 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025
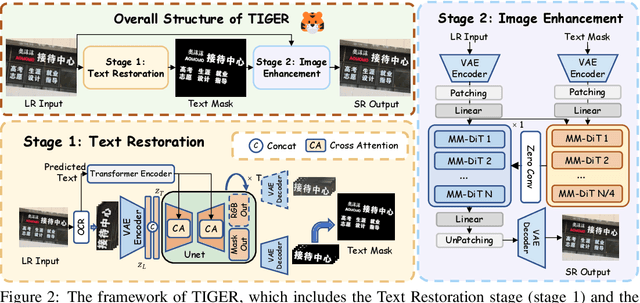
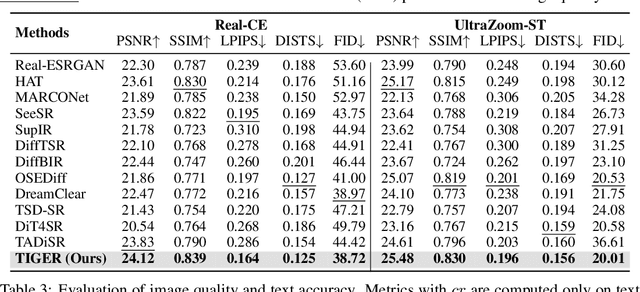
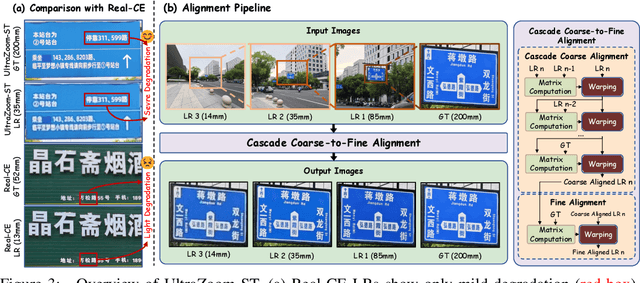
Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.
Beyond Flat Text: Dual Self-inherited Guidance for Visual Text Generation
Jan 10, 2025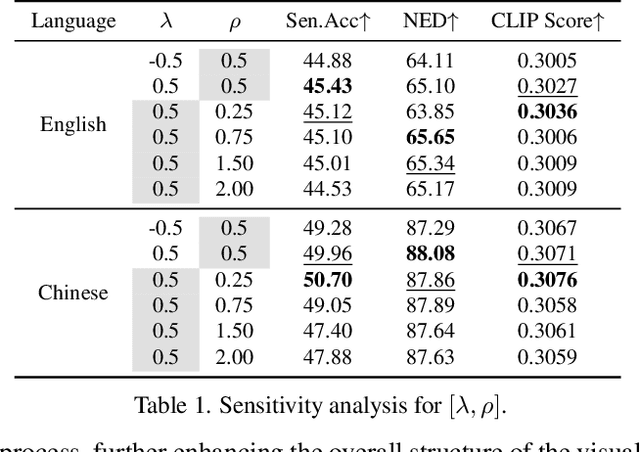


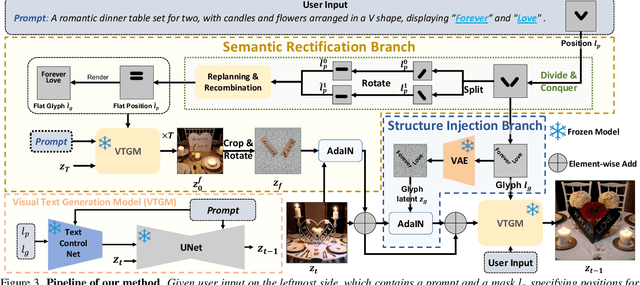
In real-world images, slanted or curved texts, especially those on cans, banners, or badges, appear as frequently, if not more so, than flat texts due to artistic design or layout constraints. While high-quality visual text generation has become available with the advanced generative capabilities of diffusion models, these models often produce distorted text and inharmonious text background when given slanted or curved text layouts due to training data limitation. In this paper, we introduce a new training-free framework, STGen, which accurately generates visual texts in challenging scenarios (\eg, slanted or curved text layouts) while harmonizing them with the text background. Our framework decomposes the visual text generation process into two branches: (i) \textbf{Semantic Rectification Branch}, which leverages the ability in generating flat but accurate visual texts of the model to guide the generation of challenging scenarios. The generated latent of flat text is abundant in accurate semantic information related both to the text itself and its background. By incorporating this, we rectify the semantic information of the texts and harmonize the integration of the text with its background in complex layouts. (ii) \textbf{Structure Injection Branch}, which reinforces the visual text structure during inference. We incorporate the latent information of the glyph image, rich in glyph structure, as a new condition to further strengthen the text structure. To enhance image harmony, we also apply an effective combination method to merge the priors, providing a solid foundation for generation. Extensive experiments across a variety of visual text layouts demonstrate that our framework achieves superior accuracy and outstanding quality.
RotationDrag: Point-based Image Editing with Rotated Diffusion Features
Jan 12, 2024A precise and user-friendly manipulation of image content while preserving image fidelity has always been crucial to the field of image editing. Thanks to the power of generative models, recent point-based image editing methods allow users to interactively change the image content with high generalizability by clicking several control points. But the above mentioned editing process is usually based on the assumption that features stay constant in the motion supervision step from initial to target points. In this work, we conduct a comprehensive investigation in the feature space of diffusion models, and find that features change acutely under in-plane rotation. Based on this, we propose a novel approach named RotationDrag, which significantly improves point-based image editing performance when users intend to in-plane rotate the image content. Our method tracks handle points more precisely by utilizing the feature map of the rotated images, thus ensuring precise optimization and high image fidelity. Furthermore, we build a in-plane rotation focused benchmark called RotateBench, the first benchmark to evaluate the performance of point-based image editing method under in-plane rotation scenario on both real images and generated images. A thorough user study demonstrates the superior capability in accomplishing in-plane rotation that users intend to achieve, comparing the DragDiffusion baseline and other existing diffusion-based methods. See the project page https://github.com/Tony-Lowe/RotationDrag for code and experiment results.