 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
Towards Safe Mobility: A Unified Transportation Foundation Model enabled by Open-Ended Vision-Language Dataset
Apr 24, 2026Urban transportation systems face growing safety challenges that require scalable intelligence for emerging smart mobility infrastructures. While recent advances in foundation models and large-scale multimodal datasets have strengthened perception and reasoning in intelligent transportation systems (ITS), existing research remains largely centered on microscopic autonomous driving (AD), with limited attention to city-scale traffic analysis. In particular, open-ended safety-oriented visual question answering (VQA) and corresponding foundation models for reasoning over heterogeneous roadside camera observations remain underexplored. To address this gap, we introduce the Land Transportation Dataset (LTD), a large-scale open-source vision-language dataset for open-ended reasoning in urban traffic environments. LTD contains 11.6K high-quality VQA pairs collected from heterogeneous roadside cameras, spanning diverse road geometries, traffic participants, illumination conditions, and adverse weather. The dataset integrates three complementary tasks: fine-grained multi-object grounding, multi-image camera selection, and multi-image risk analysis, requiring joint reasoning over minimally correlated views to infer hazardous objects, contributing factors, and risky road directions. To ensure annotation fidelity, we combine multi-model vision-language generation with cross-validation and human-in-the-loop refinement. Building upon LTD, we further propose UniVLT, a transportation foundation model trained via curriculum-based knowledge transfer to unify microscopic AD reasoning and macroscopic traffic analysis within a single architecture. Extensive experiments on LTD and multiple AD benchmarks demonstrate that UniVLT achieves SOTA performance on open-ended reasoning tasks across diverse domains, while exposing limitations of existing foundation models in complex multi-view traffic scenarios.
Tempered Sequential Monte Carlo for Trajectory and Policy Optimization with Differentiable Dynamics
Apr 23, 2026We propose a sampling-based framework for finite-horizon trajectory and policy optimization under differentiable dynamics by casting controller design as inference. Specifically, we minimize a KL-regularized expected trajectory cost, which yields an optimal "Boltzmann-tilted" distribution over controller parameters that concentrates on low-cost solutions as temperature decreases. To sample efficiently from this sharp, potentially multimodal target, we introduce tempered sequential Monte Carlo (TSMC): an annealing scheme that adaptively reweights and resamples particles along a tempering path from a prior to the target distribution, while using Hamiltonian Monte Carlo rejuvenation to maintain diversity and exploit exact gradients obtained by differentiating through trajectory rollouts. For policy optimization, we extend TSMC via (i) a deterministic empirical approximation of the initial-state distribution and (ii) an extended-space construction that treats rollout randomness as auxiliary variables. Experiments across trajectory- and policy-optimization benchmarks show that TSMC is broadly applicable and compares favorably to state-of-the-art baselines.
Advances in Global Solvers for 3D Vision
Feb 16, 2026Global solvers have emerged as a powerful paradigm for 3D vision, offering certifiable solutions to nonconvex geometric optimization problems traditionally addressed by local or heuristic methods. This survey presents the first systematic review of global solvers in geometric vision, unifying the field through a comprehensive taxonomy of three core paradigms: Branch-and-Bound (BnB), Convex Relaxation (CR), and Graduated Non-Convexity (GNC). We present their theoretical foundations, algorithmic designs, and practical enhancements for robustness and scalability, examining how each addresses the fundamental nonconvexity of geometric estimation problems. Our analysis spans ten core vision tasks, from Wahba problem to bundle adjustment, revealing the optimality-robustness-scalability trade-offs that govern solver selection. We identify critical future directions: scaling algorithms while maintaining guarantees, integrating data-driven priors with certifiable optimization, establishing standardized benchmarks, and addressing societal implications for safety-critical deployment. By consolidating theoretical foundations, practical advances, and broader impacts, this survey provides a unified perspective and roadmap toward certifiable, trustworthy perception for real-world applications. A continuously-updated literature summary and companion code tutorials are available at https://github.com/ericzzj1989/Awesome-Global-Solvers-for-3D-Vision.
Accelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
Non-Uniform Noise-to-Signal Ratio in the REINFORCE Policy-Gradient Estimator
Feb 01, 2026Policy-gradient methods are widely used in reinforcement learning, yet training often becomes unstable or slows down as learning progresses. We study this phenomenon through the noise-to-signal ratio (NSR) of a policy-gradient estimator, defined as the estimator variance (noise) normalized by the squared norm of the true gradient (signal). Our main result is that, for (i) finite-horizon linear systems with Gaussian policies and linear state-feedback, and (ii) finite-horizon polynomial systems with Gaussian policies and polynomial feedback, the NSR of the REINFORCE estimator can be characterized exactly-either in closed form or via numerical moment-evaluation algorithms-without approximation. For general nonlinear dynamics and expressive policies (including neural policies), we further derive a general upper bound on the variance. These characterizations enable a direct examination of how NSR varies across policy parameters and how it evolves along optimization trajectories (e.g. SGD and Adam). Across a range of examples, we find that the NSR landscape is highly non-uniform and typically increases as the policy approaches an optimum; in some regimes it blows up, which can trigger training instability and policy collapse.
Sparse Variable Projection in Robotic Perception: Exploiting Separable Structure for Efficient Nonlinear Optimization
Dec 08, 2025Robotic perception often requires solving large nonlinear least-squares (NLS) problems. While sparsity has been well-exploited to scale solvers, a complementary and underexploited structure is \emph{separability} -- where some variables (e.g., visual landmarks) appear linearly in the residuals and, for any estimate of the remaining variables (e.g., poses), have a closed-form solution. Variable projection (VarPro) methods are a family of techniques that exploit this structure by analytically eliminating the linear variables and presenting a reduced problem in the remaining variables that has favorable properties. However, VarPro has seen limited use in robotic perception; a major challenge arises from gauge symmetries (e.g., cost invariance to global shifts and rotations), which are common in perception and induce specific computational challenges in standard VarPro approaches. We present a VarPro scheme designed for problems with gauge symmetries that jointly exploits separability and sparsity. Our method can be applied as a one-time preprocessing step to construct a \emph{matrix-free Schur complement operator}. This operator allows efficient evaluation of costs, gradients, and Hessian-vector products of the reduced problem and readily integrates with standard iterative NLS solvers. We provide precise conditions under which our method applies, and describe extensions when these conditions are only partially met. Across synthetic and real benchmarks in SLAM, SNL, and SfM, our approach achieves up to \textbf{2$\times$--35$\times$ faster runtimes} than state-of-the-art methods while maintaining accuracy. We release an open-source C++ implementation and all datasets from our experiments.
Socrates-Mol: Self-Oriented Cognitive Reasoning through Autonomous Trial-and-Error with Empirical-Bayesian Screening for Molecules
Nov 14, 2025Molecular property prediction is fundamental to chemical engineering applications such as solvent screening. We present Socrates-Mol, a framework that transforms language models into empirical Bayesian reasoners through context engineering, addressing cold start problems without model fine-tuning. The system implements a reflective-prediction cycle where initial outputs serve as priors, retrieved molecular cases provide evidence, and refined predictions form posteriors, extracting reusable chemical rules from sparse data. We introduce ranking tasks aligned with industrial screening priorities and employ cross-model self-consistency across five language models to reduce variance. Experiments on amine solvent LogP prediction reveal task-dependent patterns: regression achieves 72% MAE reduction and 112% R-squared improvement through self-consistency, while ranking tasks show limited gains due to systematic multi-model biases. The framework reduces deployment costs by over 70% compared to full fine-tuning, providing a scalable solution for molecular property prediction while elucidating the task-adaptive nature of self-consistency mechanisms.
Compose by Focus: Scene Graph-based Atomic Skills
Sep 19, 2025
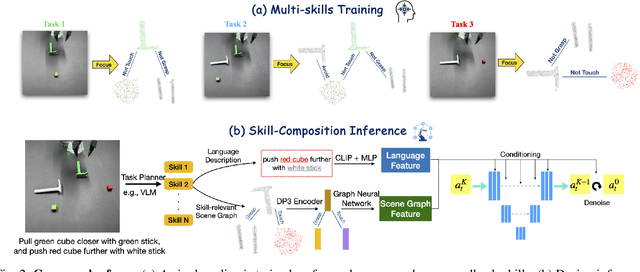
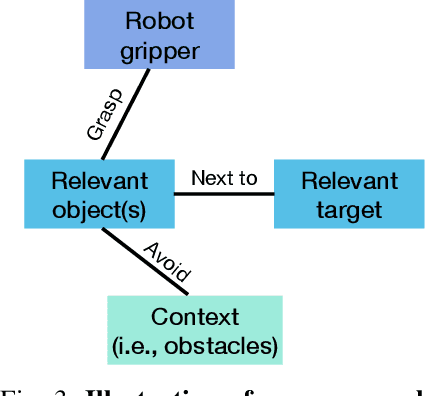
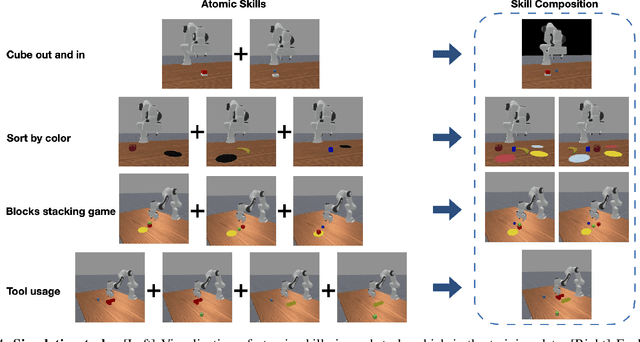
A key requirement for generalist robots is compositional generalization - the ability to combine atomic skills to solve complex, long-horizon tasks. While prior work has primarily focused on synthesizing a planner that sequences pre-learned skills, robust execution of the individual skills themselves remains challenging, as visuomotor policies often fail under distribution shifts induced by scene composition. To address this, we introduce a scene graph-based representation that focuses on task-relevant objects and relations, thereby mitigating sensitivity to irrelevant variation. Building on this idea, we develop a scene-graph skill learning framework that integrates graph neural networks with diffusion-based imitation learning, and further combine "focused" scene-graph skills with a vision-language model (VLM) based task planner. Experiments in both simulation and real-world manipulation tasks demonstrate substantially higher success rates than state-of-the-art baselines, highlighting improved robustness and compositional generalization in long-horizon tasks.
Leveraging Correlation Across Test Platforms for Variance-Reduced Metric Estimation
Jun 25, 2025



Learning-based robotic systems demand rigorous validation to assure reliable performance, but extensive real-world testing is often prohibitively expensive, and if conducted may still yield insufficient data for high-confidence guarantees. In this work, we introduce a general estimation framework that leverages paired data across test platforms, e.g., paired simulation and real-world observations, to achieve better estimates of real-world metrics via the method of control variates. By incorporating cheap and abundant auxiliary measurements (for example, simulator outputs) as control variates for costly real-world samples, our method provably reduces the variance of Monte Carlo estimates and thus requires significantly fewer real-world samples to attain a specified confidence bound on the mean performance. We provide theoretical analysis characterizing the variance and sample-efficiency improvement, and demonstrate empirically in autonomous driving and quadruped robotics settings that our approach achieves high-probability bounds with markedly improved sample efficiency. Our technique can lower the real-world testing burden for validating the performance of the stack, thereby enabling more efficient and cost-effective experimental evaluation of robotic systems.