 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-RRM: Advancing Omni Reward Modeling via Automatic Rubric-Grounded Preference Synthesis
Jan 31, 2026Multimodal large language models (MLLMs) have shown remarkable capabilities, yet their performance is often capped by the coarse nature of existing alignment techniques. A critical bottleneck remains the lack of effective reward models (RMs): existing RMs are predominantly vision-centric, return opaque scalar scores, and rely on costly human annotations. We introduce \textbf{Omni-RRM}, the first open-source rubric-grounded reward model that produces structured, multi-dimension preference judgments with dimension-wise justifications across \textbf{text, image, video, and audio}. At the core of our approach is \textbf{Omni-Preference}, a large-scale dataset built via a fully automated pipeline: we synthesize candidate response pairs by contrasting models of different capabilities, and use strong teacher models to \emph{reconcile and filter} preferences while providing a modality-aware \emph{rubric-grounded rationale} for each pair. This eliminates the need for human-labeled training preferences. Omni-RRM is trained in two stages: supervised fine-tuning to learn the rubric-grounded outputs, followed by reinforcement learning (GRPO) to sharpen discrimination on difficult, low-contrast pairs. Comprehensive evaluations show that Omni-RRM achieves state-of-the-art accuracy on video (80.2\% on ShareGPT-V) and audio (66.8\% on Audio-HH-RLHF) benchmarks, and substantially outperforms existing open-source RMs on image tasks, with a 17.7\% absolute gain over its base model on overall accuracy. Omni-RRM also improves downstream performance via Best-of-$N$ selection and transfers to text-only preference benchmarks. Our data, code, and models are available at https://anonymous.4open.science/r/Omni-RRM-CC08.
S$^3$-Attention:Attention-Aligned Endogenous Retrieval for Memory-Bounded Long-Context Inference
Jan 25, 2026Large language models are increasingly applied to multi-document and long-form inputs, yet long-context inference remains memory- and noise-inefficient. Key-value (KV) caching scales linearly with context length, while external retrieval methods often return lexically similar but causally irrelevant passages. We present S3-Attention, a memory-first inference-time framework that treats long-context processing as attention-aligned endogenous retrieval. S3-Attention decodes transient key and query projections into top-k sparse feature identifiers using lightweight sparse autoencoders, and constructs a CPU-based inverted index mapping features to token positions or spans during a single streaming scan. This design allows the KV cache to be discarded entirely and bounds GPU memory usage by the scan chunk size. At generation time, feature co-activation is used to retrieve compact evidence spans, optionally fused with BM25 for exact lexical matching. Under a unified LongBench evaluation protocol with fixed prompting, decoding, and matched token budgets, S3-Hybrid closely matches full-context inference across multiple model families and improves robustness in several information-dense settings. We also report an engineering limitation of the current prototype, which incurs higher wall-clock latency than optimized full-KV baselines, motivating future kernel-level optimization.
Interpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
Dec 29, 2025Parameter-efficient fine-tuning has become the dominant paradigm for adapting large language models to downstream tasks. Low-rank adaptation methods such as LoRA operate under the assumption that task-relevant weight updates reside in a low-rank subspace, yet this subspace is learned implicitly from data in a black-box manner, offering no interpretability or direct control. We hypothesize that this difficulty stems from polysemanticity--individual dimensions encoding multiple entangled concepts. To address this, we leverage pre-trained Sparse Autoencoders (SAEs) to identify task-relevant features in a disentangled feature space, then construct an explicit, interpretable low-rank subspace to guide adapter initialization. We provide theoretical analysis proving that under monosemanticity assumptions, SAE-based subspace identification achieves arbitrarily small recovery error, while direct identification in polysemantic space suffers an irreducible error floor. On safety alignment, our method achieves up to 99.6% safety rate--exceeding full fine-tuning by 7.4 percentage points and approaching RLHF-based methods--while updating only 0.19-0.24% of parameters. Crucially, our method provides interpretable insights into the learned alignment subspace through the semantic grounding of SAE features. Our work demonstrates that incorporating mechanistic interpretability into the fine-tuning process can simultaneously improve both performance and transparency.
CIP: A Plug-and-Play Causal Prompting Framework for Mitigating Hallucinations under Long-Context Noise
Dec 12, 2025


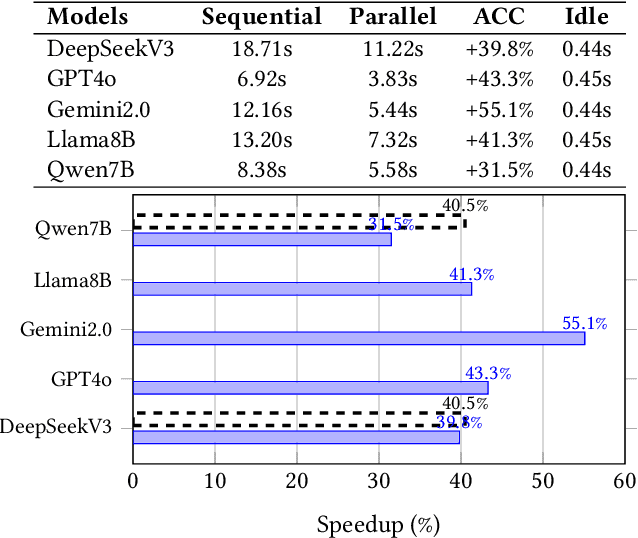
Large language models often hallucinate when processing long and noisy retrieval contexts because they rely on spurious correlations rather than genuine causal relationships. We propose CIP, a lightweight and plug-and-play causal prompting framework that mitigates hallucinations at the input stage. CIP constructs a causal relation sequence among entities, actions, and events and injects it into the prompt to guide reasoning toward causally relevant evidence. Through causal intervention and counterfactual reasoning, CIP suppresses non causal reasoning paths, improving factual grounding and interpretability. Experiments across seven mainstream language models, including GPT-4o, Gemini 2.0 Flash, and Llama 3.1, show that CIP consistently enhances reasoning quality and reliability, achieving 2.6 points improvement in Attributable Rate, 0.38 improvement in Causal Consistency Score, and a fourfold increase in effective information density. API level profiling further shows that CIP accelerates contextual understanding and reduces end to end response latency by up to 55.1 percent. These results suggest that causal reasoning may serve as a promising paradigm for improving the explainability, stability, and efficiency of large language models.
Unlocking the Address Book: Dissecting the Sparse Semantic Structure of LLM Key-Value Caches via Sparse Autoencoders
Dec 11, 2025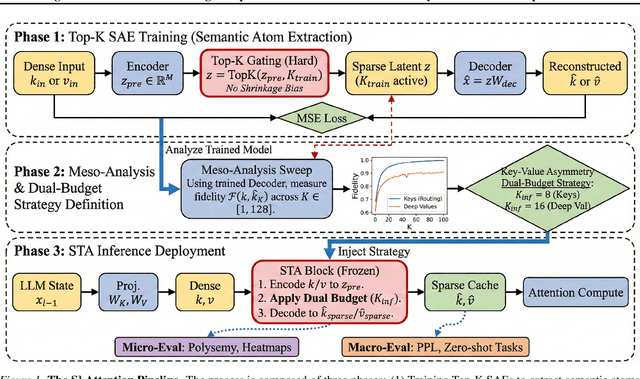

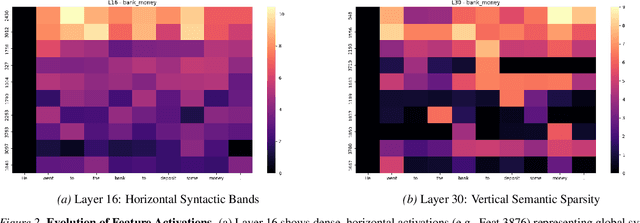

The Key-Value (KV) cache is the primary memory bottleneck in long-context Large Language Models, yet it is typically treated as an opaque numerical tensor. In this work, we propose \textbf{STA-Attention}, a framework that utilizes Top-K Sparse Autoencoders (SAEs) to decompose the KV cache into interpretable ``semantic atoms.'' Unlike standard $L_1$-regularized SAEs, our Top-K approach eliminates shrinkage bias, preserving the precise dot-product geometry required for attention. Our analysis uncovers a fundamental \textbf{Key-Value Asymmetry}: while Key vectors serve as highly sparse routers dominated by a ``Semantic Elbow,'' deep Value vectors carry dense content payloads requiring a larger budget. Based on this structure, we introduce a Dual-Budget Strategy that selectively preserves the most informative semantic components while filtering representational noise. Experiments on Yi-6B, Mistral-7B, Qwen2.5-32B, and others show that our semantic reconstructions maintain perplexity and zero-shot performance comparable to the original models, effectively bridging the gap between mechanistic interpretability and faithful attention modeling.
BSS-Bench: Towards Reproducible and Effective Band Selection Search
Dec 22, 2023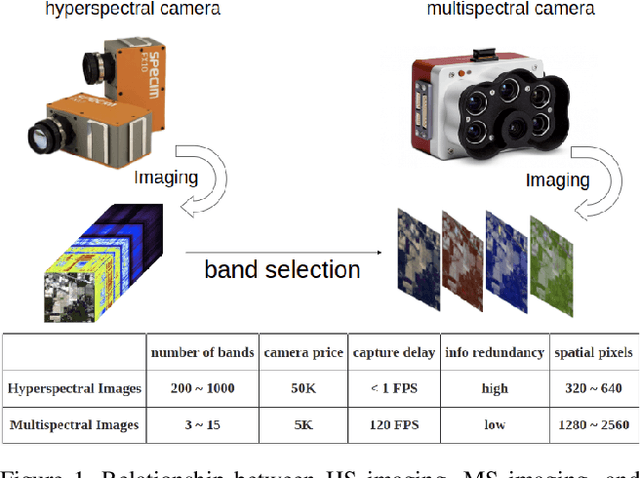
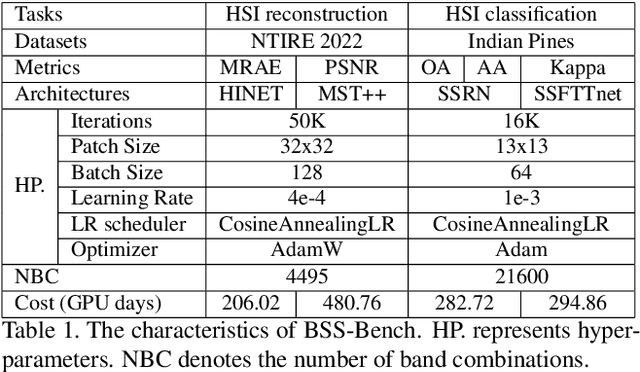
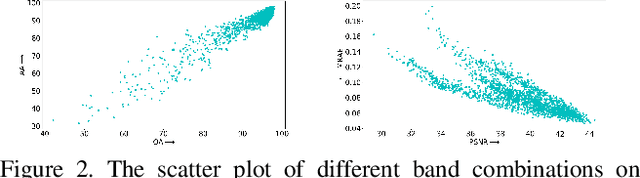

The key technology to overcome the drawbacks of hyperspectral imaging (expensive, high capture delay, and low spatial resolution) and make it widely applicable is to select only a few representative bands from hundreds of bands. However, current band selection (BS) methods face challenges in fair comparisons due to inconsistent train/validation settings, including the number of bands, dataset splits, and retraining settings. To make BS methods easy and reproducible, this paper presents the first band selection search benchmark (BSS-Bench) containing 52k training and evaluation records of numerous band combinations (BC) with different backbones for various hyperspectral analysis tasks. The creation of BSS-Bench required a significant computational effort of 1.26k GPU days. By querying BSS-Bench, BS experiments can be performed easily and reproducibly, and the gap between the searched result and the best achievable performance can be measured. Based on BSS-Bench, we further discuss the impact of various factors on BS, such as the number of bands, unsupervised statistics, and different backbones. In addition to BSS-Bench, we present an effective one-shot BS method called Single Combination One Shot (SCOS), which learns the priority of any BCs through one-time training, eliminating the need for repetitive retraining on different BCs. Furthermore, the search process of SCOS is flexible and does not require training, making it efficient and effective. Our extensive evaluations demonstrate that SCOS outperforms current BS methods on multiple tasks, even with much fewer bands. Our BSS-Bench and codes are available in the supplementary material and will be publicly available.
A Solution to Co-occurrence Bias: Attributes Disentanglement via Mutual Information Minimization for Pedestrian Attribute Recognition
Jul 28, 2023Recent studies on pedestrian attribute recognition progress with either explicit or implicit modeling of the co-occurrence among attributes. Considering that this known a prior is highly variable and unforeseeable regarding the specific scenarios, we show that current methods can actually suffer in generalizing such fitted attributes interdependencies onto scenes or identities off the dataset distribution, resulting in the underlined bias of attributes co-occurrence. To render models robust in realistic scenes, we propose the attributes-disentangled feature learning to ensure the recognition of an attribute not inferring on the existence of others, and which is sequentially formulated as a problem of mutual information minimization. Rooting from it, practical strategies are devised to efficiently decouple attributes, which substantially improve the baseline and establish state-of-the-art performance on realistic datasets like PETAzs and RAPzs. Code is released on https://github.com/SDret/A-Solution-to-Co-occurence-Bias-in-Pedestrian-Attribute-Recognition.
One-shot neural band selection for spectral recovery
May 16, 2023



Band selection has a great impact on the spectral recovery quality. To solve this ill-posed inverse problem, most band selection methods adopt hand-crafted priors or exploit clustering or sparse regularization constraints to find most prominent bands. These methods are either very slow due to the computational cost of repeatedly training with respect to different selection frequencies or different band combinations. Many traditional methods rely on the scene prior and thus are not applicable to other scenarios. In this paper, we present a novel one-shot Neural Band Selection (NBS) framework for spectral recovery. Unlike conventional searching approaches with a discrete search space and a non-differentiable search strategy, our NBS is based on the continuous relaxation of the band selection process, thus allowing efficient band search using gradient descent. To enable the compatibility for se- lecting any number of bands in one-shot, we further exploit the band-wise correlation matrices to progressively suppress similar adjacent bands. Extensive evaluations on the NTIRE 2022 Spectral Reconstruction Challenge demonstrate that our NBS achieves consistent performance gains over competitive baselines when examined with four different spectral recov- ery methods. Our code will be publicly available.
Segment as Points for Efficient Online Multi-Object Tracking and Segmentation
Jul 03, 2020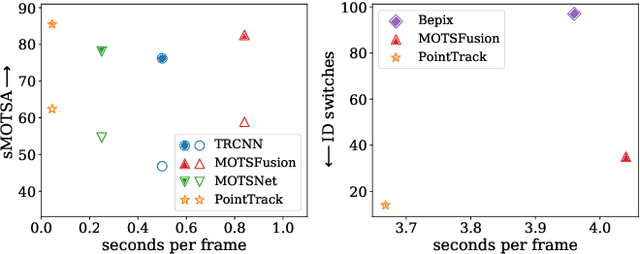

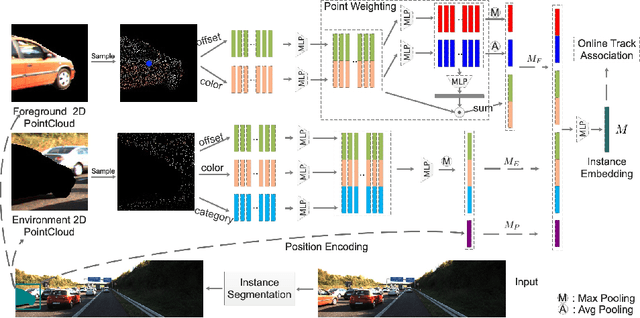
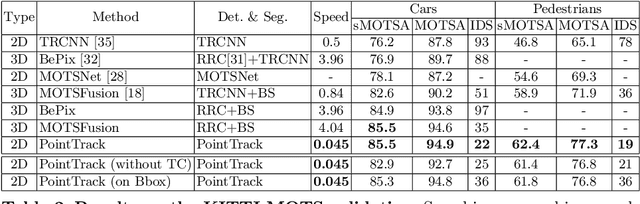
Current multi-object tracking and segmentation (MOTS) methods follow the tracking-by-detection paradigm and adopt convolutions for feature extraction. However, as affected by the inherent receptive field, convolution based feature extraction inevitably mixes up the foreground features and the background features, resulting in ambiguities in the subsequent instance association. In this paper, we propose a highly effective method for learning instance embeddings based on segments by converting the compact image representation to un-ordered 2D point cloud representation. Our method generates a new tracking-by-points paradigm where discriminative instance embeddings are learned from randomly selected points rather than images. Furthermore, multiple informative data modalities are converted into point-wise representations to enrich point-wise features. The resulting online MOTS framework, named PointTrack, surpasses all the state-of-the-art methods including 3D tracking methods by large margins (5.4% higher MOTSA and 18 times faster over MOTSFusion) with the near real-time speed (22 FPS). Evaluations across three datasets demonstrate both the effectiveness and efficiency of our method. Moreover, based on the observation that current MOTS datasets lack crowded scenes, we build a more challenging MOTS dataset named APOLLO MOTS with higher instance density. Both APOLLO MOTS and our codes are publicly available at https://github.com/detectRecog/PointTrack.
PointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Jul 03, 2020
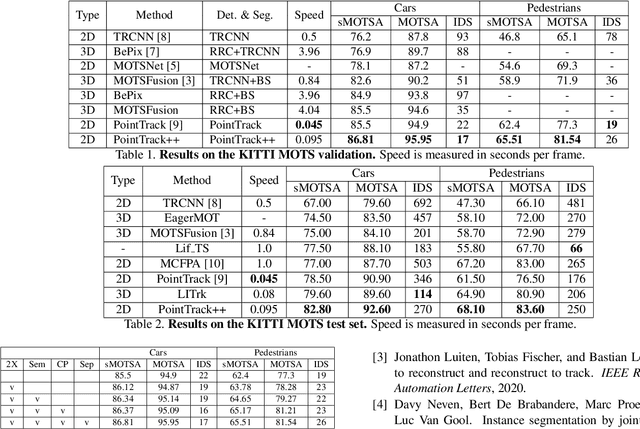
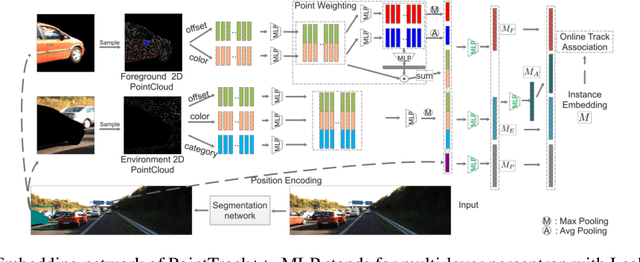
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.