 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-JSCC: Rethinking Deep JSCC with Diffusion Transformers and Semantic Representations
Jan 06, 2026Generative joint source-channel coding (GJSCC) has emerged as a new Deep JSCC paradigm for achieving high-fidelity and robust image transmission under extreme wireless channel conditions, such as ultra-low bandwidth and low signal-to-noise ratio. Recent studies commonly adopt diffusion models as generative decoders, but they frequently produce visually realistic results with limited semantic consistency. This limitation stems from a fundamental mismatch between reconstruction-oriented JSCC encoders and generative decoders, as the former lack explicit semantic discriminability and fail to provide reliable conditional cues. In this paper, we propose DiT-JSCC, a novel GJSCC backbone that can jointly learn a semantics-prioritized representation encoder and a diffusion transformer (DiT) based generative decoder, our open-source project aims to promote the future research in GJSCC. Specifically, we design a semantics-detail dual-branch encoder that aligns naturally with a coarse-to-fine conditional DiT decoder, prioritizing semantic consistency under extreme channel conditions. Moreover, a training-free adaptive bandwidth allocation strategy inspired by Kolmogorov complexity is introduced to further improve the transmission efficiency, thereby indeed redefining the notion of information value in the era of generative decoding. Extensive experiments demonstrate that DiT-JSCC consistently outperforms existing JSCC methods in both semantic consistency and visual quality, particularly in extreme regimes.
Distributed Image Semantic Communication via Nonlinear Transform Coding
Jun 09, 2025This paper investigates distributed source-channel coding for correlated image semantic transmission over wireless channels. In this setup, correlated images at different transmitters are separately encoded and transmitted through dedicated channels for joint recovery at the receiver. We propose a general approach for distributed image semantic communication that applies to both separate source and channel coding (SSCC) and joint source-channel coding (JSCC). Unlike existing learning-based approaches that implicitly learn source correlation in a purely data-driven manner, our method leverages nonlinear transform coding (NTC) to explicitly model source correlation from both probabilistic and geometric perspectives. A joint entropy model approximates the joint distribution of latent representations to guide adaptive rate allocation, while a transformation module aligns latent features for maximal correlation learning at the decoder. We implement this framework as D-NTSC for SSCC and D-NTSCC for JSCC, both built on Swin Transformers for effective feature extraction and correlation exploitation. Variational inference is employed to derive principled loss functions that jointly optimize encoding, decoding, and joint entropy modeling. Extensive experiments on real-world multi-view datasets demonstrate that D-NTSC and D-NTSCC outperform existing distributed SSCC and distributed JSCC baselines, respectively, achieving state-of-the-art performance in both pixel-level and perceptual quality metrics.
Synonymous Variational Inference for Perceptual Image Compression
May 28, 2025Recent contributions of semantic information theory reveal the set-element relationship between semantic and syntactic information, represented as synonymous relationships. In this paper, we propose a synonymous variational inference (SVI) method based on this synonymity viewpoint to re-analyze the perceptual image compression problem. It takes perceptual similarity as a typical synonymous criterion to build an ideal synonymous set (Synset), and approximate the posterior of its latent synonymous representation with a parametric density by minimizing a partial semantic KL divergence. This analysis theoretically proves that the optimization direction of perception image compression follows a triple tradeoff that can cover the existing rate-distortion-perception schemes. Additionally, we introduce synonymous image compression (SIC), a new image compression scheme that corresponds to the analytical process of SVI, and implement a progressive SIC codec to fully leverage the model's capabilities. Experimental results demonstrate comparable rate-distortion-perception performance using a single progressive SIC codec, thus verifying the effectiveness of our proposed analysis method.
SymbioticRAG: Enhancing Document Intelligence Through Human-LLM Symbiotic Collaboration
May 05, 2025We present \textbf{SymbioticRAG}, a novel framework that fundamentally reimagines Retrieval-Augmented Generation~(RAG) systems by establishing a bidirectional learning relationship between humans and machines. Our approach addresses two critical challenges in current RAG systems: the inherently human-centered nature of relevance determination and users' progression from "unconscious incompetence" in query formulation. SymbioticRAG introduces a two-tier solution where Level 1 enables direct human curation of retrieved content through interactive source document exploration, while Level 2 aims to build personalized retrieval models based on captured user interactions. We implement Level 1 through three key components: (1)~a comprehensive document processing pipeline with specialized models for layout detection, OCR, and extraction of tables, formulas, and figures; (2)~an extensible retriever module supporting multiple retrieval strategies; and (3)~an interactive interface that facilitates both user engagement and interaction data logging. We experiment Level 2 implementation via a retriever strategy incorporated LLM summarized user intention from user interaction logs. To maintain high-quality data preparation, we develop a human-on-the-loop validation interface that improves pipeline output while advancing research in specialized extraction tasks. Evaluation across three scenarios (literature review, geological exploration, and education) demonstrates significant improvements in retrieval relevance and user satisfaction compared to traditional RAG approaches. To facilitate broader research and further advancement of SymbioticRAG Level 2 implementation, we will make our system openly accessible to the research community.
Towards Automatic Continual Learning: A Self-Adaptive Framework for Continual Instruction Tuning
Mar 20, 2025


Continual instruction tuning enables large language models (LLMs) to learn incrementally while retaining past knowledge, whereas existing methods primarily focus on how to retain old knowledge rather than on selecting which new knowledge to learn. In domain-specific contexts, maintaining data quality and managing system constraints remain key challenges. To address these issues, we propose an automated continual instruction tuning framework that dynamically filters incoming data, which identify and reduce redundant data across successive updates. Our approach utilizes a small proxy model for efficient perplexity-based filtering, and updates the proxy to ensure that the filtering criteria remain aligned with the evolving state of the deployed model. Compared to existing static data selection methods, our framework can effectively handle incrementally acquired data and shifting distributions. Additionally, it addresses practical deployment challenges by enabling seamless model updates, supporting version rollback and incorporating automatic checkpoint evaluation. We evaluated the system in real-world medical scenarios. It reduced computational costs by 66.7% and improved model performance, and achieved autonomous updates, thus demonstrating its effectiveness for automatic continual instruction tuning.
NeRFCom: Feature Transform Coding Meets Neural Radiance Field for Free-View 3D Scene Semantic Transmission
Feb 27, 2025We introduce NeRFCom, a novel communication system designed for end-to-end 3D scene transmission. Compared to traditional systems relying on handcrafted NeRF semantic feature decomposition for compression and well-adaptive channel coding for transmission error correction, our NeRFCom employs a nonlinear transform and learned probabilistic models, enabling flexible variable-rate joint source-channel coding and efficient bandwidth allocation aligned with the NeRF semantic feature's different contribution to the 3D scene synthesis fidelity. Experimental results demonstrate that NeRFCom achieves free-view 3D scene efficient transmission while maintaining robustness under adverse channel conditions.
Multi-Block UAMP Detection for AFDM under Fractional Delay-Doppler Channel
Oct 15, 2024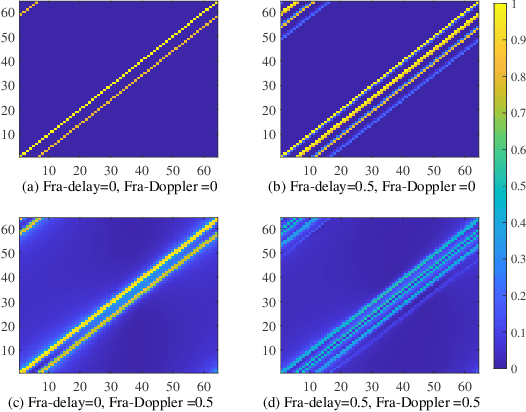
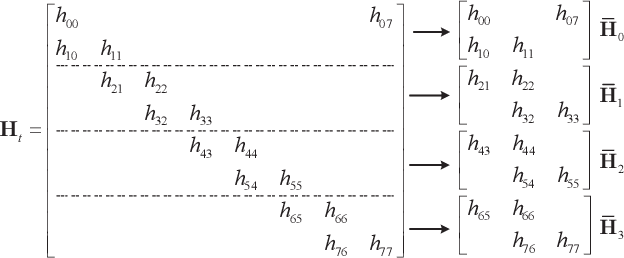
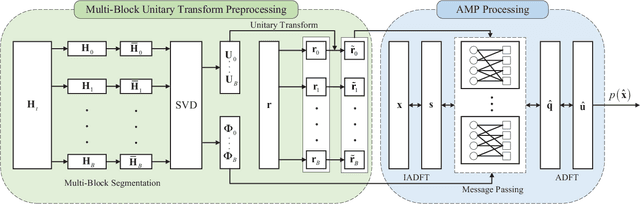
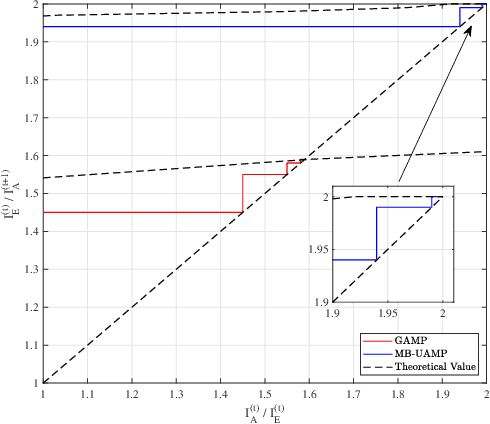
Affine Frequency Division Multiplexing (AFDM) is considered as a promising solution for next-generation wireless systems due to its satisfactory performance in high-mobility scenarios. By adjusting AFDM parameters to match the multi-path delay and Doppler shift, AFDM can achieve two-dimensional time-frequency diversity gain. However, under fractional delay-Doppler channels, AFDM encounters energy dispersion in the affine domain, which poses significant challenges for signal detection. This paper first investigates the AFDM system model under fractional delay-Doppler channels. To address the energy dispersion in the affine domain, a unitary transformation based approximate message passing (UAMP) algorithm is proposed. The algorithm performs unitary transformations and message passing in the time domain to avoid the energy dispersion issue. Additionally, we implemented block-wise processing to reduce computational complexity. Finally, the empirical extrinsic information transfer (E-EXIT) chart is used to evaluate iterative detection performance. Simulation results show that UAMP significantly outperforms GAMP under fractional delay-Doppler conditions.
Rate-Distortion-Perception Controllable Joint Source-Channel Coding for High-Fidelity Generative Communications
Aug 26, 2024End-to-end image transmission has recently become a crucial trend in intelligent wireless communications, driven by the increasing demand for high bandwidth efficiency. However, existing methods primarily optimize the trade-off between bandwidth cost and objective distortion, often failing to deliver visually pleasing results aligned with human perception. In this paper, we propose a novel rate-distortion-perception (RDP) jointly optimized joint source-channel coding (JSCC) framework to enhance perception quality in human communications. Our RDP-JSCC framework integrates a flexible plug-in conditional Generative Adversarial Networks (GANs) to provide detailed and realistic image reconstructions at the receiver, overcoming the limitations of traditional rate-distortion optimized solutions that typically produce blurry or poorly textured images. Based on this framework, we introduce a distortion-perception controllable transmission (DPCT) model, which addresses the variation in the perception-distortion trade-off. DPCT uses a lightweight spatial realism embedding module (SREM) to condition the generator on a realism map, enabling the customization of appearance realism for each image region at the receiver from a single transmission. Furthermore, for scenarios with scarce bandwidth, we propose an interest-oriented content-controllable transmission (CCT) model. CCT prioritizes the transmission of regions that attract user attention and generates other regions from an instance label map, ensuring both content consistency and appearance realism for all regions while proportionally reducing channel bandwidth costs. Comprehensive experiments demonstrate the superiority of our RDP-optimized image transmission framework over state-of-the-art engineered image transmission systems and advanced perceptual methods.
DiffCom: Channel Received Signal is a Natural Condition to Guide Diffusion Posterior Sampling
Jun 11, 2024



End-to-end visual communication systems typically optimize a trade-off between channel bandwidth costs and signal-level distortion metrics. However, under challenging physical conditions, this traditional discriminative communication paradigm often results in unrealistic reconstructions with perceptible blurring and aliasing artifacts, despite the inclusion of perceptual or adversarial losses for optimizing. This issue primarily stems from the receiver's limited knowledge about the underlying data manifold and the use of deterministic decoding mechanisms. To address these limitations, this paper introduces DiffCom, a novel end-to-end generative communication paradigm that utilizes off-the-shelf generative priors and probabilistic diffusion models for decoding, thereby improving perceptual quality without heavily relying on bandwidth costs and received signal quality. Unlike traditional systems that rely on deterministic decoders optimized solely for distortion metrics, our DiffCom leverages raw channel-received signal as a fine-grained condition to guide stochastic posterior sampling. Our approach ensures that reconstructions remain on the manifold of real data with a novel confirming constraint, enhancing the robustness and reliability of the generated outcomes. Furthermore, DiffCom incorporates a blind posterior sampling technique to address scenarios with unknown forward transmission characteristics. Extensive experimental validations demonstrate that DiffCom not only produces realistic reconstructions with details faithful to the original data but also achieves superior robustness against diverse wireless transmission degradations. Collectively, these advancements establish DiffCom as a new benchmark in designing generative communication systems that offer enhanced robustness and generalization superiorities.
Deep Generative Modeling Reshapes Compression and Transmission: From Efficiency to Resiliency
Jun 10, 2024



Information theory and machine learning are inextricably linked and have even been referred to as "two sides of the same coin". One particularly elegant connection is the essential equivalence between probabilistic generative modeling and data compression or transmission. In this article, we reveal the dual-functionality of deep generative models that reshapes both data compression for efficiency and transmission error concealment for resiliency. We present how the contextual predictive capabilities of powerful generative models can be well positioned to be strong compressors and estimators. In this sense, we advocate for viewing the deep generative modeling problem through the lens of end-to-end communications, and evaluate the compression and error restoration capabilities of foundation generative models. We show that the kernel of many large generative models is powerful predictor that can capture complex relationships among semantic latent variables, and the communication viewpoints provide novel insights into semantic feature tokenization, contextual learning, and usage of deep generative models. In summary, our article highlights the essential connections of generative AI to source and channel coding techniques, and motivates researchers to make further explorations in this emerging topic.