 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Velocity Deficit: Initial Energy Injection for Flow Matching
May 14, 2026While Flow Matching theoretically guarantees constant-velocity trajectories, we identify a critical breakdown in high-dimensional practice: the Velocity Deficit. We show that the MSE objective systematically underestimates velocity magnitude, causing generated samples to fail to reach the data manifold-a phenomenon we term Integration Lag. To rectify this, we propose Initial Energy Injection, instantiated via two complementary methods: the training-based Magnitude-Aware Flow Matching (MAFM) and the training-free Scale Schedule Corrector (SSC). Both are grounded in our discovery of a crucial asymmetry: velocity contraction causes harmful kinetic stagnation at the trajectory's start, yet acts as a beneficial denoising mechanism at its end. Empirically, SSC yields significant efficiency gains with zero retraining and just one line of code. On ImageNet-1k (256x256), it improves FID by 44.6% (from 13.68 to 7.58) and achieves a 5x speedup, enabling a 50-step generator (FID 7.58) to beat a 250-step baseline (FID 8.65). Furthermore, our methods generalize to Text-to-Image tasks and high-resolution generation, improving FID on MS-COCO by ~22%.
Design Your Ad: Personalized Advertising Image and Text Generation with Unified Autoregressive Models
May 12, 2026Generating realistic and user-preferred advertisements is a key challenge in e-commerce. Existing approaches utilize multiple independent models driven by click-through-rate (CTR) to controllably create attractive image or text advertisements. However, their pipelines lack cross-modal perception and rely on CTR that only reflects average preferences. Therefore, we explore jointly generating personalized image-text advertisements from historical click behaviors. We first design a Unified Advertisement Generative model (Uni-AdGen) that employs a single autoregressive framework to produce both advertising images and texts. By incorporating a foreground perception module and instruction tuning, Uni-AdGen enhances the realism of the generated content. To further personalize advertisements, we equip Uni-AdGen with a coarse-to-fine preference understanding module that effectively captures user interests from noisy multimodal historical behaviors to drive personalized generation. Additionally, we construct the first large-scale Personalized Advertising image-text dataset (PAd1M) and introduce a Product Background Similarity (PBS) metric to facilitate training and evaluation. Extensive experiments show that our method outperforms baselines in general and personalized advertisement generation. Our project is available at https://github.com/JD-GenX/Uni-AdGen.
KD-CVG: A Knowledge-Driven Approach for Creative Video Generation
Apr 23, 2026Creative Generation (CG) leverages generative models to automatically produce advertising content that highlights product features, and it has been a significant focus of recent research. However, while CG has advanced considerably, most efforts have concentrated on generating advertising text and images, leaving Creative Video Generation (CVG) relatively underexplored. This gap is largely due to two major challenges faced by Text-to-Video (T2V) models: (a) \textbf{ambiguous semantic alignment}, where models struggle to accurately correlate product selling points with creative video content, and (b) \textbf{inadequate motion adaptability}, resulting in unrealistic movements and distortions. To address these challenges, we develop a comprehensive Advertising Creative Knowledge Base (ACKB) as a foundational resource and propose a knowledge-driven approach (KD-CVG) to overcome the knowledge limitations of existing models. KD-CVG consists of two primary modules: Semantic-Aware Retrieval (SAR) and Multimodal Knowledge Reference (MKR). SAR utilizes the semantic awareness of graph attention networks and reinforcement learning feedback to enhance the model's comprehension of the connections between selling points and creative videos. Building on this, MKR incorporates semantic and motion priors into the T2V model to address existing knowledge gaps. Extensive experiments have demonstrated KD-CVG's superior performance in achieving semantic alignment and motion adaptability, validating its effectiveness over other state-of-the-art methods. The code and dataset will be open source at https://kdcvg.github.io/KDCVG/.
One Size, Many Fits: Aligning Diverse Group-Wise Click Preferences in Large-Scale Advertising Image Generation
Feb 02, 2026Advertising image generation has increasingly focused on online metrics like Click-Through Rate (CTR), yet existing approaches adopt a ``one-size-fits-all" strategy that optimizes for overall CTR while neglecting preference diversity among user groups. This leads to suboptimal performance for specific groups, limiting targeted marketing effectiveness. To bridge this gap, we present \textit{One Size, Many Fits} (OSMF), a unified framework that aligns diverse group-wise click preferences in large-scale advertising image generation. OSMF begins with product-aware adaptive grouping, which dynamically organizes users based on their attributes and product characteristics, representing each group with rich collective preference features. Building on these groups, preference-conditioned image generation employs a Group-aware Multimodal Large Language Model (G-MLLM) to generate tailored images for each group. The G-MLLM is pre-trained to simultaneously comprehend group features and generate advertising images. Subsequently, we fine-tune the G-MLLM using our proposed Group-DPO for group-wise preference alignment, which effectively enhances each group's CTR on the generated images. To further advance this field, we introduce the Grouped Advertising Image Preference Dataset (GAIP), the first large-scale public dataset of group-wise image preferences, including around 600K groups built from 40M users. Extensive experiments demonstrate that our framework achieves the state-of-the-art performance in both offline and online settings. Our code and datasets will be released at https://github.com/JD-GenX/OSMF.
xGR: Efficient Generative Recommendation Serving at Scale
Dec 19, 2025Recommendation system delivers substantial economic benefits by providing personalized predictions. Generative recommendation (GR) integrates LLMs to enhance the understanding of long user-item sequences. Despite employing attention-based architectures, GR's workload differs markedly from that of LLM serving. GR typically processes long prompt while producing short, fixed-length outputs, yet the computational cost of each decode phase is especially high due to the large beam width. In addition, since the beam search involves a vast item space, the sorting overhead becomes particularly time-consuming. We propose xGR, a GR-oriented serving system that meets strict low-latency requirements under highconcurrency scenarios. First, xGR unifies the processing of prefill and decode phases through staged computation and separated KV cache. Second, xGR enables early sorting termination and mask-based item filtering with data structure reuse. Third, xGR reconstructs the overall pipeline to exploit multilevel overlap and multi-stream parallelism. Our experiments with real-world recommendation service datasets demonstrate that xGR achieves at least 3.49x throughput compared to the state-of-the-art baseline under strict latency constraints.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
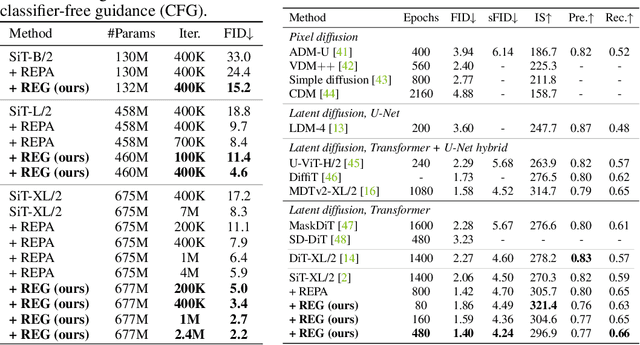
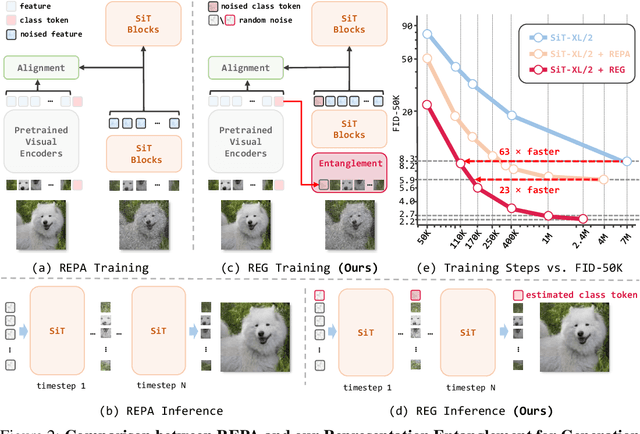
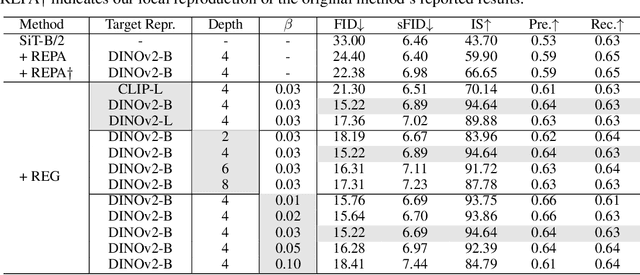
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

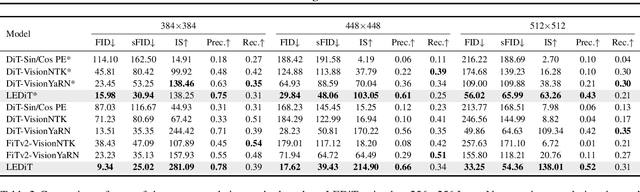
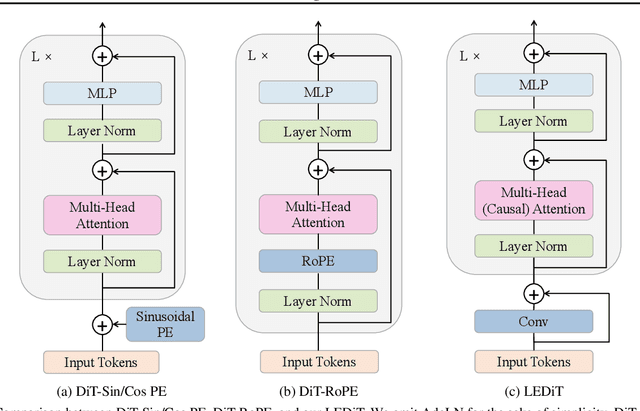
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Samsung Research China-Beijing at SemEval-2024 Task 3: A multi-stage framework for Emotion-Cause Pair Extraction in Conversations
Apr 25, 2024



In human-computer interaction, it is crucial for agents to respond to human by understanding their emotions. Unraveling the causes of emotions is more challenging. A new task named Multimodal Emotion-Cause Pair Extraction in Conversations is responsible for recognizing emotion and identifying causal expressions. In this study, we propose a multi-stage framework to generate emotion and extract the emotion causal pairs given the target emotion. In the first stage, Llama-2-based InstructERC is utilized to extract the emotion category of each utterance in a conversation. After emotion recognition, a two-stream attention model is employed to extract the emotion causal pairs given the target emotion for subtask 2 while MuTEC is employed to extract causal span for subtask 1. Our approach achieved first place for both of the two subtasks in the competition.
HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models
Nov 29, 2023We introduce HiDiffusion, a tuning-free framework comprised of Resolution-Aware U-Net (RAU-Net) and Modified Shifted Window Multi-head Self-Attention (MSW-MSA) to enable pretrained large text-to-image diffusion models to efficiently generate high-resolution images (e.g. 1024$\times$1024) that surpass the training image resolution. Pretrained diffusion models encounter unreasonable object duplication in generating images beyond the training image resolution. We attribute it to the mismatch between the feature map size of high-resolution images and the receptive field of U-Net's convolution. To address this issue, we propose a simple yet scalable method named RAU-Net. RAU-Net dynamically adjusts the feature map size to match the convolution's receptive field in the deep block of U-Net. Another obstacle in high-resolution synthesis is the slow inference speed of U-Net. Our observations reveal that the global self-attention in the top block, which exhibits locality, however, consumes the majority of computational resources. To tackle this issue, we propose MSW-MSA. Unlike previous window attention mechanisms, our method uses a much larger window size and dynamically shifts windows to better accommodate diffusion models. Extensive experiments demonstrate that our HiDiffusion can scale diffusion models to generate 1024$\times$1024, 2048$\times$2048, or even 4096$\times$4096 resolution images, while simultaneously reducing inference time by 40\%-60\%, achieving state-of-the-art performance on high-resolution image synthesis. The most significant revelation of our work is that a pretrained diffusion model on low-resolution images is scalable for high-resolution generation without further tuning. We hope this revelation can provide insights for future research on the scalability of diffusion models.
Joint Token Pruning and Squeezing Towards More Aggressive Compression of Vision Transformers
Apr 21, 2023



Although vision transformers (ViTs) have shown promising results in various computer vision tasks recently, their high computational cost limits their practical applications. Previous approaches that prune redundant tokens have demonstrated a good trade-off between performance and computation costs. Nevertheless, errors caused by pruning strategies can lead to significant information loss. Our quantitative experiments reveal that the impact of pruned tokens on performance should be noticeable. To address this issue, we propose a novel joint Token Pruning & Squeezing module (TPS) for compressing vision transformers with higher efficiency. Firstly, TPS adopts pruning to get the reserved and pruned subsets. Secondly, TPS squeezes the information of pruned tokens into partial reserved tokens via the unidirectional nearest-neighbor matching and similarity-based fusing steps. Compared to state-of-the-art methods, our approach outperforms them under all token pruning intensities. Especially while shrinking DeiT-tiny&small computational budgets to 35%, it improves the accuracy by 1%-6% compared with baselines on ImageNet classification. The proposed method can accelerate the throughput of DeiT-small beyond DeiT-tiny, while its accuracy surpasses DeiT-tiny by 4.78%. Experiments on various transformers demonstrate the effectiveness of our method, while analysis experiments prove our higher robustness to the errors of the token pruning policy. Code is available at https://github.com/megvii-research/TPS-CVPR2023.