 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA3D: Low-Rank Self-Calibration of 3D Geometric Foundation Models
Dec 10, 2024



Emerging 3D geometric foundation models, such as DUSt3R, offer a promising approach for in-the-wild 3D vision tasks. However, due to the high-dimensional nature of the problem space and scarcity of high-quality 3D data, these pre-trained models still struggle to generalize to many challenging circumstances, such as limited view overlap or low lighting. To address this, we propose LoRA3D, an efficient self-calibration pipeline to $\textit{specialize}$ the pre-trained models to target scenes using their own multi-view predictions. Taking sparse RGB images as input, we leverage robust optimization techniques to refine multi-view predictions and align them into a global coordinate frame. In particular, we incorporate prediction confidence into the geometric optimization process, automatically re-weighting the confidence to better reflect point estimation accuracy. We use the calibrated confidence to generate high-quality pseudo labels for the calibrating views and use low-rank adaptation (LoRA) to fine-tune the models on the pseudo-labeled data. Our method does not require any external priors or manual labels. It completes the self-calibration process on a $\textbf{single standard GPU within just 5 minutes}$. Each low-rank adapter requires only $\textbf{18MB}$ of storage. We evaluated our method on $\textbf{more than 160 scenes}$ from the Replica, TUM and Waymo Open datasets, achieving up to $\textbf{88% performance improvement}$ on 3D reconstruction, multi-view pose estimation and novel-view rendering.
3DGS-CD: 3D Gaussian Splatting-based Change Detection for Physical Object Rearrangement
Nov 06, 2024We present 3DGS-CD, the first 3D Gaussian Splatting (3DGS)-based method for detecting physical object rearrangements in 3D scenes. Our approach estimates 3D object-level changes by comparing two sets of unaligned images taken at different times. Leveraging 3DGS's novel view rendering and EfficientSAM's zero-shot segmentation capabilities, we detect 2D object-level changes, which are then associated and fused across views to estimate 3D changes. Our method can detect changes in cluttered environments using sparse post-change images within as little as 18s, using as few as a single new image. It does not rely on depth input, user instructions, object classes, or object models -- An object is recognized simply if it has been re-arranged. Our approach is evaluated on both public and self-collected real-world datasets, achieving up to 14% higher accuracy and three orders of magnitude faster performance compared to the state-of-the-art radiance-field-based change detection method. This significant performance boost enables a broad range of downstream applications, where we highlight three key use cases: object reconstruction, robot workspace reset, and 3DGS model update. Our code and data will be made available at https://github.com/520xyxyzq/3DGS-CD.
Fast Sparse View Guided NeRF Update for Object Reconfigurations
Mar 16, 2024Neural Radiance Field (NeRF), as an implicit 3D scene representation, lacks inherent ability to accommodate changes made to the initial static scene. If objects are reconfigured, it is difficult to update the NeRF to reflect the new state of the scene without time-consuming data re-capturing and NeRF re-training. To address this limitation, we develop the first update method for NeRFs to physical changes. Our method takes only sparse new images (e.g. 4) of the altered scene as extra inputs and update the pre-trained NeRF in around 1 to 2 minutes. Particularly, we develop a pipeline to identify scene changes and update the NeRF accordingly. Our core idea is the use of a second helper NeRF to learn the local geometry and appearance changes, which sidesteps the optimization difficulties in direct NeRF fine-tuning. The interpolation power of the helper NeRF is the key to accurately reconstruct the un-occluded objects regions under sparse view supervision. Our method imposes no constraints on NeRF pre-training, and requires no extra user input or explicit semantic priors. It is an order of magnitude faster than re-training NeRF from scratch while maintaining on-par and even superior performance.
Discrete-Continuous Smoothing and Mapping
Apr 25, 2022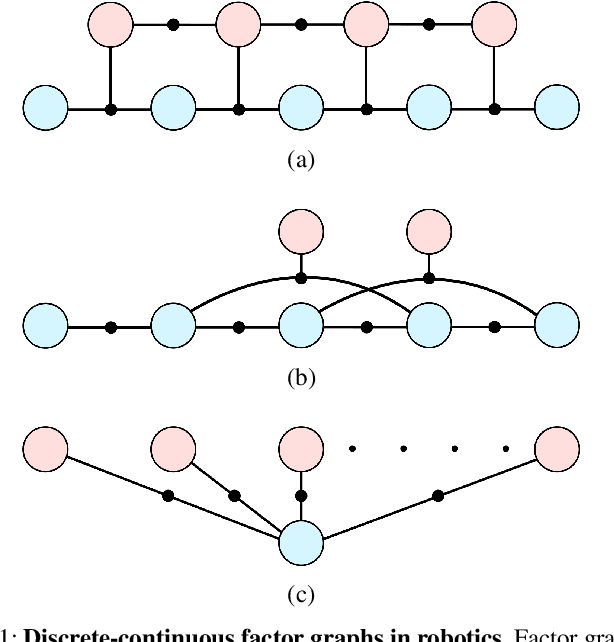
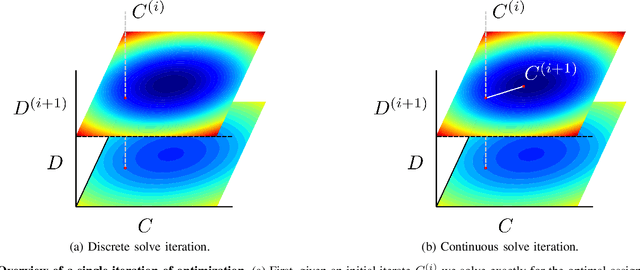


We describe a general approach to smoothing and mapping with a class of discrete-continuous factor graphs commonly encountered in robotics applications. While there are openly available tools providing flexible and easy-to-use interfaces for specifying and solving optimization problems formulated in terms of either discrete or continuous graphical models, at present, no similarly general tools exist enabling the same functionality for hybrid discrete-continuous problems. We aim to address this problem. In particular, we provide a library, DC-SAM, extending existing tools for optimization problems defined in terms of factor graphs to the setting of discrete-continuous models. A key contribution of our work is a novel solver for efficiently recovering approximate solutions to discrete-continuous optimization problems. The key insight to our approach is that while joint inference over continuous and discrete state spaces is often hard, many commonly encountered discrete-continuous problems can naturally be split into a "discrete part" and a "continuous part" that can individually be solved easily. Leveraging this structure, we optimize discrete and continuous variables in an alternating fashion. In consequence, our proposed work enables straightforward representation of and approximate inference in discrete-continuous graphical models. We also provide a method to recover the uncertainty in estimates of both discrete and continuous variables. We demonstrate the versatility of our approach through its application to three distinct robot perception applications: point-cloud registration, robust pose graph optimization, and object-based mapping and localization.
SLAM-Supported Self-Training for 6D Object Pose Estimation
Mar 29, 2022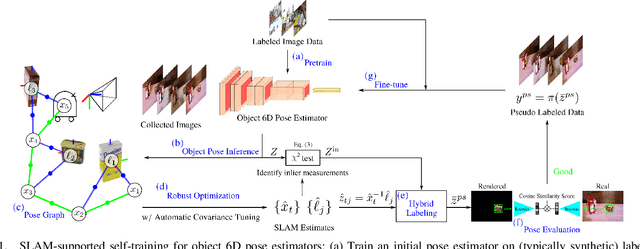
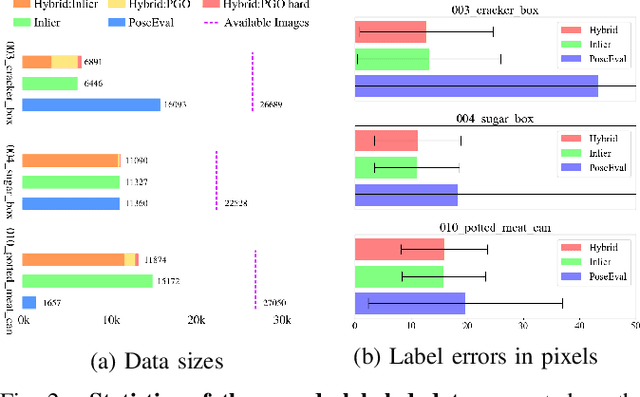
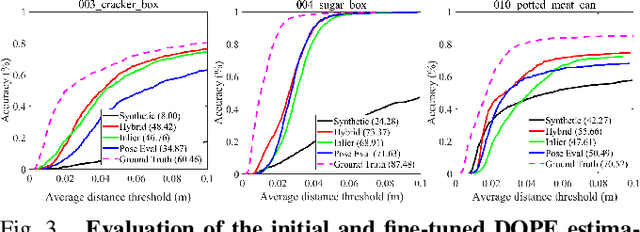

Recent progress in learning-based object pose estimation paves the way for developing richer object-level world representations. However, the estimators, often trained with out-of-domain data, can suffer performance degradation as deployed in novel environments. To address the problem, we present a SLAM-supported self-training procedure to autonomously improve robot object pose estimation ability during navigation. Combining the network predictions with robot odometry, we can build a consistent object-level environment map via pose graph optimization (PGO). Exploiting the state estimates from PGO, we pseudo-label robot-collected RGB images to fine-tune the pose estimators. Unfortunately, it is difficult to quantify the uncertainty of the estimator predictions. The unmodeled data uncertainty used for PGO can result in low-quality object pose estimates. An automatic covariance tuning method is developed for robust PGO by allowing the measurement uncertainty models to change as part of the optimization process. The formulation permits a straightforward alternating minimization procedure that re-scales covariances analytically and component-wise, enabling more flexible noise modeling for learning-based measurements. We test our method with the deep object pose estimator (DOPE) on the YCB video dataset and in real-world robot experiments. The method can achieve significant performance gain in pose estimation, and in return facilitates the success of object SLAM.
Consensus-Informed Optimization Over Mixtures for Ambiguity-Aware Object SLAM
Jul 20, 2021


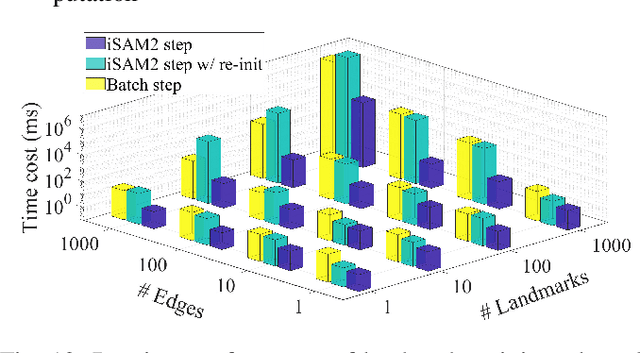
Objects could often have multiple probable poses in single-shot measurements due to symmetry, occlusion or perceptual failures. A robust object-level simultaneous localization and mapping (object SLAM) algorithm needs to be aware of the pose ambiguity. We propose to maintain and subsequently dis-ambiguate the multiple pose interpretations to gradually recover a globally consistent world representation. The max-mixtures model is applied to implicitly and efficiently track all pose hypotheses. The temporally consistent hypotheses are extracted to guide the optimization solution into the global optimum. This consensus-informed inference method is implemented on top of the incremental SLAM framework iSAM2, via landmark variable re-initialization.