 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Sensing and Covert Communications in RIS-NOMA Systems
Mar 27, 2026A reconfigurable intelligent surface (RIS)-assisted non-orthogonal multiple access (NOMA) system is investigated, where the transmitter (Alice) is a dual functional radar communication (DFRC) base station (BS) that aims to sense the location of a potential warden (Willie), while simultaneously transmitting public and covert signals to the legitimate users, Carol and Bob, respectively. Both cases of known and unknown Willie locations are considered. For the known-location case, assuming perfect channel state information (CSI) at Willie, a covert rate maximization is formulated with the joint optimization of active and passive beamforming, which is solved using successive convex approximation (SCA), penalty method, and semidefinite relaxation (SDR). For the unknown-location case, we propose to estimate Willie's location via radar sensing and develop a sensing-based imperfect CSI model. In particular, the CSI error uncertainty is bounded by the sensing accuracy, which is characterized by the Cramer-Rao bound (CRB). Subsequently, a robust communication rate maximization problem is formulated under the constraints on quality-of-service (QoS) of Carol, sensing accuracy, and covertness level. The Schur complement and S-procedure are employed to handle the non-convex constraints. Numerical results compare the system performance under the two cases, and demonstrate the significant covert performance superiority of the sensing-based imperfect CSI model and NOMA over the general norm-bounded imperfect CSI model and the orthogonal multiple access scheme. Furthermore, the dual yet contradictory effects of sensing on covert communications are revealed. It is also found that Alice primarily utilizes Carol's signal for sensing, while allocating almost all of Bob's signal for communication.
Robust Docking Maneuvers for Autonomous Trolley Collection: An Optimization-Based Visual Servoing Scheme
Sep 09, 2025
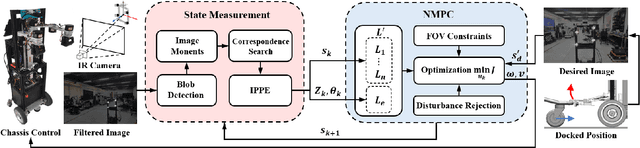
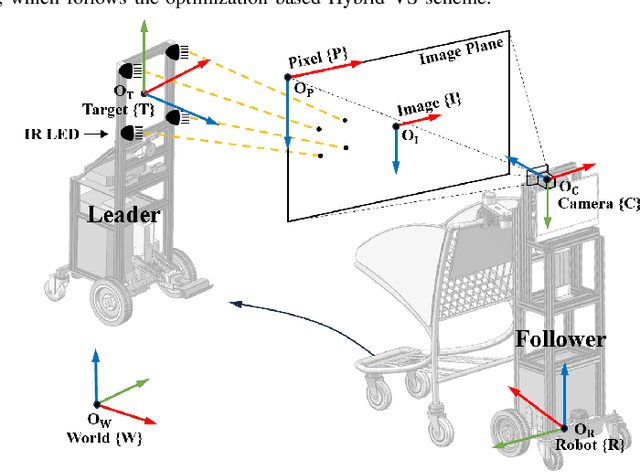

Service robots have demonstrated significant potential for autonomous trolley collection and redistribution in public spaces like airports or warehouses to improve efficiency and reduce cost. Usually, a fully autonomous system for the collection and transportation of multiple trolleys is based on a Leader-Follower formation of mobile manipulators, where reliable docking maneuvers of the mobile base are essential to align trolleys into organized queues. However, developing a vision-based robotic docking system faces significant challenges: high precision requirements, environmental disturbances, and inherent robot constraints. To address these challenges, we propose an optimization-based Visual Servoing scheme that incorporates active infrared markers for robust feature extraction across diverse lighting conditions. This framework explicitly models nonholonomic kinematics and visibility constraints within the Hybrid Visual Servoing problem, augmented with an observer for disturbance rejection to ensure precise and stable docking. Experimental results across diverse environments demonstrate the robustness of this system, with quantitative evaluations confirming high docking accuracy.
Token Communication in the Era of Large Models: An Information Bottleneck-Based Approach
Jul 02, 2025This letter proposes UniToCom, a unified token communication paradigm that treats tokens as the fundamental units for both processing and wireless transmission. Specifically, to enable efficient token representations, we propose a generative information bottleneck (GenIB) principle, which facilitates the learning of tokens that preserve essential information while supporting reliable generation across multiple modalities. By doing this, GenIB-based tokenization is conducive to improving the communication efficiency and reducing computational complexity. Additionally, we develop $\sigma$-GenIB to address the challenges of variance collapse in autoregressive modeling, maintaining representational diversity and stability. Moreover, we employ a causal Transformer-based multimodal large language model (MLLM) at the receiver to unify the processing of both discrete and continuous tokens under the next-token prediction paradigm. Simulation results validate the effectiveness and superiority of the proposed UniToCom compared to baselines under dynamic channel conditions. By integrating token processing with MLLMs, UniToCom enables scalable and generalizable communication in favor of multimodal understanding and generation, providing a potential solution for next-generation intelligent communications.
Task-Agnostic Semantic Communications Relying on Information Bottleneck and Federated Meta-Learning
Apr 30, 2025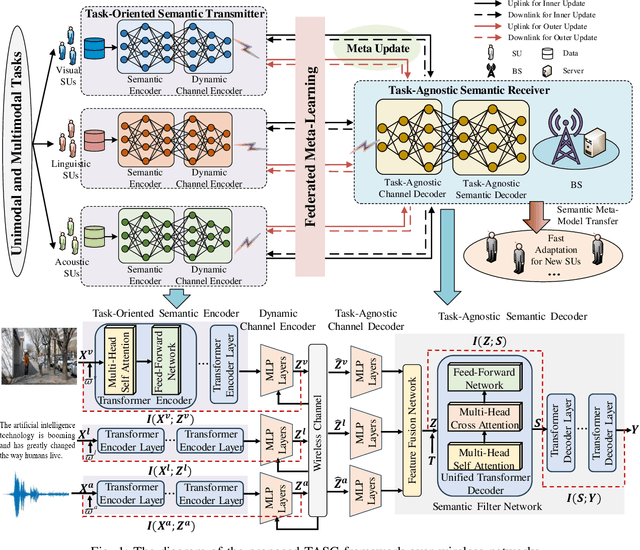
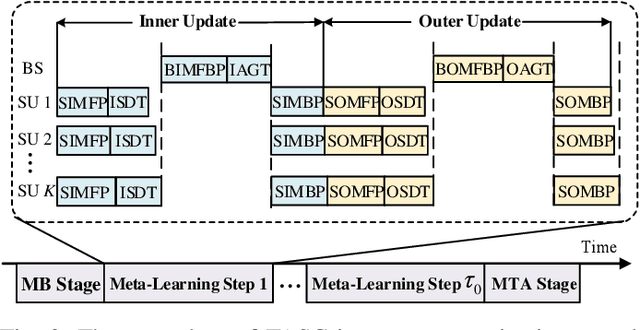
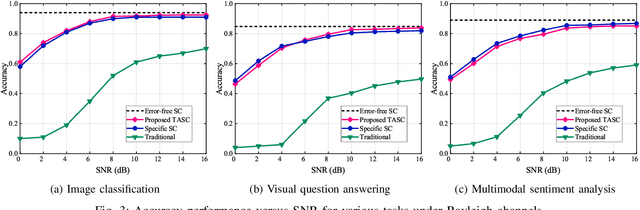
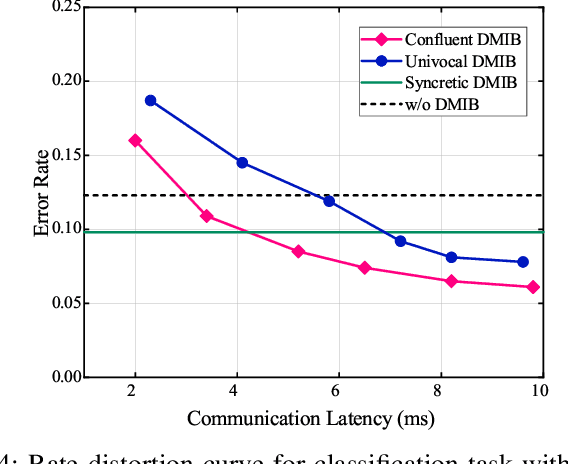
As a paradigm shift towards pervasive intelligence, semantic communication (SemCom) has shown great potentials to improve communication efficiency and provide user-centric services by delivering task-oriented semantic meanings. However, the exponential growth in connected devices, data volumes, and communication demands presents significant challenges for practical SemCom design, particularly in resource-constrained wireless networks. In this work, we first propose a task-agnostic SemCom (TASC) framework that can handle diverse tasks with multiple modalities. Aiming to explore the interplay between communications and intelligent tasks from the information-theoretical perspective, we leverage information bottleneck (IB) theory and propose a distributed multimodal IB (DMIB) principle to learn minimal and sufficient unimodal and multimodal information effectively by discarding redundancy while preserving task-related information. To further reduce the communication overhead, we develop an adaptive semantic feature transmission method under dynamic channel conditions. Then, TASC is trained based on federated meta-learning (FML) for rapid adaptation and generalization in wireless networks. To gain deep insights, we rigorously conduct theoretical analysis and devise resource management to accelerate convergence while minimizing the training latency and energy consumption. Moreover, we develop a joint user selection and resource allocation algorithm to address the non-convex problem with theoretical guarantees. Extensive simulation results validate the effectiveness and superiority of the proposed TASC compared to baselines.
A Physics-guided Multimodal Transformer Path to Weather and Climate Sciences
Apr 19, 2025With the rapid development of machine learning in recent years, many problems in meteorology can now be addressed using AI models. In particular, data-driven algorithms have significantly improved accuracy compared to traditional methods. Meteorological data is often transformed into 2D images or 3D videos, which are then fed into AI models for learning. Additionally, these models often incorporate physical signals, such as temperature, pressure, and wind speed, to further enhance accuracy and interpretability. In this paper, we review several representative AI + Weather/Climate algorithms and propose a new paradigm where observational data from different perspectives, each with distinct physical meanings, are treated as multimodal data and integrated via transformers. Furthermore, key weather and climate knowledge can be incorporated through regularization techniques to further strengthen the model's capabilities. This new paradigm is versatile and can address a variety of tasks, offering strong generalizability. We also discuss future directions for improving model accuracy and interpretability.
Task-Agnostic Semantic Communication with Multimodal Foundation Models
Feb 25, 2025Most existing semantic communication (SemCom) systems use deep joint source-channel coding (DeepJSCC) to encode task-specific semantics in a goal-oriented manner. However, their reliance on predefined tasks and datasets significantly limits their flexibility and generalizability in practical deployments. Multi-modal foundation models provide a promising solution by generating universal semantic tokens. Inspired by this, we introduce SemCLIP, a task-agnostic SemCom framework leveraging the contrastive language-image pre-training (CLIP) model. By transmitting CLIP-generated image tokens instead of raw images, SemCLIP enables efficient semantic communications under low bandwidth and challenging channel conditions, facilitating diverse downstream tasks and zero-shot applications. Specifically, we propose a DeepJSCC scheme for efficient CLIP tokens encoding. To mitigate potential degradation caused by compression and channel noise, a multi-modal transmission-aware prompt learning mechanism is designed at the receiver, which adapts prompts based on transmission quality, enhancing system robustness and channel adaptability. Simulation results demonstrate that SemCLIP outperforms the baselines, achieving a $41\%$ improvement in zero-shot accuracy at a low signal-to-noise ratio. Meanwhile, SemCLIP reduces bandwidth usage by more than $50$-fold compared to different image transmission methods, demonstrating the potential of foundation models towards a generalized, task-agnostic SemCom solution.
FLAF: Focal Line and Feature-constrained Active View Planning for Visual Teach and Repeat
Sep 05, 2024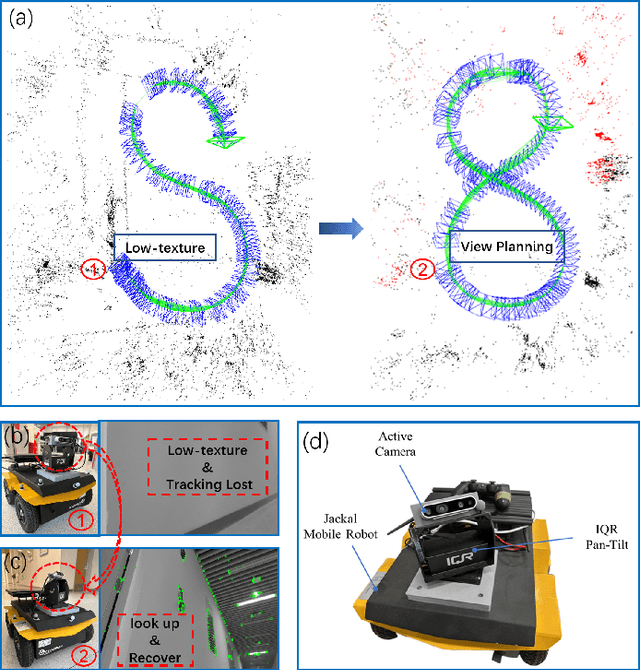
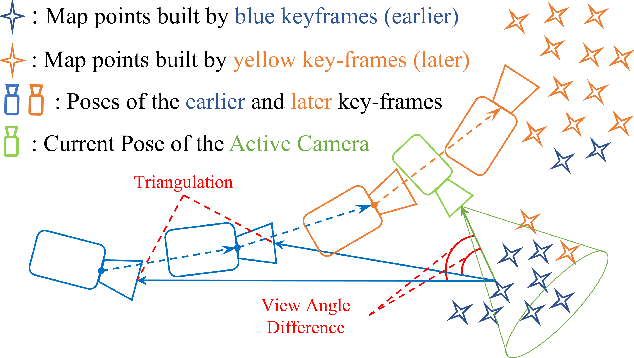
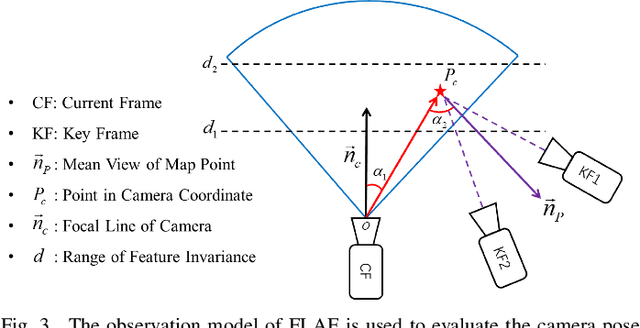
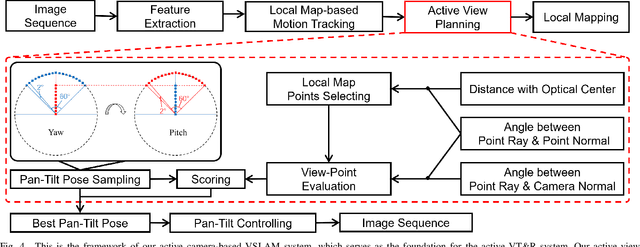
This paper presents FLAF, a focal line and feature-constrained active view planning method for tracking failure avoidance in feature-based visual navigation of mobile robots. Our FLAF-based visual navigation is built upon a feature-based visual teach and repeat (VT\&R) framework, which supports many robotic applications by teaching a robot to navigate on various paths that cover a significant portion of daily autonomous navigation requirements. However, tracking failure in feature-based visual simultaneous localization and mapping (VSLAM) caused by textureless regions in human-made environments is still limiting VT\&R to be adopted in the real world. To address this problem, the proposed view planner is integrated into a feature-based visual SLAM system to build up an active VT\&R system that avoids tracking failure. In our system, a pan-tilt unit (PTU)-based active camera is mounted on the mobile robot. Using FLAF, the active camera-based VSLAM operates during the teaching phase to construct a complete path map and in the repeat phase to maintain stable localization. FLAF orients the robot toward more map points to avoid mapping failures during path learning and toward more feature-identifiable map points beneficial for localization while following the learned trajectory. Experiments in real scenarios demonstrate that FLAF outperforms the methods that do not consider feature-identifiability, and our active VT\&R system performs well in complex environments by effectively dealing with low-texture regions.
Rate-Distortion-Perception Controllable Joint Source-Channel Coding for High-Fidelity Generative Communications
Aug 26, 2024

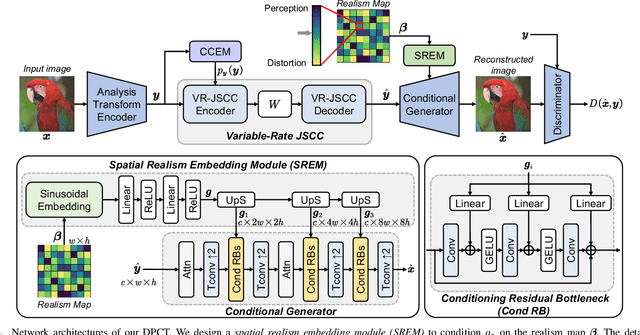

End-to-end image transmission has recently become a crucial trend in intelligent wireless communications, driven by the increasing demand for high bandwidth efficiency. However, existing methods primarily optimize the trade-off between bandwidth cost and objective distortion, often failing to deliver visually pleasing results aligned with human perception. In this paper, we propose a novel rate-distortion-perception (RDP) jointly optimized joint source-channel coding (JSCC) framework to enhance perception quality in human communications. Our RDP-JSCC framework integrates a flexible plug-in conditional Generative Adversarial Networks (GANs) to provide detailed and realistic image reconstructions at the receiver, overcoming the limitations of traditional rate-distortion optimized solutions that typically produce blurry or poorly textured images. Based on this framework, we introduce a distortion-perception controllable transmission (DPCT) model, which addresses the variation in the perception-distortion trade-off. DPCT uses a lightweight spatial realism embedding module (SREM) to condition the generator on a realism map, enabling the customization of appearance realism for each image region at the receiver from a single transmission. Furthermore, for scenarios with scarce bandwidth, we propose an interest-oriented content-controllable transmission (CCT) model. CCT prioritizes the transmission of regions that attract user attention and generates other regions from an instance label map, ensuring both content consistency and appearance realism for all regions while proportionally reducing channel bandwidth costs. Comprehensive experiments demonstrate the superiority of our RDP-optimized image transmission framework over state-of-the-art engineered image transmission systems and advanced perceptual methods.
All Robots in One: A New Standard and Unified Dataset for Versatile, General-Purpose Embodied Agents
Aug 20, 2024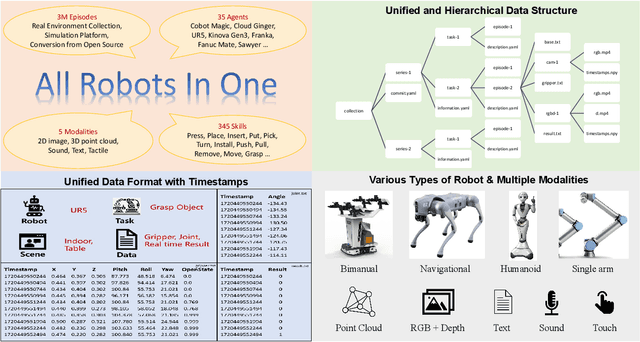

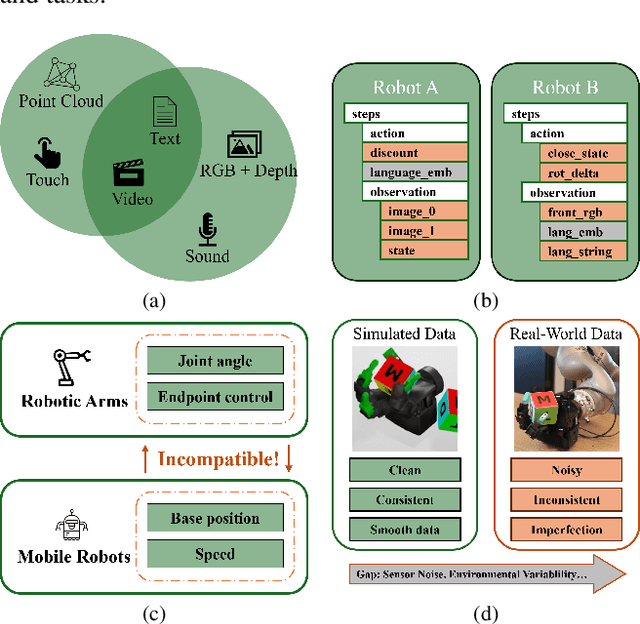
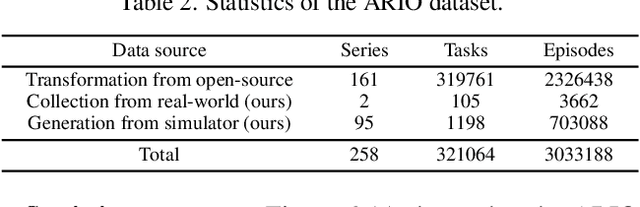
Embodied AI is transforming how AI systems interact with the physical world, yet existing datasets are inadequate for developing versatile, general-purpose agents. These limitations include a lack of standardized formats, insufficient data diversity, and inadequate data volume. To address these issues, we introduce ARIO (All Robots In One), a new data standard that enhances existing datasets by offering a unified data format, comprehensive sensory modalities, and a combination of real-world and simulated data. ARIO aims to improve the training of embodied AI agents, increasing their robustness and adaptability across various tasks and environments. Building upon the proposed new standard, we present a large-scale unified ARIO dataset, comprising approximately 3 million episodes collected from 258 series and 321,064 tasks. The ARIO standard and dataset represent a significant step towards bridging the gaps of existing data resources. By providing a cohesive framework for data collection and representation, ARIO paves the way for the development of more powerful and versatile embodied AI agents, capable of navigating and interacting with the physical world in increasingly complex and diverse ways. The project is available on https://imaei.github.io/project_pages/ario/
Diagnosis of Multiple Fundus Disorders Amidst a Scarcity of Medical Experts Via Self-supervised Machine Learning
Apr 23, 2024



Fundus diseases are major causes of visual impairment and blindness worldwide, especially in underdeveloped regions, where the shortage of ophthalmologists hinders timely diagnosis. AI-assisted fundus image analysis has several advantages, such as high accuracy, reduced workload, and improved accessibility, but it requires a large amount of expert-annotated data to build reliable models. To address this dilemma, we propose a general self-supervised machine learning framework that can handle diverse fundus diseases from unlabeled fundus images. Our method's AUC surpasses existing supervised approaches by 15.7%, and even exceeds performance of a single human expert. Furthermore, our model adapts well to various datasets from different regions, races, and heterogeneous image sources or qualities from multiple cameras or devices. Our method offers a label-free general framework to diagnose fundus diseases, which could potentially benefit telehealth programs for early screening of people at risk of vision loss.