 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Spatiotemporal Token Compression for Video-LLMs at Ultra-Low Retention
Mar 23, 2026Video large language models (Video-LLMs) face high computational costs due to large volumes of visual tokens. Existing token compression methods typically adopt a two-stage spatiotemporal compression strategy, relying on stage-specific metrics and an implicit assumption of spatiotemporal separability. Under extremely low retention ratios, however, such approaches often result in unbalanced allocation and loss of visual evidence essential for question answering. We reformulate token compression as a spatiotemporal allocation task within a global token retention pool. We propose a unified selection mechanism that integrates attention weights and semantic similarity to globally select tokens with high contribution and low redundancy. Unselected tokens are merged via clustering and refilled, preserving information integrity. Inside the LLM, we further introduce text-aware merging to perform secondary compression based on query relevance. Without requiring retraining, our method serves as a plug-and-play module compatible with existing Video-LLMs. Experiments show that retaining only about 2% of visual tokens preserves 90.1% of baseline performance across multiple benchmarks, while reducing FLOPs to roughly 2.6%. These benefits generalize across diverse backbones, decreasing end-to-end inference latency and memory consumption. Our unified spatiotemporal token compression strategy establishes the state-of-the-art in video understanding under ultra-low token retention.
Next-Frame Decoding for Ultra-Low-Bitrate Image Compression with Video Diffusion Priors
Mar 16, 2026We present a novel paradigm for ultra-low-bitrate image compression (ULB-IC) that exploits the ``temporal'' evolution in generative image compression. Specifically, we define an explicit intermediate state during decoding: a compact anchor frame, which preserves the scene geometry and semantic layout while discarding high-frequency details. We then reinterpret generative decoding as a virtual temporal transition from this anchor to the final reconstructed image.To model this progression, we leverage a pretrained video diffusion model (VDM) as temporal priors: the anchor frame serves as the initial frame and the original image as the target frame, transforming the decoding process into a next-frame prediction task.In contrast to image diffusion-based ULB-IC models, our decoding proceeds from a visible, semantically faithful anchor, which improves both fidelity and realism for perceptual image compression. Extensive experiments demonstrate that our method achieves superior objective and subjective performance. On the CLIC2020 test set, our method achieves over \textbf{50\% bitrate savings} across LPIPS, DISTS, FID, and KID compared to DiffC, while also delivering a significant decoding speedup of up to $\times$5. Code will be released later.
Dual-Representation Image Compression at Ultra-Low Bitrates via Explicit Semantics and Implicit Textures
Feb 05, 2026While recent neural codecs achieve strong performance at low bitrates when optimized for perceptual quality, their effectiveness deteriorates significantly under ultra-low bitrate conditions. To mitigate this, generative compression methods leveraging semantic priors from pretrained models have emerged as a promising paradigm. However, existing approaches are fundamentally constrained by a tradeoff between semantic faithfulness and perceptual realism. Methods based on explicit representations preserve content structure but often lack fine-grained textures, whereas implicit methods can synthesize visually plausible details at the cost of semantic drift. In this work, we propose a unified framework that bridges this gap by coherently integrating explicit and implicit representations in a training-free manner. Specifically, We condition a diffusion model on explicit high-level semantics while employing reverse-channel coding to implicitly convey fine-grained details. Moreover, we introduce a plug-in encoder that enables flexible control of the distortion-perception tradeoff by modulating the implicit information. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art rate-perception performance, outperforming existing methods and surpassing DiffC by 29.92%, 19.33%, and 20.89% in DISTS BD-Rate on the Kodak, DIV2K, and CLIC2020 datasets, respectively.
DiT-JSCC: Rethinking Deep JSCC with Diffusion Transformers and Semantic Representations
Jan 06, 2026Generative joint source-channel coding (GJSCC) has emerged as a new Deep JSCC paradigm for achieving high-fidelity and robust image transmission under extreme wireless channel conditions, such as ultra-low bandwidth and low signal-to-noise ratio. Recent studies commonly adopt diffusion models as generative decoders, but they frequently produce visually realistic results with limited semantic consistency. This limitation stems from a fundamental mismatch between reconstruction-oriented JSCC encoders and generative decoders, as the former lack explicit semantic discriminability and fail to provide reliable conditional cues. In this paper, we propose DiT-JSCC, a novel GJSCC backbone that can jointly learn a semantics-prioritized representation encoder and a diffusion transformer (DiT) based generative decoder, our open-source project aims to promote the future research in GJSCC. Specifically, we design a semantics-detail dual-branch encoder that aligns naturally with a coarse-to-fine conditional DiT decoder, prioritizing semantic consistency under extreme channel conditions. Moreover, a training-free adaptive bandwidth allocation strategy inspired by Kolmogorov complexity is introduced to further improve the transmission efficiency, thereby indeed redefining the notion of information value in the era of generative decoding. Extensive experiments demonstrate that DiT-JSCC consistently outperforms existing JSCC methods in both semantic consistency and visual quality, particularly in extreme regimes.
Structure-Guided Allocation of 2D Gaussians for Image Representation and Compression
Dec 30, 2025Recent advances in 2D Gaussian Splatting (2DGS) have demonstrated its potential as a compact image representation with millisecond-level decoding. However, existing 2DGS-based pipelines allocate representation capacity and parameter precision largely oblivious to image structure, limiting their rate-distortion (RD) efficiency at low bitrates. To address this, we propose a structure-guided allocation principle for 2DGS, which explicitly couples image structure with both representation capacity and quantization precision, while preserving native decoding speed. First, we introduce a structure-guided initialization that assigns 2D Gaussians according to spatial structural priors inherent in natural images, yielding a localized and semantically meaningful distribution. Second, during quantization-aware fine-tuning, we propose adaptive bitwidth quantization of covariance parameters, which grants higher precision to small-scale Gaussians in complex regions and lower precision elsewhere, enabling RD-aware optimization, thereby reducing redundancy without degrading edge quality. Third, we impose a geometry-consistent regularization that aligns Gaussian orientations with local gradient directions to better preserve structural details. Extensive experiments demonstrate that our approach substantially improves both the representational power and the RD performance of 2DGS while maintaining over 1000 FPS decoding. Compared with the baseline GSImage, we reduce BD-rate by 43.44% on Kodak and 29.91% on DIV2K.
Generative AI Meets 6G and Beyond: Diffusion Models for Semantic Communications
Nov 11, 2025Semantic communications mark a paradigm shift from bit-accurate transmission toward meaning-centric communication, essential as wireless systems approach theoretical capacity limits. The emergence of generative AI has catalyzed generative semantic communications, where receivers reconstruct content from minimal semantic cues by leveraging learned priors. Among generative approaches, diffusion models stand out for their superior generation quality, stable training dynamics, and rigorous theoretical foundations. However, the field currently lacks systematic guidance connecting diffusion techniques to communication system design, forcing researchers to navigate disparate literatures. This article provides the first comprehensive tutorial on diffusion models for generative semantic communications. We present score-based diffusion foundations and systematically review three technical pillars: conditional diffusion for controllable generation, efficient diffusion for accelerated inference, and generalized diffusion for cross-domain adaptation. In addition, we introduce an inverse problem perspective that reformulates semantic decoding as posterior inference, bridging semantic communications with computational imaging. Through analysis of human-centric, machine-centric, and agent-centric scenarios, we illustrate how diffusion models enable extreme compression while maintaining semantic fidelity and robustness. By bridging generative AI innovations with communication system design, this article aims to establish diffusion models as foundational components of next-generation wireless networks and beyond.
NeRFCom: Feature Transform Coding Meets Neural Radiance Field for Free-View 3D Scene Semantic Transmission
Feb 27, 2025We introduce NeRFCom, a novel communication system designed for end-to-end 3D scene transmission. Compared to traditional systems relying on handcrafted NeRF semantic feature decomposition for compression and well-adaptive channel coding for transmission error correction, our NeRFCom employs a nonlinear transform and learned probabilistic models, enabling flexible variable-rate joint source-channel coding and efficient bandwidth allocation aligned with the NeRF semantic feature's different contribution to the 3D scene synthesis fidelity. Experimental results demonstrate that NeRFCom achieves free-view 3D scene efficient transmission while maintaining robustness under adverse channel conditions.
Rate-Distortion-Perception Controllable Joint Source-Channel Coding for High-Fidelity Generative Communications
Aug 26, 2024

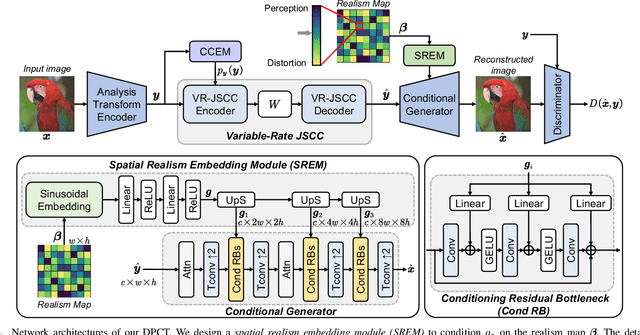

End-to-end image transmission has recently become a crucial trend in intelligent wireless communications, driven by the increasing demand for high bandwidth efficiency. However, existing methods primarily optimize the trade-off between bandwidth cost and objective distortion, often failing to deliver visually pleasing results aligned with human perception. In this paper, we propose a novel rate-distortion-perception (RDP) jointly optimized joint source-channel coding (JSCC) framework to enhance perception quality in human communications. Our RDP-JSCC framework integrates a flexible plug-in conditional Generative Adversarial Networks (GANs) to provide detailed and realistic image reconstructions at the receiver, overcoming the limitations of traditional rate-distortion optimized solutions that typically produce blurry or poorly textured images. Based on this framework, we introduce a distortion-perception controllable transmission (DPCT) model, which addresses the variation in the perception-distortion trade-off. DPCT uses a lightweight spatial realism embedding module (SREM) to condition the generator on a realism map, enabling the customization of appearance realism for each image region at the receiver from a single transmission. Furthermore, for scenarios with scarce bandwidth, we propose an interest-oriented content-controllable transmission (CCT) model. CCT prioritizes the transmission of regions that attract user attention and generates other regions from an instance label map, ensuring both content consistency and appearance realism for all regions while proportionally reducing channel bandwidth costs. Comprehensive experiments demonstrate the superiority of our RDP-optimized image transmission framework over state-of-the-art engineered image transmission systems and advanced perceptual methods.
DiffCom: Channel Received Signal is a Natural Condition to Guide Diffusion Posterior Sampling
Jun 11, 2024



End-to-end visual communication systems typically optimize a trade-off between channel bandwidth costs and signal-level distortion metrics. However, under challenging physical conditions, this traditional discriminative communication paradigm often results in unrealistic reconstructions with perceptible blurring and aliasing artifacts, despite the inclusion of perceptual or adversarial losses for optimizing. This issue primarily stems from the receiver's limited knowledge about the underlying data manifold and the use of deterministic decoding mechanisms. To address these limitations, this paper introduces DiffCom, a novel end-to-end generative communication paradigm that utilizes off-the-shelf generative priors and probabilistic diffusion models for decoding, thereby improving perceptual quality without heavily relying on bandwidth costs and received signal quality. Unlike traditional systems that rely on deterministic decoders optimized solely for distortion metrics, our DiffCom leverages raw channel-received signal as a fine-grained condition to guide stochastic posterior sampling. Our approach ensures that reconstructions remain on the manifold of real data with a novel confirming constraint, enhancing the robustness and reliability of the generated outcomes. Furthermore, DiffCom incorporates a blind posterior sampling technique to address scenarios with unknown forward transmission characteristics. Extensive experimental validations demonstrate that DiffCom not only produces realistic reconstructions with details faithful to the original data but also achieves superior robustness against diverse wireless transmission degradations. Collectively, these advancements establish DiffCom as a new benchmark in designing generative communication systems that offer enhanced robustness and generalization superiorities.
Deep Generative Modeling Reshapes Compression and Transmission: From Efficiency to Resiliency
Jun 10, 2024



Information theory and machine learning are inextricably linked and have even been referred to as "two sides of the same coin". One particularly elegant connection is the essential equivalence between probabilistic generative modeling and data compression or transmission. In this article, we reveal the dual-functionality of deep generative models that reshapes both data compression for efficiency and transmission error concealment for resiliency. We present how the contextual predictive capabilities of powerful generative models can be well positioned to be strong compressors and estimators. In this sense, we advocate for viewing the deep generative modeling problem through the lens of end-to-end communications, and evaluate the compression and error restoration capabilities of foundation generative models. We show that the kernel of many large generative models is powerful predictor that can capture complex relationships among semantic latent variables, and the communication viewpoints provide novel insights into semantic feature tokenization, contextual learning, and usage of deep generative models. In summary, our article highlights the essential connections of generative AI to source and channel coding techniques, and motivates researchers to make further explorations in this emerging topic.