 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Apr 28, 2024In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
Fast Sparse View Guided NeRF Update for Object Reconfigurations
Mar 16, 2024Neural Radiance Field (NeRF), as an implicit 3D scene representation, lacks inherent ability to accommodate changes made to the initial static scene. If objects are reconfigured, it is difficult to update the NeRF to reflect the new state of the scene without time-consuming data re-capturing and NeRF re-training. To address this limitation, we develop the first update method for NeRFs to physical changes. Our method takes only sparse new images (e.g. 4) of the altered scene as extra inputs and update the pre-trained NeRF in around 1 to 2 minutes. Particularly, we develop a pipeline to identify scene changes and update the NeRF accordingly. Our core idea is the use of a second helper NeRF to learn the local geometry and appearance changes, which sidesteps the optimization difficulties in direct NeRF fine-tuning. The interpolation power of the helper NeRF is the key to accurately reconstruct the un-occluded objects regions under sparse view supervision. Our method imposes no constraints on NeRF pre-training, and requires no extra user input or explicit semantic priors. It is an order of magnitude faster than re-training NeRF from scratch while maintaining on-par and even superior performance.
A Quantitative Evaluation of Score Distillation Sampling Based Text-to-3D
Feb 29, 2024The development of generative models that create 3D content from a text prompt has made considerable strides thanks to the use of the score distillation sampling (SDS) method on pre-trained diffusion models for image generation. However, the SDS method is also the source of several artifacts, such as the Janus problem, the misalignment between the text prompt and the generated 3D model, and 3D model inaccuracies. While existing methods heavily rely on the qualitative assessment of these artifacts through visual inspection of a limited set of samples, in this work we propose more objective quantitative evaluation metrics, which we cross-validate via human ratings, and show analysis of the failure cases of the SDS technique. We demonstrate the effectiveness of this analysis by designing a novel computationally efficient baseline model that achieves state-of-the-art performance on the proposed metrics while addressing all the above-mentioned artifacts.
Towards Visual Foundational Models of Physical Scenes
Jun 06, 2023



We describe a first step towards learning general-purpose visual representations of physical scenes using only image prediction as a training criterion. To do so, we first define "physical scene" and show that, even though different agents may maintain different representations of the same scene, the underlying physical scene that can be inferred is unique. Then, we show that NeRFs cannot represent the physical scene, as they lack extrapolation mechanisms. Those, however, could be provided by Diffusion Models, at least in theory. To test this hypothesis empirically, NeRFs can be combined with Diffusion Models, a process we refer to as NeRF Diffusion, used as unsupervised representations of the physical scene. Our analysis is limited to visual data, without external grounding mechanisms that can be provided by independent sensory modalities.
Single View Physical Distance Estimation using Human Pose
Jun 18, 2021
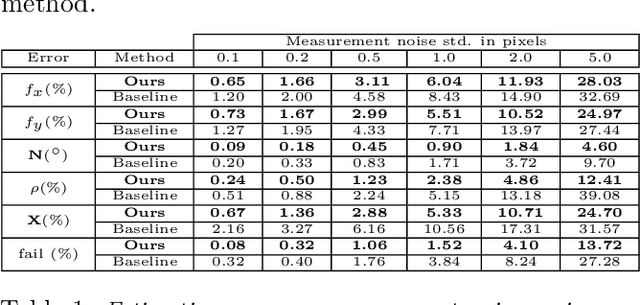
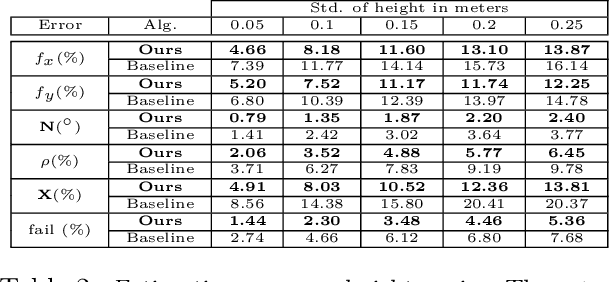
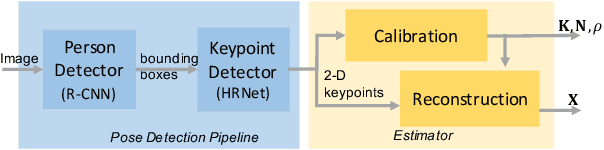
We propose a fully automated system that simultaneously estimates the camera intrinsics, the ground plane, and physical distances between people from a single RGB image or video captured by a camera viewing a 3-D scene from a fixed vantage point. To automate camera calibration and distance estimation, we leverage priors about human pose and develop a novel direct formulation for pose-based auto-calibration and distance estimation, which shows state-of-the-art performance on publicly available datasets. The proposed approach enables existing camera systems to measure physical distances without needing a dedicated calibration process or range sensors, and is applicable to a broad range of use cases such as social distancing and workplace safety. Furthermore, to enable evaluation and drive research in this area, we contribute to the publicly available MEVA dataset with additional distance annotations, resulting in MEVADA -- the first evaluation benchmark in the world for the pose-based auto-calibration and distance estimation problem.
An Adaptive Framework for Learning Unsupervised Depth Completion
Jun 06, 2021

We present a method to infer a dense depth map from a color image and associated sparse depth measurements. Our main contribution lies in the design of an annealing process for determining co-visibility (occlusions, disocclusions) and the degree of regularization to impose on the model. We show that regularization and co-visibility are related via the fitness (residual) of model to data and both can be unified into a single framework to improve the learning process. Our method is an adaptive weighting scheme that guides optimization by measuring the residual at each pixel location over each training step for (i) estimating a soft visibility mask and (ii) determining the amount of regularization. We demonstrate the effectiveness our method by applying it to several recent unsupervised depth completion methods and improving their performance on public benchmark datasets, without incurring additional trainable parameters or increase in inference time. Code available at: https://github.com/alexklwong/adaframe-depth-completion.
VOICED: Depth Completion from Inertial Odometry and Vision
May 15, 2019



We describe a method to infer dense depth from camera motion and sparse depth as estimated using a visual-inertial odometry system. Unlike other scenarios using point clouds from lidar or structured light sensors, we have few hundreds to few thousand points, insufficient to inform the topology of the scene. Our method first constructs a piecewise planar scaffolding of the scene, and then uses it to infer dense depth using the image along with the sparse points. We use a predictive cross-modal criterion, akin to `self-supervision,' measuring photometric consistency across time, forward-backward pose consistency, and geometric compatibility with the sparse point cloud. We also launch the first visual-inertial + depth dataset, which we hope will foster additional exploration into combining the complementary strengths of visual and inertial sensors. To compare our method to prior work, we adopt the unsupervised KITTI depth completion benchmark, and show state-of-the-art performance on it.
Geo-Supervised Visual Depth Prediction
Dec 12, 2018



We propose using global orientation from inertial measurements, and the bias it induces on the shape of objects populating the scene, to inform visual 3D reconstruction. We test the effect of using the resulting prior in depth prediction from a single image, where the normal vectors to surfaces of objects of certain classes tend to align with gravity or be orthogonal to it. Adding such a prior to baseline methods for monocular depth prediction yields improvements beyond the state-of-the-art and illustrates the power of gravity as a supervisory signal.
A Simple Hierarchical Pooling Data Structure for Loop Closure
Oct 23, 2018
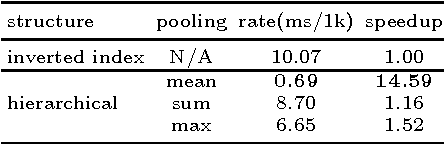
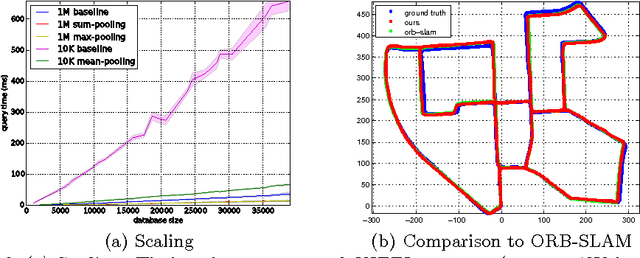

We propose a data structure obtained by hierarchically averaging bag-of-word descriptors during a sequence of views that achieves average speedups in large-scale loop closure applications ranging from 4 to 20 times on benchmark datasets. Although simple, the method works as well as sophisticated agglomerative schemes at a fraction of the cost with minimal loss of performance.
Visual-Inertial Object Detection and Mapping
Oct 23, 2018



We present a method to populate an unknown environment with models of previously seen objects, placed in a Euclidean reference frame that is inferred causally and on-line using monocular video along with inertial sensors. The system we implement returns a sparse point cloud for the regions of the scene that are visible but not recognized as a previously seen object, and a detailed object model and its pose in the Euclidean frame otherwise. The system includes bottom-up and top-down components, whereby deep networks trained for detection provide likelihood scores for object hypotheses provided by a nonlinear filter, whose state serves as memory. Additional networks provide likelihood scores for edges, which complements detection networks trained to be invariant to small deformations. We test our algorithm on existing datasets, and also introduce the VISMA dataset, that provides ground truth pose, point-cloud map, and object models, along with time-stamped inertial measurements.