 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Prompt Learning for Vision-Language Model Adaptation
Paper and Code

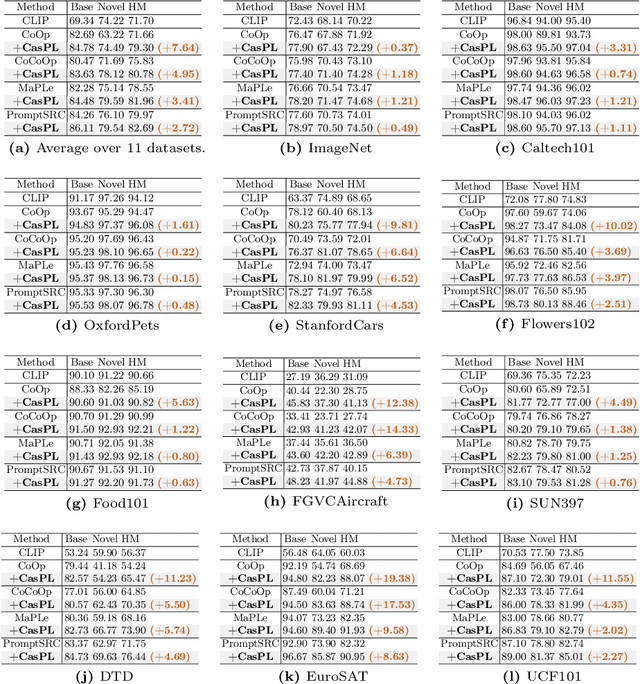
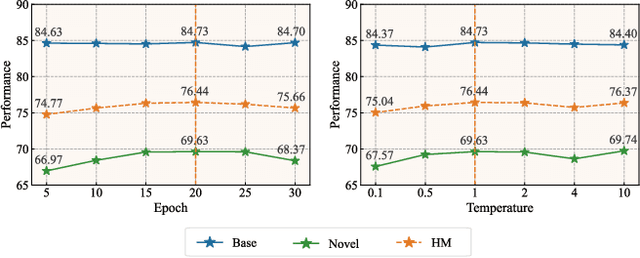

Prompt learning has surfaced as an effective approach to enhance the performance of Vision-Language Models (VLMs) like CLIP when applied to downstream tasks. However, current learnable prompt tokens are primarily used for the single phase of adapting to tasks (i.e., adapting prompt), easily leading to overfitting risks. In this work, we propose a novel Cascade Prompt Learning CasPL framework to enable prompt learning to serve both generic and specific expertise (i.e., boosting and adapting prompt) simultaneously. Specifically, CasPL is a new learning paradigm comprising two distinct phases of learnable prompts: the first boosting prompt is crafted to extract domain-general knowledge from a senior larger CLIP teacher model by aligning their predicted logits using extensive unlabeled domain images. The second adapting prompt is then cascaded with the frozen first set to fine-tune the downstream tasks, following the approaches employed in prior research. In this manner, CasPL can effectively capture both domain-general and task-specific representations into explicitly different gradual groups of prompts, thus potentially alleviating overfitting issues in the target domain. It's worth noting that CasPL serves as a plug-and-play module that can seamlessly integrate into any existing prompt learning approach. CasPL achieves a significantly better balance between performance and inference speed, which is especially beneficial for deploying smaller VLM models in resource-constrained environments. Compared to the previous state-of-the-art method PromptSRC, CasPL shows an average improvement of 1.85% for base classes, 3.44% for novel classes, and 2.72% for the harmonic mean over 11 image classification datasets. Code is publicly available at: https://github.com/megvii-research/CasPL.