 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Spurious Correlation Removal Always Learnable?
Jun 11, 2026Invariant learning can fail even when the invariant structure is statistically identifiable. We show a conditional computational barrier: under a black-box samplable supervised sparse recovery primitive motivated by average-case sparse-recovery reductions, there exist \emph{samplable} multi-environment instances with a one-dimensional predictive invariant subspace ($k=1$) that are learnable with polynomial samples by exhaustive search, while any polynomial-time constant-accuracy recovery algorithm would contradict the primitive. We further quantify environment diversity by a separation parameter $γ$, which controls identifiability and the curvature of invariance objectives. Under sufficient diversity and local Gaussian regularity, the minimax risk is $\mathbb{E}[\dist(\hat{V},V_{\mathrm{inv}})^2]=Θ(k(d-k)/(n|\mathcal{E}|))$, and under label-induced shifts a phase transition occurs at $n^*\propto k(d-k)/(|\mathcal{E}|γ^2)$ with refined estimation error scaling proportional to $1/γ^2$. Synthetic and real datasets illustrate the predicted gaps and transitions and motivate simple diversity diagnostics.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Pedestrian Attribute Recognition as Label-balanced Multi-label Learning
May 08, 2024



Rooting in the scarcity of most attributes, realistic pedestrian attribute datasets exhibit unduly skewed data distribution, from which two types of model failures are delivered: (1) label imbalance: model predictions lean greatly towards the side of majority labels; (2) semantics imbalance: model is easily overfitted on the under-represented attributes due to their insufficient semantic diversity. To render perfect label balancing, we propose a novel framework that successfully decouples label-balanced data re-sampling from the curse of attributes co-occurrence, i.e., we equalize the sampling prior of an attribute while not biasing that of the co-occurred others. To diversify the attributes semantics and mitigate the feature noise, we propose a Bayesian feature augmentation method to introduce true in-distribution novelty. Handling both imbalances jointly, our work achieves best accuracy on various popular benchmarks, and importantly, with minimal computational budget.
A Solution to Co-occurrence Bias: Attributes Disentanglement via Mutual Information Minimization for Pedestrian Attribute Recognition
Jul 28, 2023Recent studies on pedestrian attribute recognition progress with either explicit or implicit modeling of the co-occurrence among attributes. Considering that this known a prior is highly variable and unforeseeable regarding the specific scenarios, we show that current methods can actually suffer in generalizing such fitted attributes interdependencies onto scenes or identities off the dataset distribution, resulting in the underlined bias of attributes co-occurrence. To render models robust in realistic scenes, we propose the attributes-disentangled feature learning to ensure the recognition of an attribute not inferring on the existence of others, and which is sequentially formulated as a problem of mutual information minimization. Rooting from it, practical strategies are devised to efficiently decouple attributes, which substantially improve the baseline and establish state-of-the-art performance on realistic datasets like PETAzs and RAPzs. Code is released on https://github.com/SDret/A-Solution-to-Co-occurence-Bias-in-Pedestrian-Attribute-Recognition.
BVIP Guiding System with Adaptability to Individual Differences
Apr 15, 2023Guiding robots can not only detect close-range obstacles like other guiding tools, but also extend its range to perceive the environment when making decisions. However, most existing works over-simplified the interaction between human agents and robots, ignoring the differences between individuals, resulting in poor experiences for different users. To solve the problem, we propose a data-driven guiding system to cope with the effect brighten by individual differences. In our guiding system, we design a Human Motion Predictor (HMP) and a Robot Dynamics Model (RDM) based on deep neural network, the time convolutional network (TCN) is verified to have the best performance, to predict differences in interaction between different human agents and robots. To train our models, we collected datasets that records the interactions from different human agents. Moreover, given the predictive information of the specific user, we propose a waypoints selector that allows the robot to naturally adapt to the user's state changes, which are mainly reflected in the walking speed. We compare the performance of our models with previous works and achieve significant performance improvements. On this basis, our guiding system demonstrated good adaptability to different human agents. Our guiding system is deployed on a real quadruped robot to verify the practicability.
Rethinking Reconstruction Autoencoder-Based Out-of-Distribution Detection
Apr 13, 2022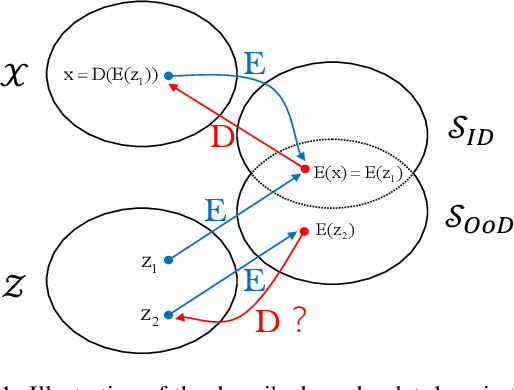
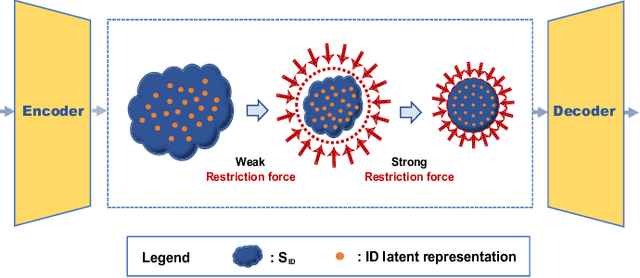
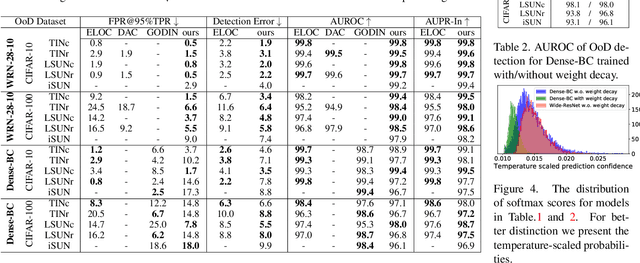
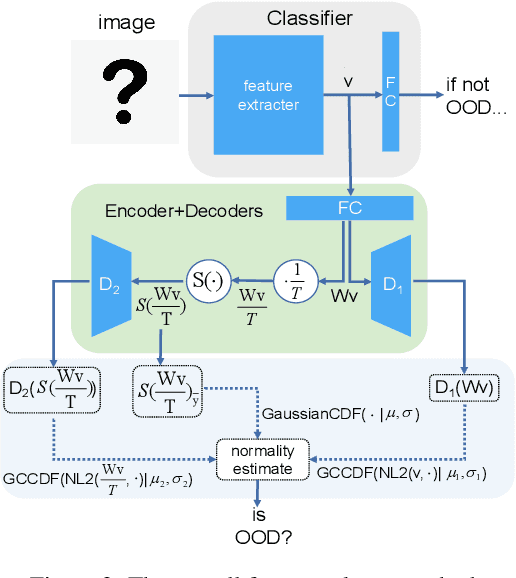
In some scenarios, classifier requires detecting out-of-distribution samples far from its training data. With desirable characteristics, reconstruction autoencoder-based methods deal with this problem by using input reconstruction error as a metric of novelty vs. normality. We formulate the essence of such approach as a quadruplet domain translation with an intrinsic bias to only query for a proxy of conditional data uncertainty. Accordingly, an improvement direction is formalized as maximumly compressing the autoencoder's latent space while ensuring its reconstructive power for acting as a described domain translator. From it, strategies are introduced including semantic reconstruction, data certainty decomposition and normalized L2 distance to substantially improve original methods, which together establish state-of-the-art performance on various benchmarks, e.g., the FPR@95%TPR of CIFAR-100 vs. TinyImagenet-crop on Wide-ResNet is 0.2%. Importantly, our method works without any additional data, hard-to-implement structure, time-consuming pipeline, and even harming the classification accuracy of known classes.
* Accepted('Poster' presentation) as main conference paper of CVPR2022