 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Attribute Binding for Free-Lunch Color Control in Diffusion Models
Mar 12, 2025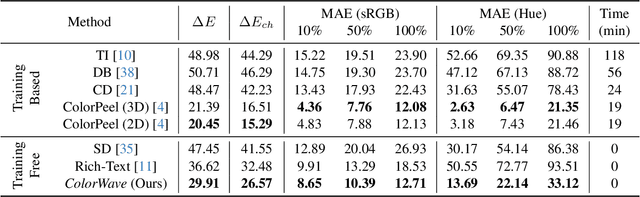
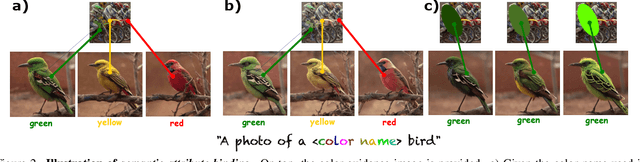
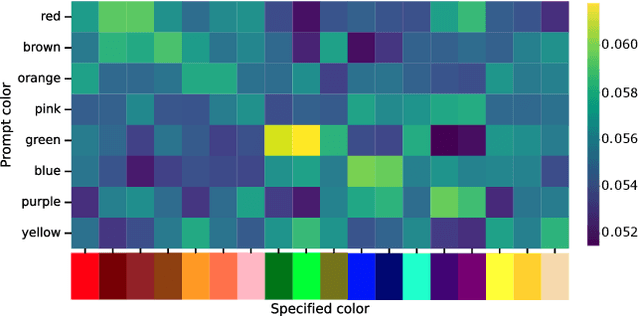
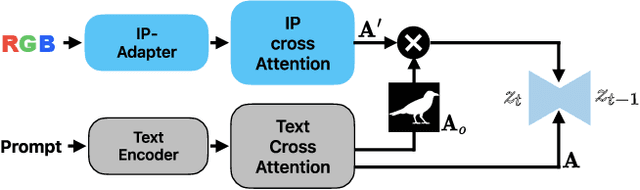
Recent advances in text-to-image (T2I) diffusion models have enabled remarkable control over various attributes, yet precise color specification remains a fundamental challenge. Existing approaches, such as ColorPeel, rely on model personalization, requiring additional optimization and limiting flexibility in specifying arbitrary colors. In this work, we introduce ColorWave, a novel training-free approach that achieves exact RGB-level color control in diffusion models without fine-tuning. By systematically analyzing the cross-attention mechanisms within IP-Adapter, we uncover an implicit binding between textual color descriptors and reference image features. Leveraging this insight, our method rewires these bindings to enforce precise color attribution while preserving the generative capabilities of pretrained models. Our approach maintains generation quality and diversity, outperforming prior methods in accuracy and applicability across diverse object categories. Through extensive evaluations, we demonstrate that ColorWave establishes a new paradigm for structured, color-consistent diffusion-based image synthesis.
Assessing Open-world Forgetting in Generative Image Model Customization
Oct 18, 2024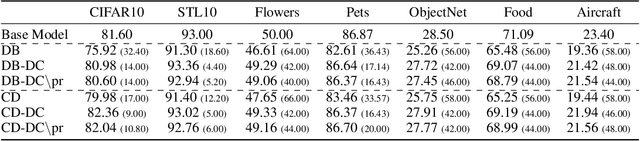
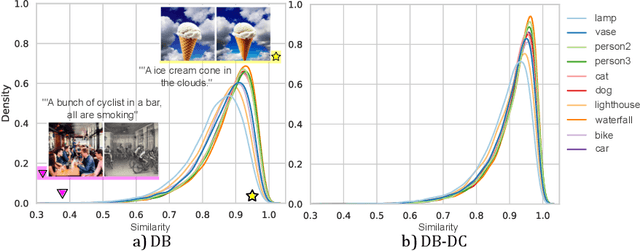


Recent advances in diffusion models have significantly enhanced image generation capabilities. However, customizing these models with new classes often leads to unintended consequences that compromise their reliability. We introduce the concept of open-world forgetting to emphasize the vast scope of these unintended alterations, contrasting it with the well-studied closed-world forgetting, which is measurable by evaluating performance on a limited set of classes or skills. Our research presents the first comprehensive investigation into open-world forgetting in diffusion models, focusing on semantic and appearance drift of representations. We utilize zero-shot classification to analyze semantic drift, revealing that even minor model adaptations lead to unpredictable shifts affecting areas far beyond newly introduced concepts, with dramatic drops in zero-shot classification of up to 60%. Additionally, we observe significant changes in texture and color of generated content when analyzing appearance drift. To address these issues, we propose a mitigation strategy based on functional regularization, designed to preserve original capabilities while accommodating new concepts. Our study aims to raise awareness of unintended changes due to model customization and advocates for the analysis of open-world forgetting in future research on model customization and finetuning methods. Furthermore, we provide insights for developing more robust adaptation methodologies.
Hyper-GAN: Transferring Unconditional to Conditional GANs with HyperNetworks
Dec 04, 2021


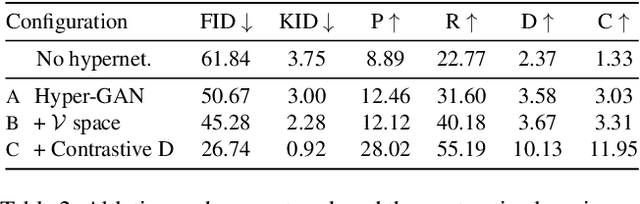
Conditional GANs have matured in recent years and are able to generate high-quality realistic images. However, the computational resources and the training data required for the training of high-quality GANs are enormous, and the study of transfer learning of these models is therefore an urgent topic. In this paper, we explore the transfer from high-quality pre-trained unconditional GANs to conditional GANs. To this end, we propose hypernetwork-based adaptive weight modulation. In addition, we introduce a self-initialization procedure that does not require any real data to initialize the hypernetwork parameters. To further improve the sample efficiency of the knowledge transfer, we propose to use a self-supervised (contrastive) loss to improve the GAN discriminator. In extensive experiments, we validate the efficiency of the hypernetworks, self-initialization and contrastive loss for knowledge transfer on several standard benchmarks.