 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Distribution Matching for Few-Step Diffusion Distillation
May 07, 2026Step distillation has become a leading technique for accelerating diffusion models, among which Distribution Matching Distillation (DMD) and Consistency Distillation are two representative paradigms. While consistency methods enforce self-consistency along the full PF-ODE trajectory to steer it toward the clean data manifold, vanilla DMD relies on sparse supervision at a few predefined discrete timesteps. This restricted discrete-time formulation and mode-seeking nature of the reverse KL divergence tends to exhibit visual artifacts and over-smoothed outputs, often necessitating complex auxiliary modules -- such as GANs or reward models -- to restore visual fidelity. In this work, we introduce Continuous-Time Distribution Matching (CDM), migrating the DMD framework from discrete anchoring to continuous optimization for the first time. CDM achieves this through two continuous-time designs. First, we replace the fixed discrete schedule with a dynamic continuous schedule of random length, so that distribution matching is enforced at arbitrary points along sampling trajectories rather than only at a few fixed anchors. Second, we propose a continuous-time alignment objective that performs active off-trajectory matching on latents extrapolated via the student's velocity field, improving generalization and preserving fine visual details. Extensive experiments on different architectures, including SD3-Medium and Longcat-Image, demonstrate that CDM provides highly competitive visual fidelity for few-step image generation without relying on complex auxiliary objectives. Code is available at https://github.com/byliutao/cdm.
RefAlign: Representation Alignment for Reference-to-Video Generation
Mar 26, 2026Reference-to-video (R2V) generation is a controllable video synthesis paradigm that constrains the generation process using both text prompts and reference images, enabling applications such as personalized advertising and virtual try-on. In practice, existing R2V methods typically introduce additional high-level semantic or cross-modal features alongside the VAE latent representation of the reference image and jointly feed them into the diffusion Transformer (DiT). These auxiliary representations provide semantic guidance and act as implicit alignment signals, which can partially alleviate pixel-level information leakage in the VAE latent space. However, they may still struggle to address copy--paste artifacts and multi-subject confusion caused by modality mismatch across heterogeneous encoder features. In this paper, we propose RefAlign, a representation alignment framework that explicitly aligns DiT reference-branch features to the semantic space of a visual foundation model (VFM). The core of RefAlign is a reference alignment loss that pulls the reference features and VFM features of the same subject closer to improve identity consistency, while pushing apart the corresponding features of different subjects to enhance semantic discriminability. This simple yet effective strategy is applied only during training, incurring no inference-time overhead, and achieves a better balance between text controllability and reference fidelity. Extensive experiments on the OpenS2V-Eval benchmark demonstrate that RefAlign outperforms current state-of-the-art methods in TotalScore, validating the effectiveness of explicit reference alignment for R2V tasks.
WaDi: Weight Direction-aware Distillation for One-step Image Synthesis
Mar 09, 2026Despite the impressive performance of diffusion models such as Stable Diffusion (SD) in image generation, their slow inference limits practical deployment. Recent works accelerate inference by distilling multi-step diffusion into one-step generators. To better understand the distillation mechanism, we analyze U-Net/DiT weight changes between one-step students and their multi-step teacher counterparts. Our analysis reveals that changes in weight direction significantly exceed those in weight norm, highlighting it as the key factor during distillation. Motivated by this insight, we propose the Low-rank Rotation of weight Direction (LoRaD), a parameter-efficient adapter tailored to one-step diffusion distillation. LoRaD is designed to model these structured directional changes using learnable low-rank rotation matrices. We further integrate LoRaD into Variational Score Distillation (VSD), resulting in Weight Direction-aware Distillation (WaDi)-a novel one-step distillation framework. WaDi achieves state-of-the-art FID scores on COCO 2014 and COCO 2017 while using only approximately 10% of the trainable parameters of the U-Net/DiT. Furthermore, the distilled one-step model demonstrates strong versatility and scalability, generalizing well to various downstream tasks such as controllable generation, relation inversion, and high-resolution synthesis.
StageVAR: Stage-Aware Acceleration for Visual Autoregressive Models
Dec 18, 2025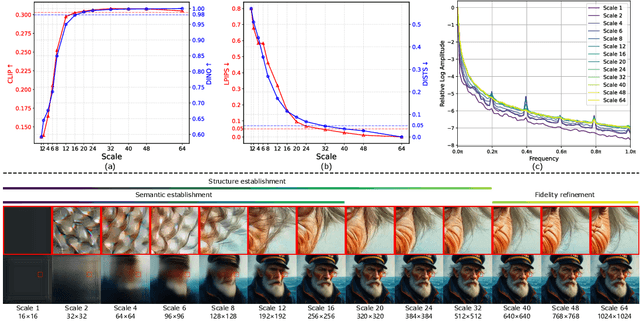
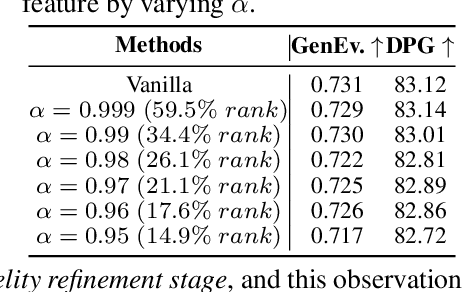

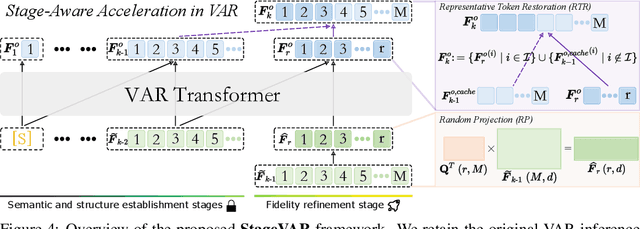
Visual Autoregressive (VAR) modeling departs from the next-token prediction paradigm of traditional Autoregressive (AR) models through next-scale prediction, enabling high-quality image generation. However, the VAR paradigm suffers from sharply increased computational complexity and running time at large-scale steps. Although existing acceleration methods reduce runtime for large-scale steps, but rely on manual step selection and overlook the varying importance of different stages in the generation process. To address this challenge, we present StageVAR, a systematic study and stage-aware acceleration framework for VAR models. Our analysis shows that early steps are critical for preserving semantic and structural consistency and should remain intact, while later steps mainly refine details and can be pruned or approximated for acceleration. Building on these insights, StageVAR introduces a plug-and-play acceleration strategy that exploits semantic irrelevance and low-rank properties in late-stage computations, without requiring additional training. Our proposed StageVAR achieves up to 3.4x speedup with only a 0.01 drop on GenEval and a 0.26 decrease on DPG, consistently outperforming existing acceleration baselines. These results highlight stage-aware design as a powerful principle for efficient visual autoregressive image generation.
Restore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025
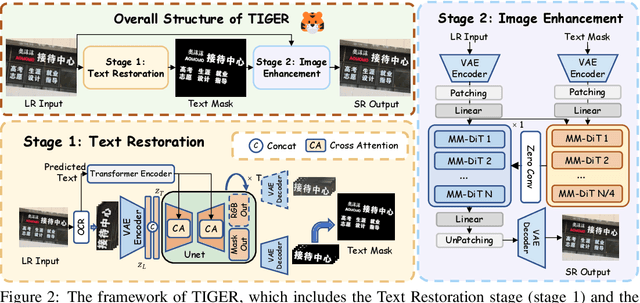
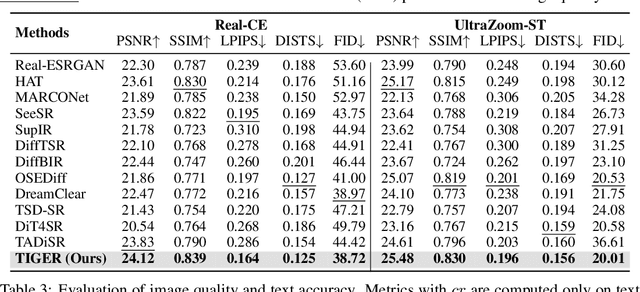
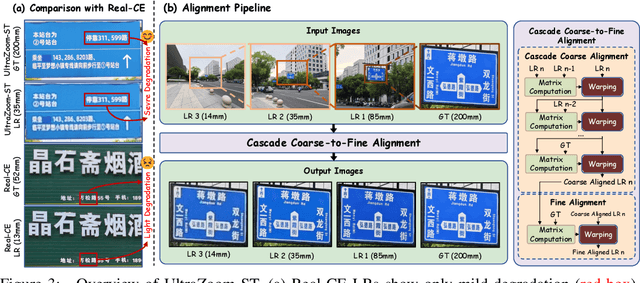
Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.
EchoDistill: Bidirectional Concept Distillation for One-Step Diffusion Personalization
Oct 23, 2025Recent advances in accelerating text-to-image (T2I) diffusion models have enabled the synthesis of high-fidelity images even in a single step. However, personalizing these models to incorporate novel concepts remains a challenge due to the limited capacity of one-step models to capture new concept distributions effectively. We propose a bidirectional concept distillation framework, EchoDistill, to enable one-step diffusion personalization (1-SDP). Our approach involves an end-to-end training process where a multi-step diffusion model (teacher) and a one-step diffusion model (student) are trained simultaneously. The concept is first distilled from the teacher model to the student, and then echoed back from the student to the teacher. During the EchoDistill, we share the text encoder between the two models to ensure consistent semantic understanding. Following this, the student model is optimized with adversarial losses to align with the real image distribution and with alignment losses to maintain consistency with the teacher's output. Furthermore, we introduce the bidirectional echoing refinement strategy, wherein the student model leverages its faster generation capability to feedback to the teacher model. This bidirectional concept distillation mechanism not only enhances the student ability to personalize novel concepts but also improves the generative quality of the teacher model. Our experiments demonstrate that this collaborative framework significantly outperforms existing personalization methods over the 1-SDP setup, establishing a novel paradigm for rapid and effective personalization in T2I diffusion models.
From Cradle to Cane: A Two-Pass Framework for High-Fidelity Lifespan Face Aging
Jun 26, 2025



Face aging has become a crucial task in computer vision, with applications ranging from entertainment to healthcare. However, existing methods struggle with achieving a realistic and seamless transformation across the entire lifespan, especially when handling large age gaps or extreme head poses. The core challenge lies in balancing age accuracy and identity preservation--what we refer to as the Age-ID trade-off. Most prior methods either prioritize age transformation at the expense of identity consistency or vice versa. In this work, we address this issue by proposing a two-pass face aging framework, named Cradle2Cane, based on few-step text-to-image (T2I) diffusion models. The first pass focuses on solving age accuracy by introducing an adaptive noise injection (AdaNI) mechanism. This mechanism is guided by including prompt descriptions of age and gender for the given person as the textual condition. Also, by adjusting the noise level, we can control the strength of aging while allowing more flexibility in transforming the face. However, identity preservation is weakly ensured here to facilitate stronger age transformations. In the second pass, we enhance identity preservation while maintaining age-specific features by conditioning the model on two identity-aware embeddings (IDEmb): SVR-ArcFace and Rotate-CLIP. This pass allows for denoising the transformed image from the first pass, ensuring stronger identity preservation without compromising the aging accuracy. Both passes are jointly trained in an end-to-end way. Extensive experiments on the CelebA-HQ test dataset, evaluated through Face++ and Qwen-VL protocols, show that our Cradle2Cane outperforms existing face aging methods in age accuracy and identity consistency.
One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
May 28, 2025
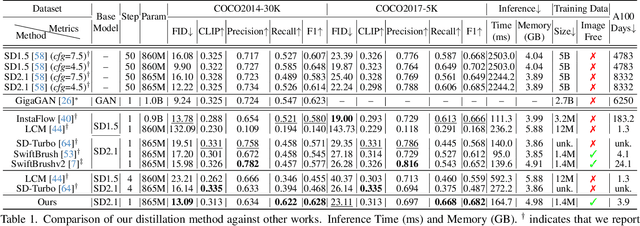

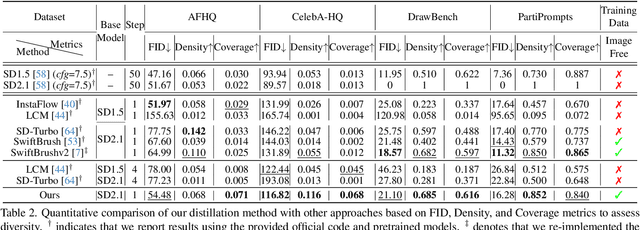
Text-to-Image (T2I) diffusion models have made remarkable advancements in generative modeling; however, they face a trade-off between inference speed and image quality, posing challenges for efficient deployment. Existing distilled T2I models can generate high-fidelity images with fewer sampling steps, but often struggle with diversity and quality, especially in one-step models. From our analysis, we observe redundant computations in the UNet encoders. Our findings suggest that, for T2I diffusion models, decoders are more adept at capturing richer and more explicit semantic information, while encoders can be effectively shared across decoders from diverse time steps. Based on these observations, we introduce the first Time-independent Unified Encoder TiUE for the student model UNet architecture, which is a loop-free image generation approach for distilling T2I diffusion models. Using a one-pass scheme, TiUE shares encoder features across multiple decoder time steps, enabling parallel sampling and significantly reducing inference time complexity. In addition, we incorporate a KL divergence term to regularize noise prediction, which enhances the perceptual realism and diversity of the generated images. Experimental results demonstrate that TiUE outperforms state-of-the-art methods, including LCM, SD-Turbo, and SwiftBrushv2, producing more diverse and realistic results while maintaining the computational efficiency.
Not All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability
May 06, 2025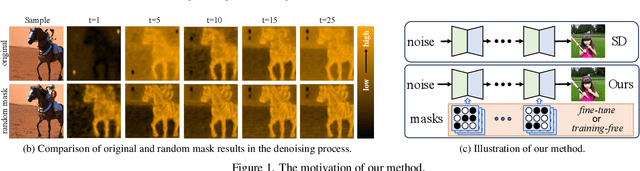
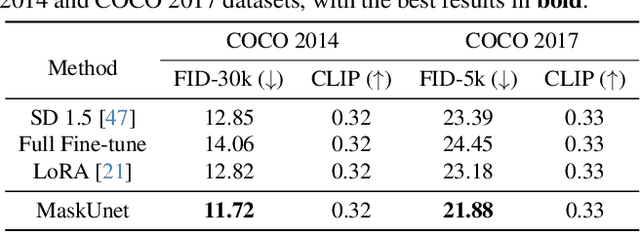
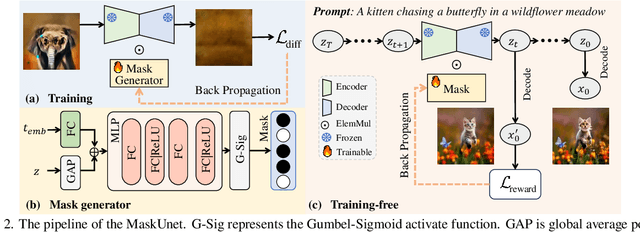
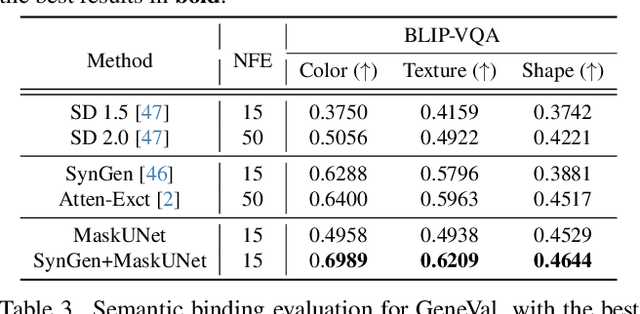
The diffusion models, in early stages focus on constructing basic image structures, while the refined details, including local features and textures, are generated in later stages. Thus the same network layers are forced to learn both structural and textural information simultaneously, significantly differing from the traditional deep learning architectures (e.g., ResNet or GANs) which captures or generates the image semantic information at different layers. This difference inspires us to explore the time-wise diffusion models. We initially investigate the key contributions of the U-Net parameters to the denoising process and identify that properly zeroing out certain parameters (including large parameters) contributes to denoising, substantially improving the generation quality on the fly. Capitalizing on this discovery, we propose a simple yet effective method-termed ``MaskUNet''- that enhances generation quality with negligible parameter numbers. Our method fully leverages timestep- and sample-dependent effective U-Net parameters. To optimize MaskUNet, we offer two fine-tuning strategies: a training-based approach and a training-free approach, including tailored networks and optimization functions. In zero-shot inference on the COCO dataset, MaskUNet achieves the best FID score and further demonstrates its effectiveness in downstream task evaluations. Project page: https://gudaochangsheng.github.io/MaskUnet-Page/
Anchor Token Matching: Implicit Structure Locking for Training-free AR Image Editing
Apr 14, 2025



Text-to-image generation has seen groundbreaking advancements with diffusion models, enabling high-fidelity synthesis and precise image editing through cross-attention manipulation. Recently, autoregressive (AR) models have re-emerged as powerful alternatives, leveraging next-token generation to match diffusion models. However, existing editing techniques designed for diffusion models fail to translate directly to AR models due to fundamental differences in structural control. Specifically, AR models suffer from spatial poverty of attention maps and sequential accumulation of structural errors during image editing, which disrupt object layouts and global consistency. In this work, we introduce Implicit Structure Locking (ISLock), the first training-free editing strategy for AR visual models. Rather than relying on explicit attention manipulation or fine-tuning, ISLock preserves structural blueprints by dynamically aligning self-attention patterns with reference images through the Anchor Token Matching (ATM) protocol. By implicitly enforcing structural consistency in latent space, our method ISLock enables structure-aware editing while maintaining generative autonomy. Extensive experiments demonstrate that ISLock achieves high-quality, structure-consistent edits without additional training and is superior or comparable to conventional editing techniques. Our findings pioneer the way for efficient and flexible AR-based image editing, further bridging the performance gap between diffusion and autoregressive generative models. The code will be publicly available at https://github.com/hutaiHang/ATM