 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay-free Online Continual Learning with Self-Supervised MultiPatches
Feb 13, 2025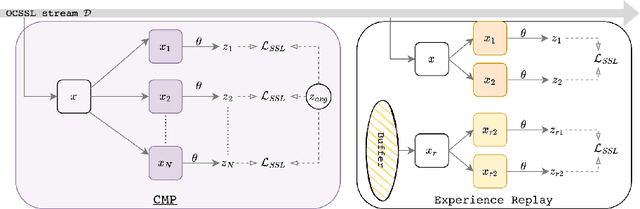
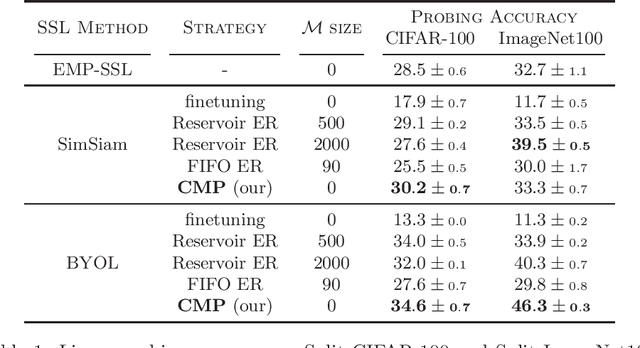
Online Continual Learning (OCL) methods train a model on a non-stationary data stream where only a few examples are available at a time, often leveraging replay strategies. However, usage of replay is sometimes forbidden, especially in applications with strict privacy regulations. Therefore, we propose Continual MultiPatches (CMP), an effective plug-in for existing OCL self-supervised learning strategies that avoids the use of replay samples. CMP generates multiple patches from a single example and projects them into a shared feature space, where patches coming from the same example are pushed together without collapsing into a single point. CMP surpasses replay and other SSL-based strategies on OCL streams, challenging the role of replay as a go-to solution for self-supervised OCL.
The Art of Deception: Color Visual Illusions and Diffusion Models
Dec 13, 2024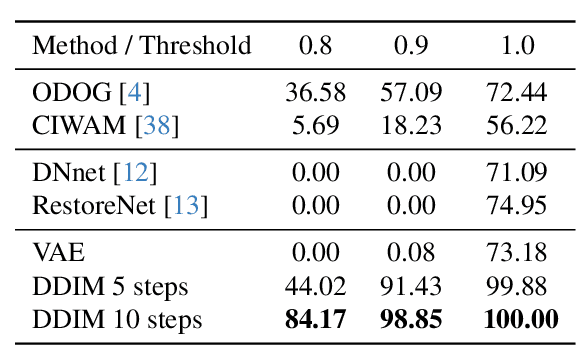
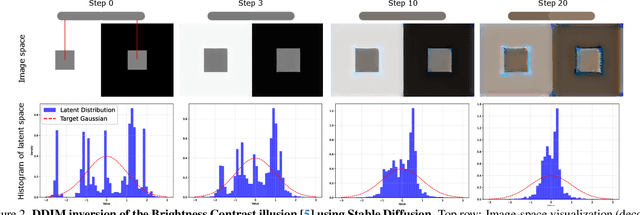
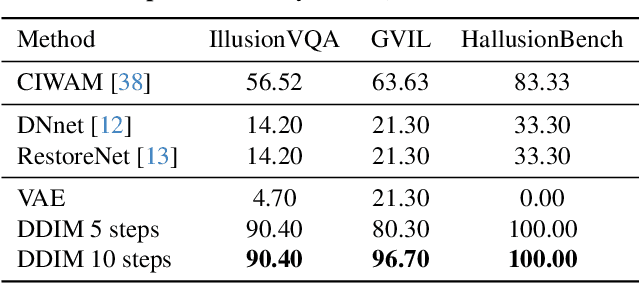
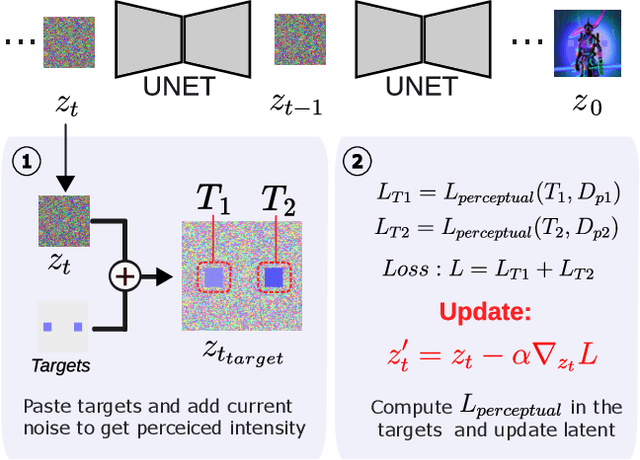
Visual illusions in humans arise when interpreting out-of-distribution stimuli: if the observer is adapted to certain statistics, perception of outliers deviates from reality. Recent studies have shown that artificial neural networks (ANNs) can also be deceived by visual illusions. This revelation raises profound questions about the nature of visual information. Why are two independent systems, both human brains and ANNs, susceptible to the same illusions? Should any ANN be capable of perceiving visual illusions? Are these perceptions a feature or a flaw? In this work, we study how visual illusions are encoded in diffusion models. Remarkably, we show that they present human-like brightness/color shifts in their latent space. We use this fact to demonstrate that diffusion models can predict visual illusions. Furthermore, we also show how to generate new unseen visual illusions in realistic images using text-to-image diffusion models. We validate this ability through psychophysical experiments that show how our model-generated illusions also fool humans.
Assessing Open-world Forgetting in Generative Image Model Customization
Oct 18, 2024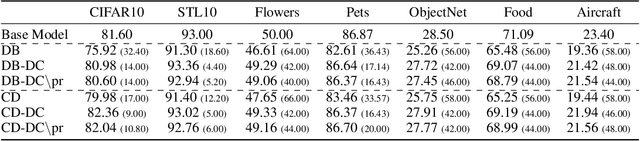
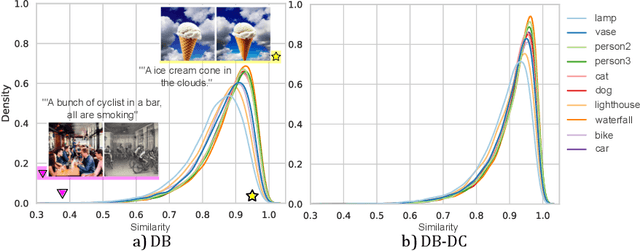


Recent advances in diffusion models have significantly enhanced image generation capabilities. However, customizing these models with new classes often leads to unintended consequences that compromise their reliability. We introduce the concept of open-world forgetting to emphasize the vast scope of these unintended alterations, contrasting it with the well-studied closed-world forgetting, which is measurable by evaluating performance on a limited set of classes or skills. Our research presents the first comprehensive investigation into open-world forgetting in diffusion models, focusing on semantic and appearance drift of representations. We utilize zero-shot classification to analyze semantic drift, revealing that even minor model adaptations lead to unpredictable shifts affecting areas far beyond newly introduced concepts, with dramatic drops in zero-shot classification of up to 60%. Additionally, we observe significant changes in texture and color of generated content when analyzing appearance drift. To address these issues, we propose a mitigation strategy based on functional regularization, designed to preserve original capabilities while accommodating new concepts. Our study aims to raise awareness of unintended changes due to model customization and advocates for the analysis of open-world forgetting in future research on model customization and finetuning methods. Furthermore, we provide insights for developing more robust adaptation methodologies.
Exemplar-free Continual Representation Learning via Learnable Drift Compensation
Jul 11, 2024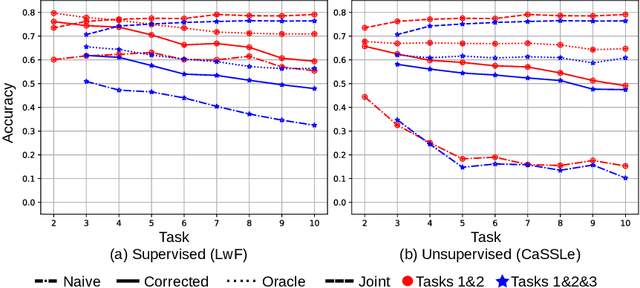
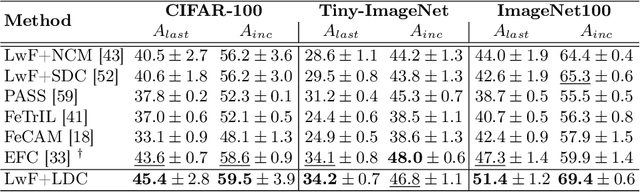

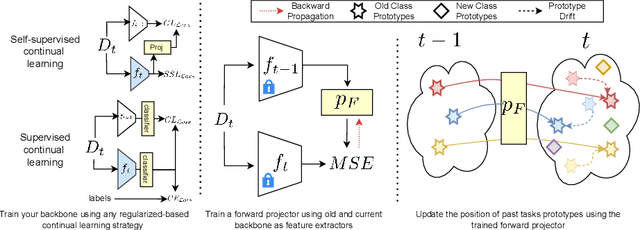
Exemplar-free class-incremental learning using a backbone trained from scratch and starting from a small first task presents a significant challenge for continual representation learning. Prototype-based approaches, when continually updated, face the critical issue of semantic drift due to which the old class prototypes drift to different positions in the new feature space. Through an analysis of prototype-based continual learning, we show that forgetting is not due to diminished discriminative power of the feature extractor, and can potentially be corrected by drift compensation. To address this, we propose Learnable Drift Compensation (LDC), which can effectively mitigate drift in any moving backbone, whether supervised or unsupervised. LDC is fast and straightforward to integrate on top of existing continual learning approaches. Furthermore, we showcase how LDC can be applied in combination with self-supervised CL methods, resulting in the first exemplar-free semi-supervised continual learning approach. We achieve state-of-the-art performance in both supervised and semi-supervised settings across multiple datasets. Code is available at \url{https://github.com/alviur/ldc}.
Plasticity-Optimized Complementary Networks for Unsupervised Continual Learning
Sep 12, 2023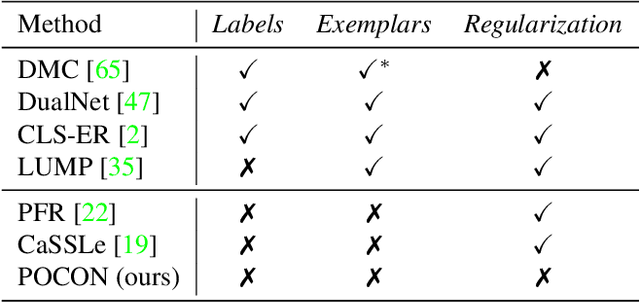
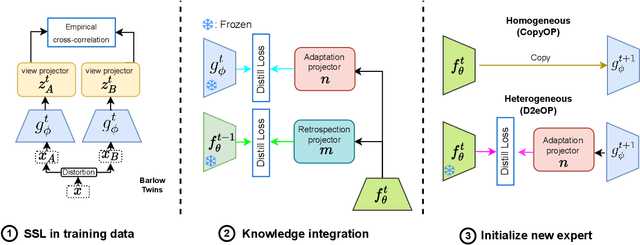
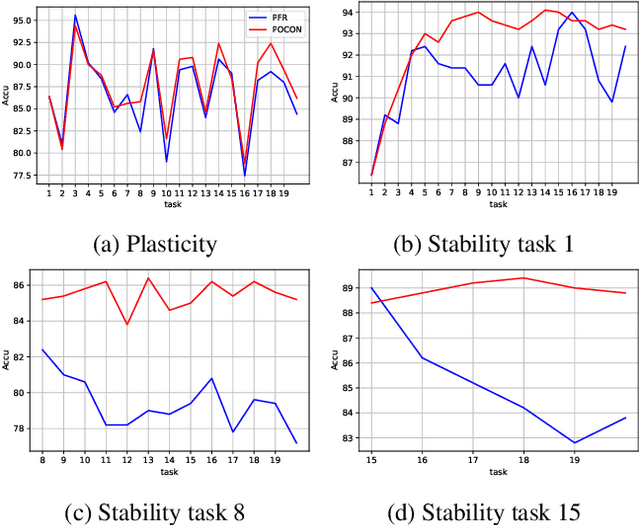
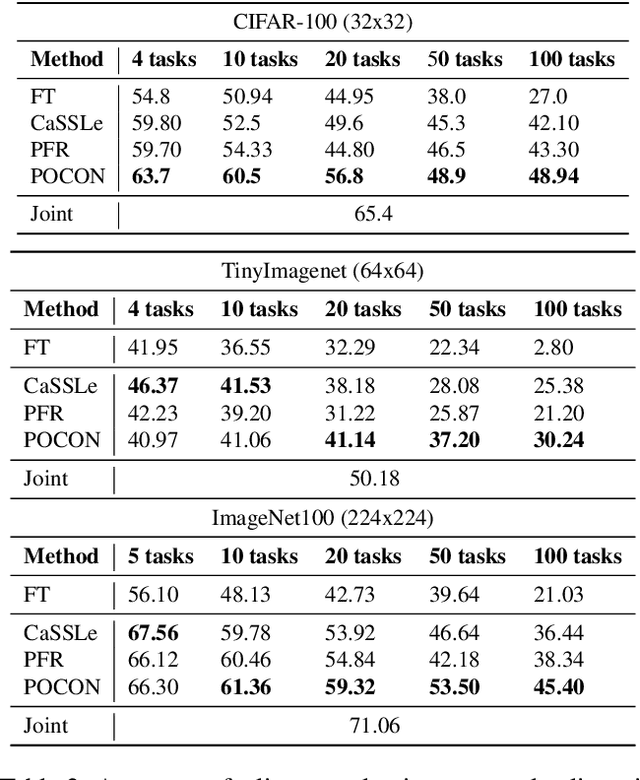
Continuous unsupervised representation learning (CURL) research has greatly benefited from improvements in self-supervised learning (SSL) techniques. As a result, existing CURL methods using SSL can learn high-quality representations without any labels, but with a notable performance drop when learning on a many-tasks data stream. We hypothesize that this is caused by the regularization losses that are imposed to prevent forgetting, leading to a suboptimal plasticity-stability trade-off: they either do not adapt fully to the incoming data (low plasticity), or incur significant forgetting when allowed to fully adapt to a new SSL pretext-task (low stability). In this work, we propose to train an expert network that is relieved of the duty of keeping the previous knowledge and can focus on performing optimally on the new tasks (optimizing plasticity). In the second phase, we combine this new knowledge with the previous network in an adaptation-retrospection phase to avoid forgetting and initialize a new expert with the knowledge of the old network. We perform several experiments showing that our proposed approach outperforms other CURL exemplar-free methods in few- and many-task split settings. Furthermore, we show how to adapt our approach to semi-supervised continual learning (Semi-SCL) and show that we surpass the accuracy of other exemplar-free Semi-SCL methods and reach the results of some others that use exemplars.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021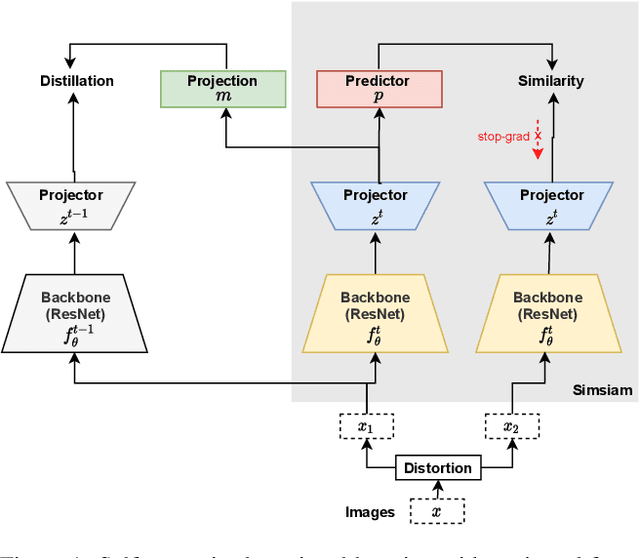
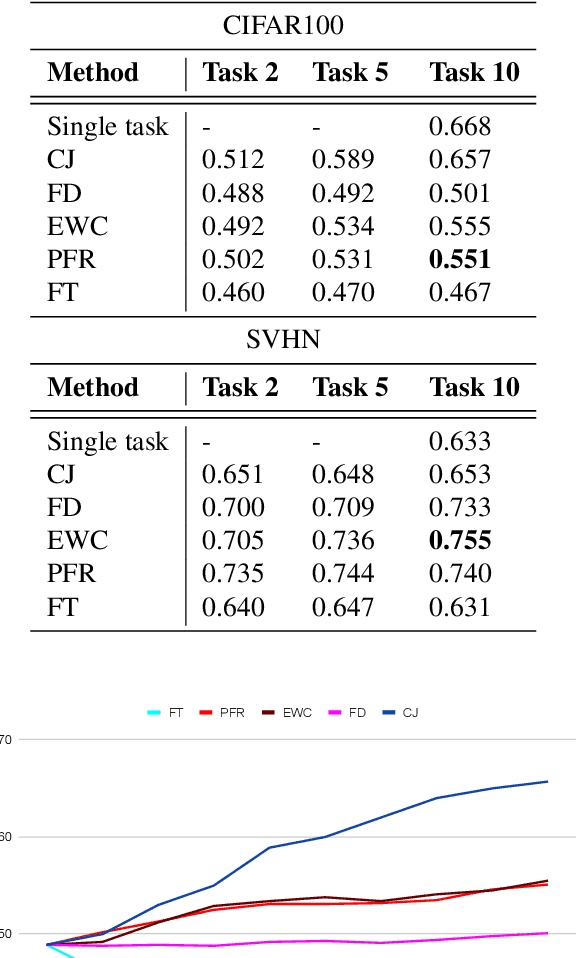
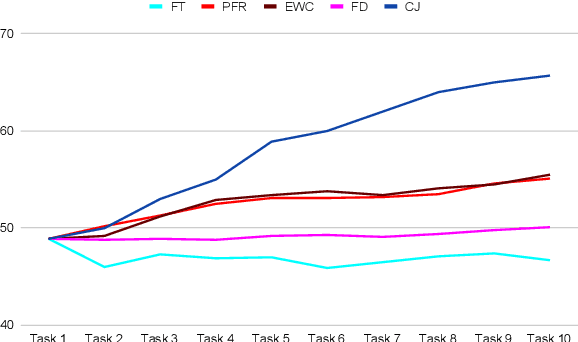
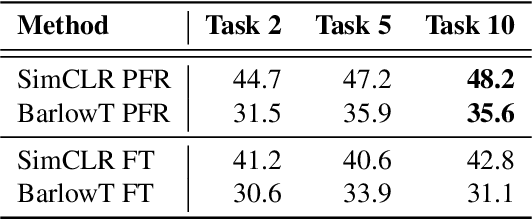
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.