 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Economically: A Hierarchical Framework for Adaptive-Complexity Reasoning in LLMs
May 31, 2026Chain-of-Thought (CoT) has significantly enhanced LLM reasoning, yet often incurs substantial computational overhead due to "overthinking": generating excessively long rationales without commensurate accuracy gains. Existing efficiency methods typically apply uniform compression, which overlooks a critical observation that reasoning complexity is heterogeneous at two distinct granularity: across different problems and within individual reasoning steps. This motivates our principle of Thinking Economically: intelligently allocating computational resources based on intrinsic task and step demands rather than pursuing uniform brevity. We propose Hierarchical Adaptive Budgeter (HAB), a training framework that operationalizes this principle through coarse-to-fine budgeting. At the inter-step level, HAB predicts the optimal reasoning depth for each problem. At the intra-step level, HAB learns step-specific token budgeting signals from PPL-derived step comparisons and an adaptive Pareto optimization objective that captures the local quality-efficiency trade-off, while a Fisher Information-based pruner further provides fine-grained training-time guidance, thereby encouraging the generator to internalize more economical reasoning patterns. Experiments on GSM8K and MATH500 show that HAB not only surpasses standard CoT in accuracy but also reduces token usage, achieving a stronger performance-efficiency trade-off than the compared baselines.
TouchAnything: A Dataset and Framework for Bimanual Tactile Estimation from Egocentric Video
May 13, 2026Egocentric human video data, which captures rich human-environment interactions and can be collected at scale, has become a key driver of embodied intelligence research. However, existing egocentric datasets typically lack tactile sensing, a critical modality that provides direct cues about contact, force, and pressure in human-object interaction. Without such signals, models struggle to learn physically grounded representations of real-world interaction dynamics. While tactile sensors provide these cues, deploying high-quality tactile hardware at scale remains expensive and cumbersome. This raises a central question: can tactile feedback be inferred directly from visual observations, enabling scalable tactile supervision for egocentric video data and supporting physically grounded embodied learning? To enable research in this direction, we introduce EgoTouch, a large-scale multi-view egocentric dataset with dense tactile supervision for bimanual hand-object interaction. EgoTouch comprises 208 manipulation tasks spanning 1,891 episodes in diverse indoor and outdoor environments, with synchronized multi-view RGB (head-mounted egocentric and dual wrist-mounted cameras), bimanual 3D hand pose, and continuous pressure maps from wearable tactile sensors. Building on EgoTouch, we introduce TouchAnything, a baseline multi-view vision-to-touch prediction framework that uses the egocentric view as the primary input and flexibly leverages available wrist-mounted views at inference time. Experiments show that incorporating wrist-mounted views generally improves tactile prediction over egocentric-only input, achieving up to 5.0% relative improvement in Contact IoU and 6.1% relative improvement in Volumetric IoU. We will publicly release the dataset, code, and benchmark.
DataMaster: Towards Autonomous Data Engineering for Machine Learning
May 11, 2026As model families, training recipes, and compute budgets become increasingly standardized, further gains in machine learning systems depend increasingly on data. Yet data engineering remains largely manual and ad hoc: practitioners repeatedly search for external datasets, adapt them to existing pipelines, validate candidate data through downstream training, and carry forward lessons from prior attempts. We study task-conditioned autonomous data engineering, where an autonomous agent improves a fixed learning algorithm by optimizing only the data side, including external data discovery, data selection and composition, cleaning and transformation. The goal is to obtain a stronger downstream solution while leaving the learning algorithm unchanged. To address the open-ended search space, branch-dependent refinement, and delayed validation inherent in autonomous data engineering, we propose DataMaster, a data-agent framework that integrates tree-structured search, shared candidate data, and cumulative memory. DataMaster consists of three key components: a DataTree that organizes alternative data-engineering branches, a shared Data Pool that stores discovered external data sources for reuse, and a Global Memory that records node outcomes, artifacts, and reusable findings. Together, these components allow the agent to discover candidate data, construct executable training inputs, evaluate them through downstream feedback, and carry useful evidence across branches. We evaluate DataMaster on two types of benchmarks, MLE-Bench Lite and PostTrainBench. On MLE-Bench Lite, it improves medal rate by 32.27% over the initial score; on PostTrainBench, it surpasses the instruct model on GPQA (31.02% vs 30.35%).
M3D-Net: Multi-Modal 3D Facial Feature Reconstruction Network for Deepfake Detection
Apr 16, 2026With the rapid advancement of deep learning in image generation, facial forgery techniques have achieved unprecedented realism, posing serious threats to cybersecurity and information authenticity. Most existing deepfake detection approaches rely on the reconstruction of isolated facial attributes without fully exploiting the complementary nature of multi-modal feature representations. To address these challenges, this paper proposes a novel Multi-Modal 3D Facial Feature Reconstruction Network (M3D-Net) for deepfake detection. Our method leverages an end-to-end dual-stream architecture that reconstructs fine-grained facial geometry and reflectance properties from single-view RGB images via a self-supervised 3D facial reconstruction module. The network further enhances detection performance through a 3D Feature Pre-fusion Module (PFM), which adaptively adjusts multi-scale features, and a Multi-modal Fusion Module (MFM) that effectively integrates RGB and 3D-reconstructed features using attention mechanisms. Extensive experiments on multiple public datasets demonstrate that our approach achieves state-of-the-art performance in terms of detection accuracy and robustness, significantly outperforming existing methods while exhibiting strong generalization across diverse scenarios.
ACE-Merging: Data-Free Model Merging with Adaptive Covariance Estimation
Mar 03, 2026Model merging aims to combine multiple task-specific expert models into a single model while preserving generalization across diverse tasks. However, interference among experts, especially when they are trained on different objectives, often leads to significant performance degradation. Despite recent progress, resolving this interference without data access, retraining, or architectural modification remains a fundamental challenge. This paper provides a theoretical analysis demonstrating that the input covariance of each task, which is a key factor for optimal merging, can be implicitly estimated from the parameter differences of its fine-tuned model, even in a fully data-free setting. Building on this insight, we introduce \acem, an Adaptive Covariance Estimation framework that effectively mitigates inter-task interference. Our approach features a principled, closed-form solution that contrasts with prior iterative or heuristic methods. Extensive experiments on both vision and language benchmarks demonstrate that \acem sets a new state-of-the-art among data-free methods. It consistently outperforms existing baselines; for example, \acem achieves an average absolute improvement of 4\% over the previous methods across seven tasks on GPT-2. Owing to its efficient closed-form formulation, \acem delivers superior performance with a modest computational cost, providing a practical and theoretically grounded solution for model merging.
Diffusion-aided Extreme Video Compression with Lightweight Semantics Guidance
Feb 05, 2026Modern video codecs and learning-based approaches struggle for semantic reconstruction at extremely low bit-rates due to reliance on low-level spatiotemporal redundancies. Generative models, especially diffusion models, offer a new paradigm for video compression by leveraging high-level semantic understanding and powerful visual synthesis. This paper propose a video compression framework that integrates generative priors to drastically reduce bit-rate while maintaining reconstruction fidelity. Specifically, our method compresses high-level semantic representations of the video, then uses a conditional diffusion model to reconstruct frames from these semantics. To further improve compression, we characterize motion information with global camera trajectories and foreground segmentation: background motion is compactly represented by camera pose parameters while foreground dynamics by sparse segmentation masks. This allows for significantly boosts compression efficiency, enabling descent video reconstruction at extremely low bit-rates.
Tracking the Limits of Knowledge Propagation: How LLMs Fail at Multi-Step Reasoning with Conflicting Knowledge
Jan 21, 2026A common solution for mitigating outdated or incorrect information in Large Language Models (LLMs) is to provide updated facts in-context or through knowledge editing. However, these methods introduce knowledge conflicts when the knowledge update fails to overwrite the model's parametric knowledge, which propagate to faulty reasoning. Current benchmarks for this problem, however, largely focus only on single knowledge updates and fact recall without evaluating how these updates affect downstream reasoning. In this work, we introduce TRACK (Testing Reasoning Amid Conflicting Knowledge), a new benchmark for studying how LLMs propagate new knowledge through multi-step reasoning when it conflicts with the model's initial parametric knowledge. Spanning three reasoning-intensive scenarios (WIKI, CODE, and MATH), TRACK introduces multiple, realistic conflicts to mirror real-world complexity. Our results on TRACK reveal that providing updated facts to models for reasoning can worsen performance compared to providing no updated facts to a model, and that this performance degradation exacerbates as more updated facts are provided. We show this failure stems from both inability to faithfully integrate updated facts, but also flawed reasoning even when knowledge is integrated. TRACK provides a rigorous new benchmark to measure and guide future progress on propagating conflicting knowledge in multi-step reasoning.
Leveraging Overfitting for Low-Complexity and Modality-Agnostic Joint Source-Channel Coding
Dec 24, 2025This paper introduces Implicit-JSCC, a novel overfitted joint source-channel coding paradigm that directly optimizes channel symbols and a lightweight neural decoder for each source. This instance-specific strategy eliminates the need for training datasets or pre-trained models, enabling a storage-free, modality-agnostic solution. As a low-complexity alternative, Implicit-JSCC achieves efficient image transmission with around 1000x lower decoding complexity, using as few as 607 model parameters and 641 multiplications per pixel. This overfitted design inherently addresses source generalizability and achieves state-of-the-art results in the high SNR regimes, underscoring its promise for future communication systems, especially streaming scenarios where one-time offline encoding supports multiple online decoding.
Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views
Dec 15, 2025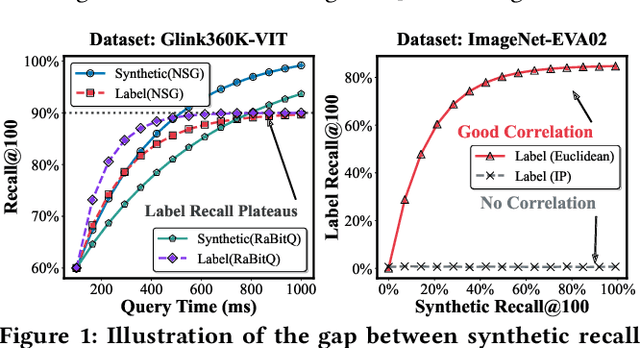

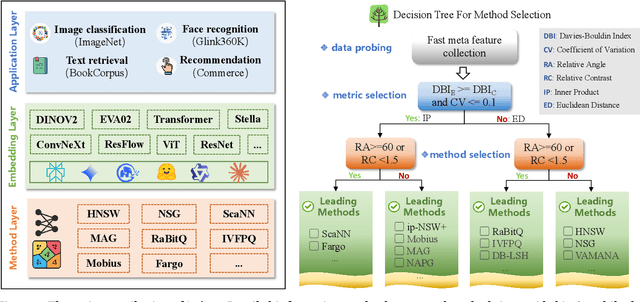
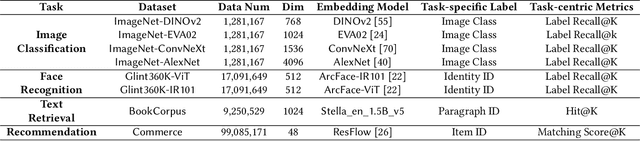
Vector Similarity Search (VSS) in high-dimensional spaces is rapidly emerging as core functionality in next-generation database systems for numerous data-intensive services -- from embedding lookups in large language models (LLMs), to semantic information retrieval and recommendation engines. Current benchmarks, however, evaluate VSS primarily on the recall-latency trade-off against a ground truth defined solely by distance metrics, neglecting how retrieval quality ultimately impacts downstream tasks. This disconnect can mislead both academic research and industrial practice. We present Iceberg, a holistic benchmark suite for end-to-end evaluation of VSS methods in realistic application contexts. From a task-centric view, Iceberg uncovers the Information Loss Funnel, which identifies three principal sources of end-to-end performance degradation: (1) Embedding Loss during feature extraction; (2) Metric Misuse, where distances poorly reflect task relevance; (3) Data Distribution Sensitivity, highlighting index robustness across skews and modalities. For a more comprehensive assessment, Iceberg spans eight diverse datasets across key domains such as image classification, face recognition, text retrieval, and recommendation systems. Each dataset, ranging from 1M to 100M vectors, includes rich, task-specific labels and evaluation metrics, enabling assessment of retrieval algorithms within the full application pipeline rather than in isolation. Iceberg benchmarks 13 state-of-the-art VSS methods and re-ranks them based on application-level metrics, revealing substantial deviations from traditional rankings derived purely from recall-latency evaluations. Building on these insights, we define a set of task-centric meta-features and derive an interpretable decision tree to guide practitioners in selecting and tuning VSS methods for their specific workloads.
EffiReason-Bench: A Unified Benchmark for Evaluating and Advancing Efficient Reasoning in Large Language Models
Nov 13, 2025



Large language models (LLMs) with Chain-of-Thought (CoT) prompting achieve strong reasoning but often produce unnecessarily long explanations, increasing cost and sometimes reducing accuracy. Fair comparison of efficiency-oriented approaches is hindered by fragmented evaluation practices. We introduce EffiReason-Bench, a unified benchmark for rigorous cross-paradigm evaluation of efficient reasoning methods across three categories: Reasoning Blueprints, Dynamic Execution, and Post-hoc Refinement. To enable step-by-step evaluation, we construct verified CoT annotations for CommonsenseQA and LogiQA via a pipeline that enforces standardized reasoning structures, comprehensive option-wise analysis, and human verification. We evaluate 7 methods across 6 open-source LLMs (1B-70B) on 4 datasets spanning mathematics, commonsense, and logic, and propose the E3-Score, a principled metric inspired by economic trade-off modeling that provides smooth, stable evaluation without discontinuities or heavy reliance on heuristics. Experiments show that no single method universally dominates; optimal strategies depend on backbone scale, task complexity, and architecture.