 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-JSCC: Rethinking Deep JSCC with Diffusion Transformers and Semantic Representations
Jan 06, 2026Generative joint source-channel coding (GJSCC) has emerged as a new Deep JSCC paradigm for achieving high-fidelity and robust image transmission under extreme wireless channel conditions, such as ultra-low bandwidth and low signal-to-noise ratio. Recent studies commonly adopt diffusion models as generative decoders, but they frequently produce visually realistic results with limited semantic consistency. This limitation stems from a fundamental mismatch between reconstruction-oriented JSCC encoders and generative decoders, as the former lack explicit semantic discriminability and fail to provide reliable conditional cues. In this paper, we propose DiT-JSCC, a novel GJSCC backbone that can jointly learn a semantics-prioritized representation encoder and a diffusion transformer (DiT) based generative decoder, our open-source project aims to promote the future research in GJSCC. Specifically, we design a semantics-detail dual-branch encoder that aligns naturally with a coarse-to-fine conditional DiT decoder, prioritizing semantic consistency under extreme channel conditions. Moreover, a training-free adaptive bandwidth allocation strategy inspired by Kolmogorov complexity is introduced to further improve the transmission efficiency, thereby indeed redefining the notion of information value in the era of generative decoding. Extensive experiments demonstrate that DiT-JSCC consistently outperforms existing JSCC methods in both semantic consistency and visual quality, particularly in extreme regimes.
Rate-Distortion-Perception Controllable Joint Source-Channel Coding for High-Fidelity Generative Communications
Aug 26, 2024End-to-end image transmission has recently become a crucial trend in intelligent wireless communications, driven by the increasing demand for high bandwidth efficiency. However, existing methods primarily optimize the trade-off between bandwidth cost and objective distortion, often failing to deliver visually pleasing results aligned with human perception. In this paper, we propose a novel rate-distortion-perception (RDP) jointly optimized joint source-channel coding (JSCC) framework to enhance perception quality in human communications. Our RDP-JSCC framework integrates a flexible plug-in conditional Generative Adversarial Networks (GANs) to provide detailed and realistic image reconstructions at the receiver, overcoming the limitations of traditional rate-distortion optimized solutions that typically produce blurry or poorly textured images. Based on this framework, we introduce a distortion-perception controllable transmission (DPCT) model, which addresses the variation in the perception-distortion trade-off. DPCT uses a lightweight spatial realism embedding module (SREM) to condition the generator on a realism map, enabling the customization of appearance realism for each image region at the receiver from a single transmission. Furthermore, for scenarios with scarce bandwidth, we propose an interest-oriented content-controllable transmission (CCT) model. CCT prioritizes the transmission of regions that attract user attention and generates other regions from an instance label map, ensuring both content consistency and appearance realism for all regions while proportionally reducing channel bandwidth costs. Comprehensive experiments demonstrate the superiority of our RDP-optimized image transmission framework over state-of-the-art engineered image transmission systems and advanced perceptual methods.
DiffCom: Channel Received Signal is a Natural Condition to Guide Diffusion Posterior Sampling
Jun 11, 2024



End-to-end visual communication systems typically optimize a trade-off between channel bandwidth costs and signal-level distortion metrics. However, under challenging physical conditions, this traditional discriminative communication paradigm often results in unrealistic reconstructions with perceptible blurring and aliasing artifacts, despite the inclusion of perceptual or adversarial losses for optimizing. This issue primarily stems from the receiver's limited knowledge about the underlying data manifold and the use of deterministic decoding mechanisms. To address these limitations, this paper introduces DiffCom, a novel end-to-end generative communication paradigm that utilizes off-the-shelf generative priors and probabilistic diffusion models for decoding, thereby improving perceptual quality without heavily relying on bandwidth costs and received signal quality. Unlike traditional systems that rely on deterministic decoders optimized solely for distortion metrics, our DiffCom leverages raw channel-received signal as a fine-grained condition to guide stochastic posterior sampling. Our approach ensures that reconstructions remain on the manifold of real data with a novel confirming constraint, enhancing the robustness and reliability of the generated outcomes. Furthermore, DiffCom incorporates a blind posterior sampling technique to address scenarios with unknown forward transmission characteristics. Extensive experimental validations demonstrate that DiffCom not only produces realistic reconstructions with details faithful to the original data but also achieves superior robustness against diverse wireless transmission degradations. Collectively, these advancements establish DiffCom as a new benchmark in designing generative communication systems that offer enhanced robustness and generalization superiorities.
Adaptive Semantic Communications: Overfitting the Source and Channel for Profit
Nov 08, 2022Most semantic communication systems leverage deep learning models to provide end-to-end transmission performance surpassing the established source and channel coding approaches. While, so far, research has mainly focused on architecture and model improvements, but such a model trained over a full dataset and ergodic channel responses is unlikely to be optimal for every test instance. Due to limitations on the model capacity and imperfect optimization and generalization, such learned models will be suboptimal especially when the testing data distribution or channel response is different from that in the training phase, as is likely to be the case in practice. To tackle this, in this paper, we propose a novel semantic communication paradigm by leveraging the deep learning model's overfitting property. Our model can for instance be updated after deployment, which can further lead to substantial gains in terms of the transmission rate-distortion (RD) performance. This new system is named adaptive semantic communication (ASC). In our ASC system, the ingredients of wireless transmitted stream include both the semantic representations of source data and the adapted decoder model parameters. Specifically, we take the overfitting concept to the extreme, proposing a series of ingenious methods to adapt the semantic codec or representations to an individual data or channel state instance. The whole ASC system design is formulated as an optimization problem whose goal is to minimize the loss function that is a tripartite tradeoff among the data rate, model rate, and distortion terms. The experiments (including user study) verify the effectiveness and efficiency of our ASC system. Notably, the substantial gain of our overfitted coding paradigm can catalyze semantic communication upgrading to a new era.
WITT: A Wireless Image Transmission Transformer for Semantic Communications
Nov 02, 2022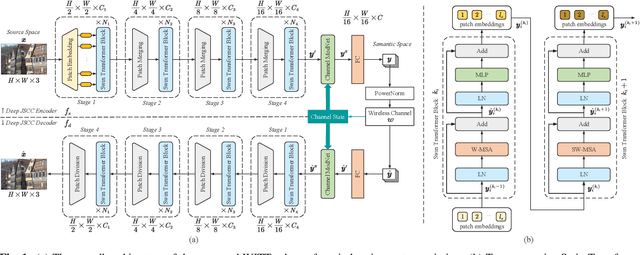

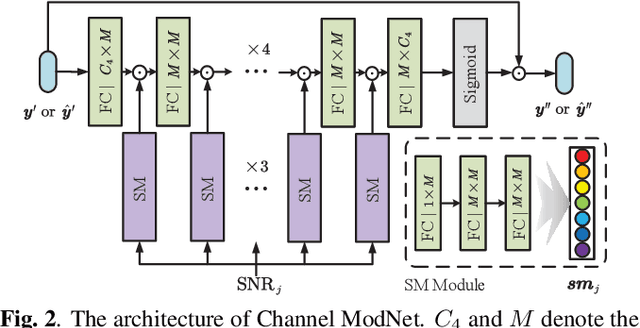
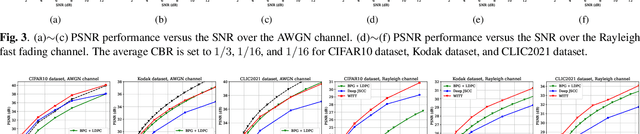
In this paper, we aim to redesign the vision Transformer (ViT) as a new backbone to realize semantic image transmission, termed wireless image transmission transformer (WITT). Previous works build upon convolutional neural networks (CNNs), which are inefficient in capturing global dependencies, resulting in degraded end-to-end transmission performance especially for high-resolution images. To tackle this, the proposed WITT employs Swin Transformers as a more capable backbone to extract long-range information. Different from ViTs in image classification tasks, WITT is highly optimized for image transmission while considering the effect of the wireless channel. Specifically, we propose a spatial modulation module to scale the latent representations according to channel state information, which enhances the ability of a single model to deal with various channel conditions. As a result, extensive experiments verify that our WITT attains better performance for different image resolutions, distortion metrics, and channel conditions. The code is available at https://github.com/KeYang8/WITT.
Nonlinear Transform Source-Channel Coding for Semantic Communications
Dec 21, 2021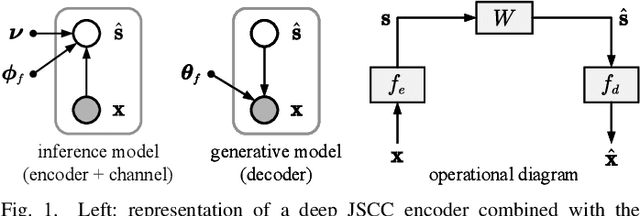
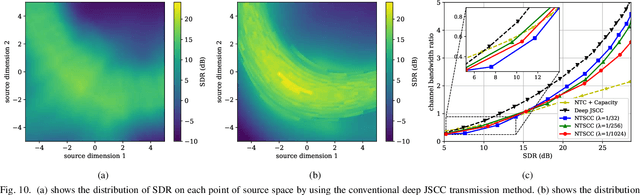
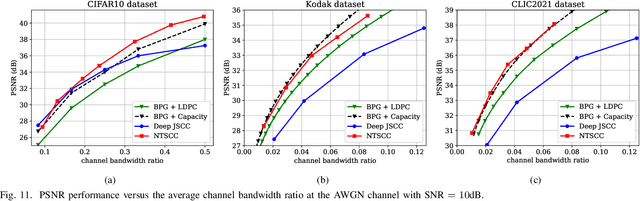
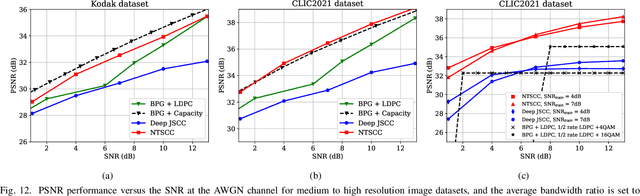
In this paper, we propose a new class of high-efficient deep joint source-channel coding methods that can closely adapt to the source distribution under the nonlinear transform, it can be collected under the name nonlinear transform source-channel coding (NTSCC). In the considered model, the transmitter first learns a nonlinear analysis transform to map the source data into latent space, then transmits the latent representation to the receiver via deep joint source-channel coding. Our model incorporates the nonlinear transform as a strong prior to effectively extract the source semantic features and provide side information for source-channel coding. Unlike existing conventional deep joint source-channel coding methods, the proposed NTSCC essentially learns both the source latent representation and an entropy model as the prior on the latent representation. Accordingly, novel adaptive rate transmission and hyperprior-aided codec refinement mechanisms are developed to upgrade deep joint source-channel coding. The whole system design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under established perceptual quality metrics. Across simple example sources and test image sources, we find that the proposed NTSCC transmission method generally outperforms both the analog transmission using the standard deep joint source-channel coding and the classical separation-based digital transmission. Notably, the proposed NTSCC method can potentially support future semantic communications due to its vigorous content-aware ability.