 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDDN: A Physics-Guided Deep Learning Framework for Crowd Simulation
Apr 03, 2026Accurate crowd simulation is crucial for public safety management, emergency evacuation planning, and intelligent transportation systems. However, existing methods, which typically model crowds as a collection of independent individual trajectories, are limited in their ability to capture macroscopic physical laws. This microscopic approach often leads to error accumulation and compromises simulation stability. Furthermore, deep learning-driven methods tend to suffer from low inference efficiency and high computational overhead, making them impractical for large-scale, efficient simulations. To address these challenges, we propose the Spatio-Temporal Decoupled Differential Equation Network (STDDN), a novel framework that guides microscopic trajectory prediction with macroscopic physics. We innovatively introduce the continuity equation from fluid dynamics as a strong physical constraint. A Neural Ordinary Differential Equation (Neural ODE) is employed to model the macroscopic density evolution driven by individual movements, thereby physically regularizing the microscopic trajectory prediction model. We design a density-velocity coupled dynamic graph learning module to formulate the derivative of the density field within the Neural ODE, effectively mitigating error accumulation. We also propose a differentiable density mapping module to eliminate discontinuous gradients caused by discretization and introduce a cross-grid detection module to accurately model the impact of individual cross-grid movements on local density changes. The proposed STDDN method has demonstrated significantly superior simulation performance compared to state-of-the-art methods on long-term tasks across four real-world datasets, as well as a major reduction in inference latency.
RDPI: A Refine Diffusion Probability Generation Method for Spatiotemporal Data Imputation
Dec 17, 2024



Spatiotemporal data imputation plays a crucial role in various fields such as traffic flow monitoring, air quality assessment, and climate prediction. However, spatiotemporal data collected by sensors often suffer from temporal incompleteness, and the sparse and uneven distribution of sensors leads to missing data in the spatial dimension. Among existing methods, autoregressive approaches are prone to error accumulation, while simple conditional diffusion models fail to adequately capture the spatiotemporal relationships between observed and missing data. To address these issues, we propose a novel two-stage Refined Diffusion Probability Impuation (RDPI) framework based on an initial network and a conditional diffusion model. In the initial stage, deterministic imputation methods are used to generate preliminary estimates of the missing data. In the refinement stage, residuals are treated as the diffusion target, and observed values are innovatively incorporated into the forward process. This results in a conditional diffusion model better suited for spatiotemporal data imputation, bridging the gap between the preliminary estimates and the true values. Experiments on multiple datasets demonstrate that RDPI not only achieves state-of-the-art imputation accuracy but also significantly reduces sampling computational costs.
One-shot neural band selection for spectral recovery
May 16, 2023



Band selection has a great impact on the spectral recovery quality. To solve this ill-posed inverse problem, most band selection methods adopt hand-crafted priors or exploit clustering or sparse regularization constraints to find most prominent bands. These methods are either very slow due to the computational cost of repeatedly training with respect to different selection frequencies or different band combinations. Many traditional methods rely on the scene prior and thus are not applicable to other scenarios. In this paper, we present a novel one-shot Neural Band Selection (NBS) framework for spectral recovery. Unlike conventional searching approaches with a discrete search space and a non-differentiable search strategy, our NBS is based on the continuous relaxation of the band selection process, thus allowing efficient band search using gradient descent. To enable the compatibility for se- lecting any number of bands in one-shot, we further exploit the band-wise correlation matrices to progressively suppress similar adjacent bands. Extensive evaluations on the NTIRE 2022 Spectral Reconstruction Challenge demonstrate that our NBS achieves consistent performance gains over competitive baselines when examined with four different spectral recov- ery methods. Our code will be publicly available.
A comparative study on machine learning models combining with outlier detection and balanced sampling methods for credit scoring
Dec 25, 2021



Peer-to-peer (P2P) lending platforms have grown rapidly over the past decade as the network infrastructure has improved and the demand for personal lending has grown. Such platforms allow users to create peer-to-peer lending relationships without the help of traditional financial institutions. Assessing the borrowers' credit is crucial to reduce the default rate and benign development of P2P platforms. Building a personal credit scoring machine learning model can effectively predict whether users will repay loans on the P2P platform. And the handling of data outliers and sample imbalance problems can affect the final effect of machine learning models. There have been some studies on balanced sampling methods, but the effect of outlier detection methods and their combination with balanced sampling methods on the effectiveness of machine learning models has not been fully studied. In this paper, the influence of using different outlier detection methods and balanced sampling methods on commonly used machine learning models is investigated. Experiments on 44,487 Lending Club samples show that proper outlier detection can improve the effectiveness of the machine learning model, and the balanced sampling method only has a good effect on a few machine learning models, such as MLP.
Managing dataset shift by adversarial validation for credit scoring
Dec 19, 2021

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.
K-Core based Temporal Graph Convolutional Network for Dynamic Graphs
Mar 22, 2020
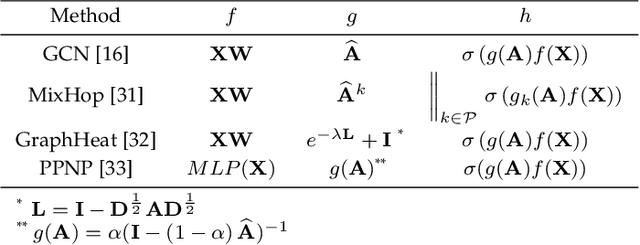
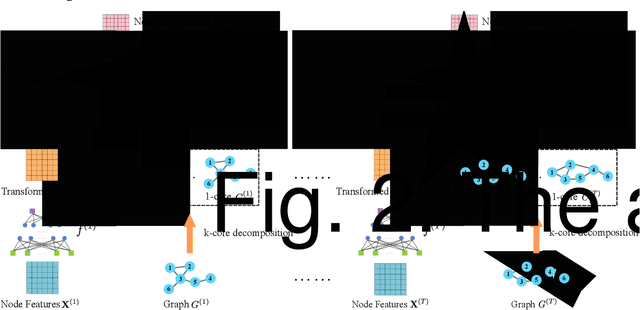

Graph representation learning is a fundamental task of various applications, aiming to learn low-dimensional embeddings for nodes which can preserve graph topology information. However, many existing methods focus on static graphs while ignoring graph evolving patterns. Inspired by the success of graph convolutional networks(GCNs) in static graph embedding, we propose a novel k-core based temporal graph convolutional network, namely CTGCN, to learn node representations for dynamic graphs. In contrast to previous dynamic graph embedding methods, CTGCN can preserve both local connective proximity and global structural similarity in a unified framework while simultaneously capturing graph dynamics. In the proposed framework, the traditional graph convolution operation is generalized into two parts: feature transformation and feature aggregation, which gives CTGCN more flexibility and enables CTGCN to learn connective and structural information under the same framework. Experimental results on 7 real-world graphs demonstrate CTGCN outperforms existing state-of-the-art graph embedding methods in several tasks, such as link prediction and structural role classification. The source code of this work can be obtained from https://github.com/jhljx/CTGCN.
An alarm prediction framework for financial IT system using hybrid machine learning methods
Jul 30, 2019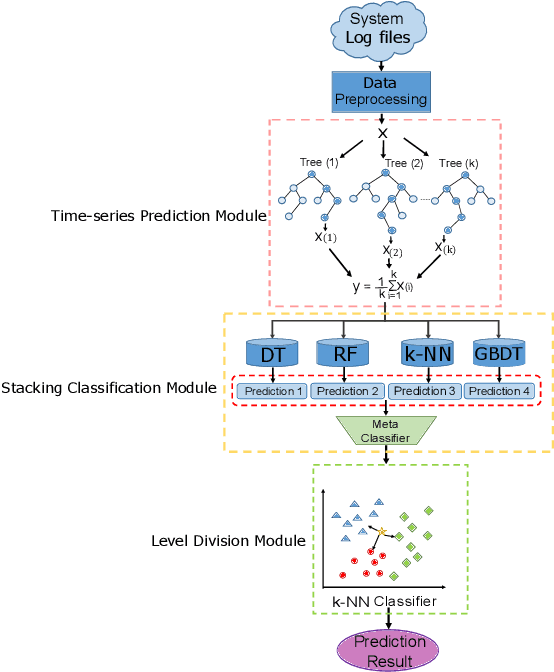
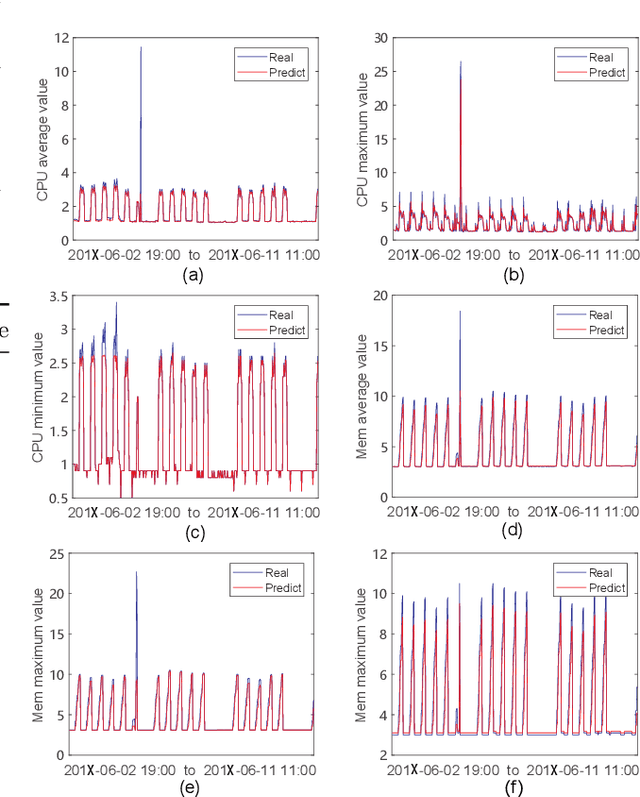
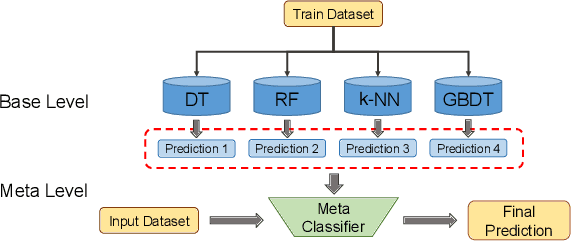
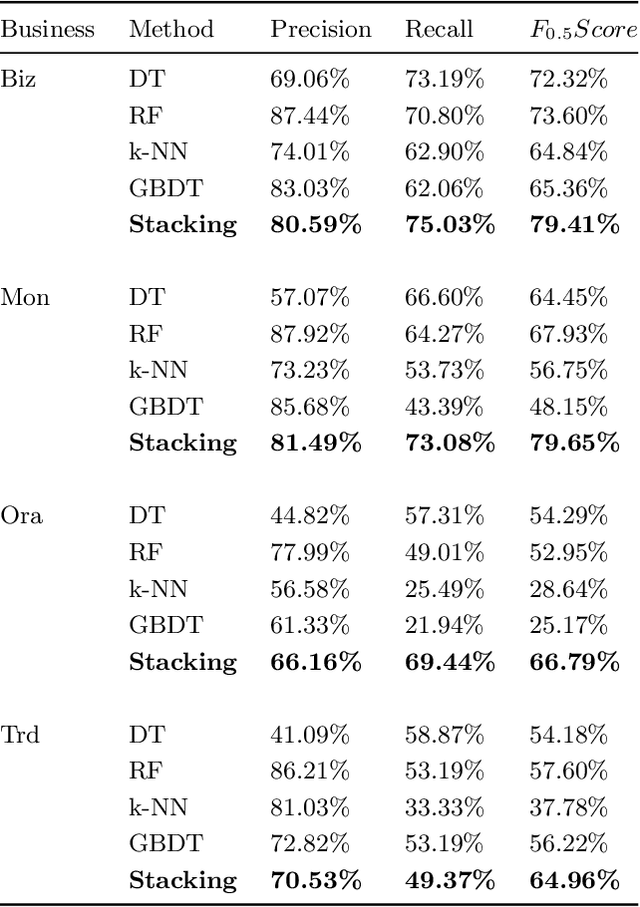
Informatization grows rapidly in all walks of life, going with the enhancement of dependence on IT systems. It is of vital importance to ensure the safe and stable running of the system especially in the field of finance. This paper puts forward a machine learning-based framework for predicting the occurrence of the alarm cases of a financial IT system. We extracted the features from the system logs then build three sub modules which are time-series prediction module, alarm classification module and level division module that composing the whole work flow. We take multiple methods to deal with the problems facing the obstacles in each module. We built the time-series prediction model in terms of time and accuracy performance. To gain higher performance, we introduced ensemble learning methods in designing alarm classifier and alleviated the class-imbalance problem in alarm level division process. The evaluation results from all sides show that our framework could be exploited for real time applications with the veracity and reliability ensured.
Unsupervised Cross-spectral Stereo Matching by Learning to Synthesize
Mar 04, 2019

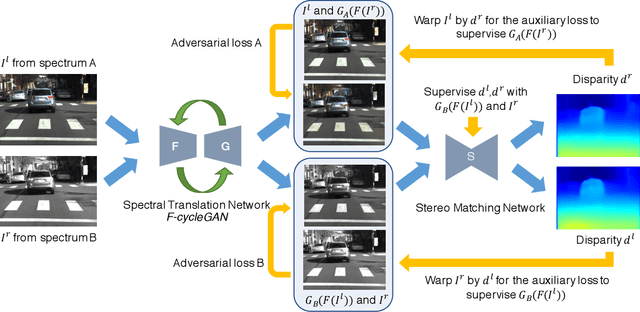
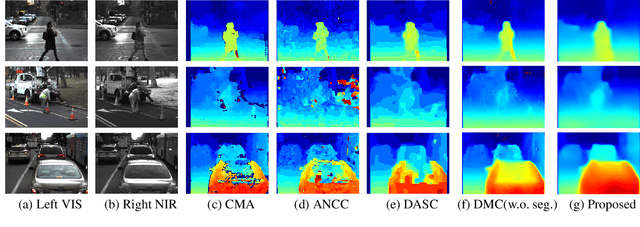
Unsupervised cross-spectral stereo matching aims at recovering disparity given cross-spectral image pairs without any supervision in the form of ground truth disparity or depth. The estimated depth provides additional information complementary to individual semantic features, which can be helpful for other vision tasks such as tracking, recognition and detection. However, there are large appearance variations between images from different spectral bands, which is a challenge for cross-spectral stereo matching. Existing deep unsupervised stereo matching methods are sensitive to the appearance variations and do not perform well on cross-spectral data. We propose a novel unsupervised cross-spectral stereo matching framework based on image-to-image translation. First, a style adaptation network transforms images across different spectral bands by cycle consistency and adversarial learning, during which appearance variations are minimized. Then, a stereo matching network is trained with image pairs from the same spectra using view reconstruction loss. At last, the estimated disparity is utilized to supervise the spectral-translation network in an end-to-end way. Moreover, a novel style adaptation network F-cycleGAN is proposed to improve the robustness of spectral translation. Our method can tackle appearance variations and enhance the robustness of unsupervised cross-spectral stereo matching. Experimental results show that our method achieves good performance without using depth supervision or explicit semantic information.