 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefAlign: Representation Alignment for Reference-to-Video Generation
Mar 26, 2026Reference-to-video (R2V) generation is a controllable video synthesis paradigm that constrains the generation process using both text prompts and reference images, enabling applications such as personalized advertising and virtual try-on. In practice, existing R2V methods typically introduce additional high-level semantic or cross-modal features alongside the VAE latent representation of the reference image and jointly feed them into the diffusion Transformer (DiT). These auxiliary representations provide semantic guidance and act as implicit alignment signals, which can partially alleviate pixel-level information leakage in the VAE latent space. However, they may still struggle to address copy--paste artifacts and multi-subject confusion caused by modality mismatch across heterogeneous encoder features. In this paper, we propose RefAlign, a representation alignment framework that explicitly aligns DiT reference-branch features to the semantic space of a visual foundation model (VFM). The core of RefAlign is a reference alignment loss that pulls the reference features and VFM features of the same subject closer to improve identity consistency, while pushing apart the corresponding features of different subjects to enhance semantic discriminability. This simple yet effective strategy is applied only during training, incurring no inference-time overhead, and achieves a better balance between text controllability and reference fidelity. Extensive experiments on the OpenS2V-Eval benchmark demonstrate that RefAlign outperforms current state-of-the-art methods in TotalScore, validating the effectiveness of explicit reference alignment for R2V tasks.
WaDi: Weight Direction-aware Distillation for One-step Image Synthesis
Mar 09, 2026Despite the impressive performance of diffusion models such as Stable Diffusion (SD) in image generation, their slow inference limits practical deployment. Recent works accelerate inference by distilling multi-step diffusion into one-step generators. To better understand the distillation mechanism, we analyze U-Net/DiT weight changes between one-step students and their multi-step teacher counterparts. Our analysis reveals that changes in weight direction significantly exceed those in weight norm, highlighting it as the key factor during distillation. Motivated by this insight, we propose the Low-rank Rotation of weight Direction (LoRaD), a parameter-efficient adapter tailored to one-step diffusion distillation. LoRaD is designed to model these structured directional changes using learnable low-rank rotation matrices. We further integrate LoRaD into Variational Score Distillation (VSD), resulting in Weight Direction-aware Distillation (WaDi)-a novel one-step distillation framework. WaDi achieves state-of-the-art FID scores on COCO 2014 and COCO 2017 while using only approximately 10% of the trainable parameters of the U-Net/DiT. Furthermore, the distilled one-step model demonstrates strong versatility and scalability, generalizing well to various downstream tasks such as controllable generation, relation inversion, and high-resolution synthesis.
MeanFlow Transformers with Representation Autoencoders
Nov 17, 2025MeanFlow (MF) is a diffusion-motivated generative model that enables efficient few-step generation by learning long jumps directly from noise to data. In practice, it is often used as a latent MF by leveraging the pre-trained Stable Diffusion variational autoencoder (SD-VAE) for high-dimensional data modeling. However, MF training remains computationally demanding and is often unstable. During inference, the SD-VAE decoder dominates the generation cost, and MF depends on complex guidance hyperparameters for class-conditional generation. In this work, we develop an efficient training and sampling scheme for MF in the latent space of a Representation Autoencoder (RAE), where a pre-trained vision encoder (e.g., DINO) provides semantically rich latents paired with a lightweight decoder. We observe that naive MF training in the RAE latent space suffers from severe gradient explosion. To stabilize and accelerate training, we adopt Consistency Mid-Training for trajectory-aware initialization and use a two-stage scheme: distillation from a pre-trained flow matching teacher to speed convergence and reduce variance, followed by an optional bootstrapping stage with a one-point velocity estimator to further reduce deviation from the oracle mean flow. This design removes the need for guidance, simplifies training configurations, and reduces computation in both training and sampling. Empirically, our method achieves a 1-step FID of 2.03, outperforming vanilla MF's 3.43, while reducing sampling GFLOPS by 38% and total training cost by 83% on ImageNet 256. We further scale our approach to ImageNet 512, achieving a competitive 1-step FID of 3.23 with the lowest GFLOPS among all baselines. Code is available at https://github.com/sony/mf-rae.
Restore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025
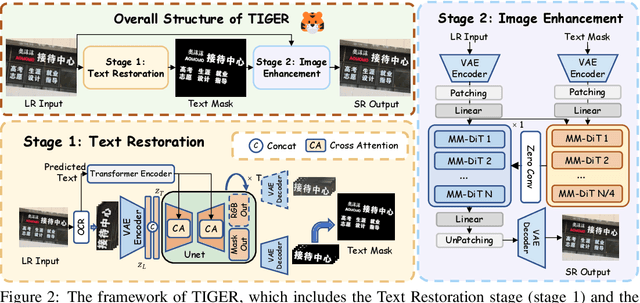
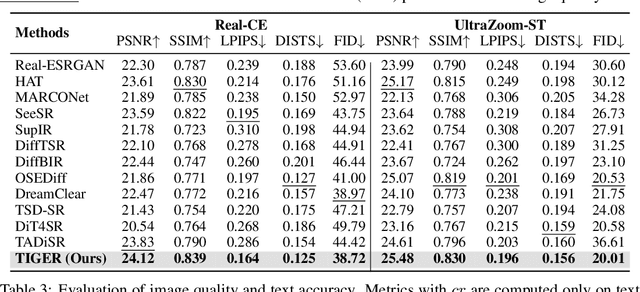
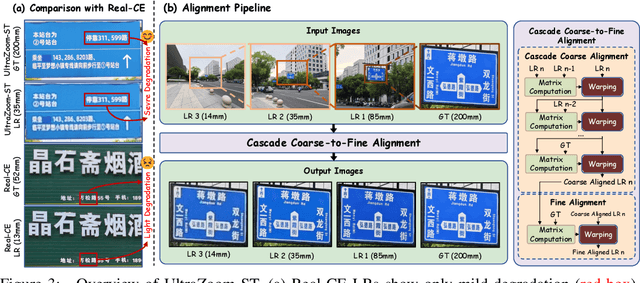
Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
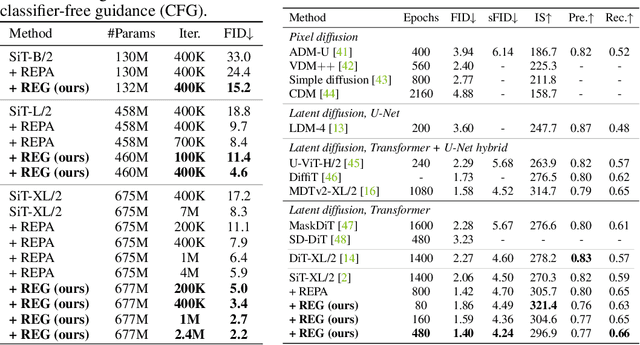
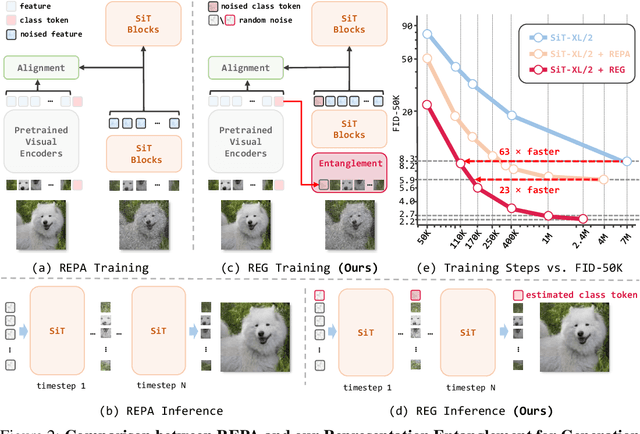
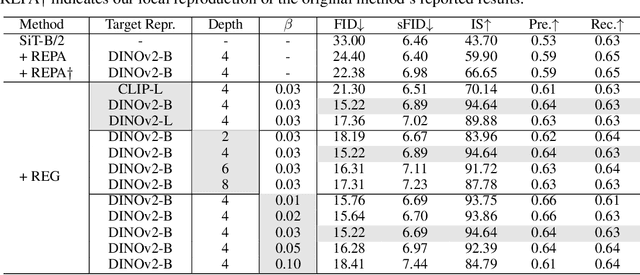
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

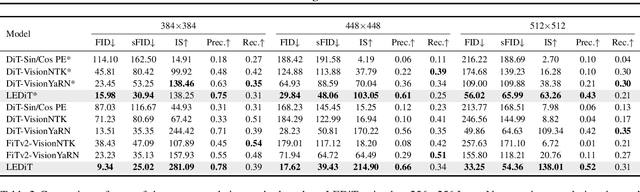
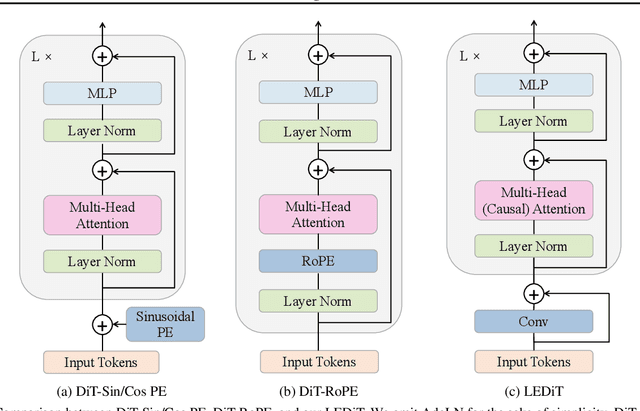
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Cascade Prompt Learning for Vision-Language Model Adaptation
Sep 26, 2024
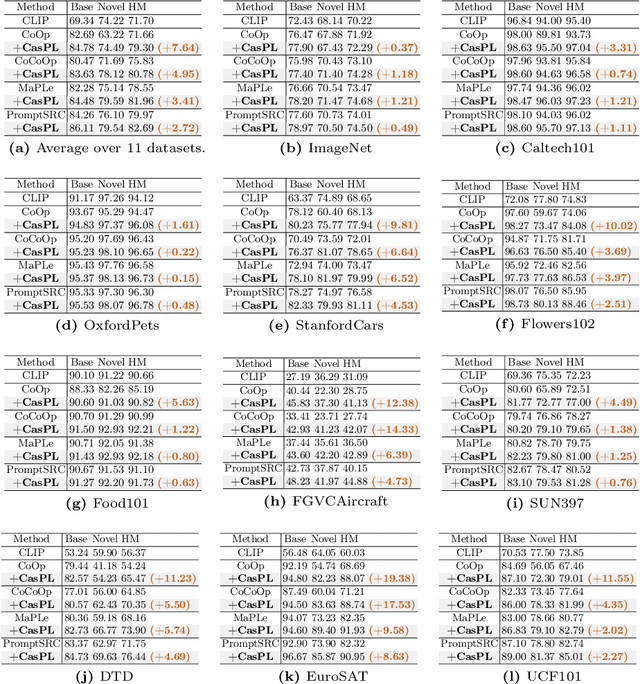
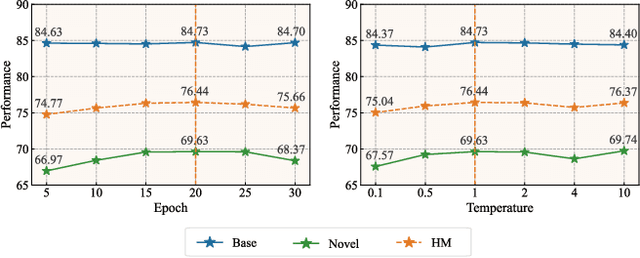

Prompt learning has surfaced as an effective approach to enhance the performance of Vision-Language Models (VLMs) like CLIP when applied to downstream tasks. However, current learnable prompt tokens are primarily used for the single phase of adapting to tasks (i.e., adapting prompt), easily leading to overfitting risks. In this work, we propose a novel Cascade Prompt Learning CasPL framework to enable prompt learning to serve both generic and specific expertise (i.e., boosting and adapting prompt) simultaneously. Specifically, CasPL is a new learning paradigm comprising two distinct phases of learnable prompts: the first boosting prompt is crafted to extract domain-general knowledge from a senior larger CLIP teacher model by aligning their predicted logits using extensive unlabeled domain images. The second adapting prompt is then cascaded with the frozen first set to fine-tune the downstream tasks, following the approaches employed in prior research. In this manner, CasPL can effectively capture both domain-general and task-specific representations into explicitly different gradual groups of prompts, thus potentially alleviating overfitting issues in the target domain. It's worth noting that CasPL serves as a plug-and-play module that can seamlessly integrate into any existing prompt learning approach. CasPL achieves a significantly better balance between performance and inference speed, which is especially beneficial for deploying smaller VLM models in resource-constrained environments. Compared to the previous state-of-the-art method PromptSRC, CasPL shows an average improvement of 1.85% for base classes, 3.44% for novel classes, and 2.72% for the harmonic mean over 11 image classification datasets. Code is publicly available at: https://github.com/megvii-research/CasPL.
A Survey of Historical Learning: Learning Models with Learning History
Mar 23, 2023



New knowledge originates from the old. The various types of elements, deposited in the training history, are a large amount of wealth for improving learning deep models. In this survey, we comprehensively review and summarize the topic--``Historical Learning: Learning Models with Learning History'', which learns better neural models with the help of their learning history during its optimization, from three detailed aspects: Historical Type (what), Functional Part (where) and Storage Form (how). To our best knowledge, it is the first survey that systematically studies the methodologies which make use of various historical statistics when training deep neural networks. The discussions with related topics like recurrent/memory networks, ensemble learning, and reinforcement learning are demonstrated. We also expose future challenges of this topic and encourage the community to pay attention to the think of historical learning principles when designing algorithms. The paper list related to historical learning is available at \url{https://github.com/Martinser/Awesome-Historical-Learning.}
Linear Array Network for Low-light Image Enhancement
Jan 22, 2022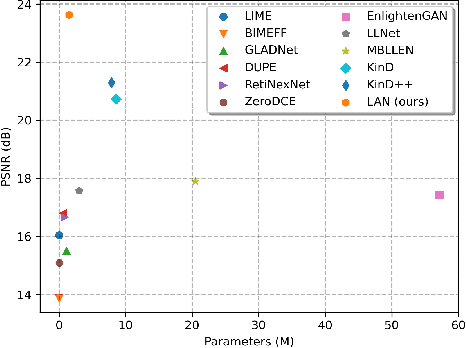
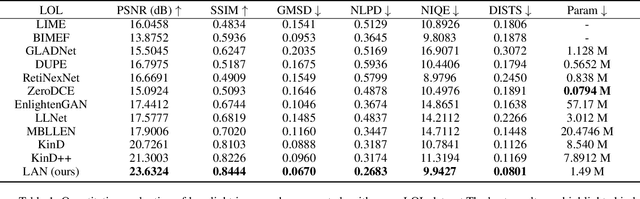
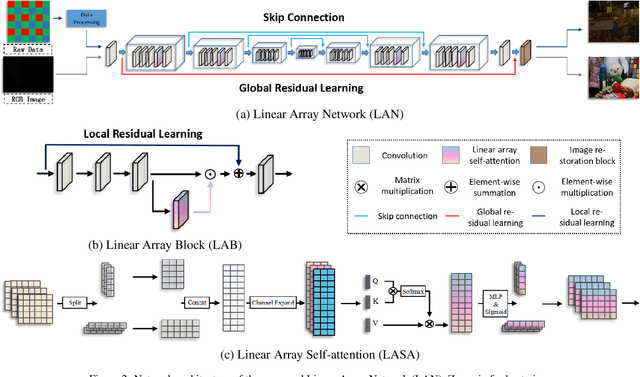
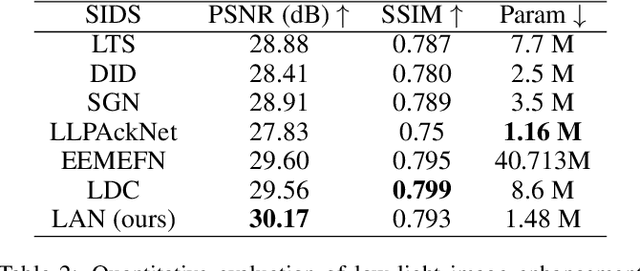
Convolution neural networks (CNNs) based methods have dominated the low-light image enhancement tasks due to their outstanding performance. However, the convolution operation is based on a local sliding window mechanism, which is difficult to construct the long-range dependencies of the feature maps. Meanwhile, the self-attention based global relationship aggregation methods have been widely used in computer vision, but these methods are difficult to handle high-resolution images because of the high computational complexity. To solve this problem, this paper proposes a Linear Array Self-attention (LASA) mechanism, which uses only two 2-D feature encodings to construct 3-D global weights and then refines feature maps generated by convolution layers. Based on LASA, Linear Array Network (LAN) is proposed, which is superior to the existing state-of-the-art (SOTA) methods in both RGB and RAW based low-light enhancement tasks with a smaller amount of parameters. The code is released in \url{https://github.com/cuiziteng/LASA_enhancement}.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020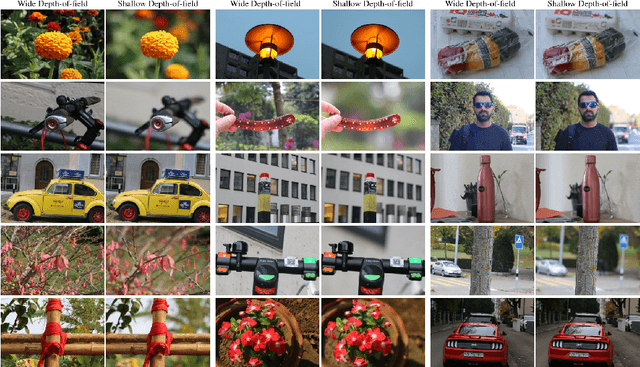


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.