we show how to adapt our approach to semi-supervised continual learning (Semi-SCL) and show that we surpass the accuracy of other exemplar-free Semi-SCL methods and reach the results of some others that use exemplars.