 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Monocular Depth Priors in Visual-Inertial Initialization
Apr 20, 2022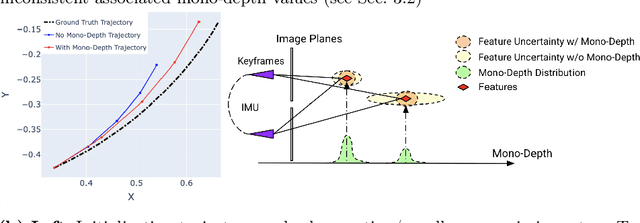
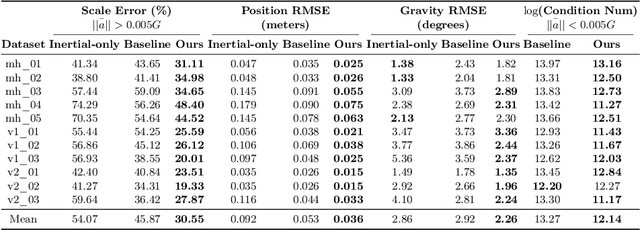
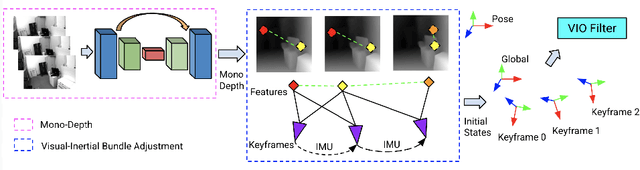
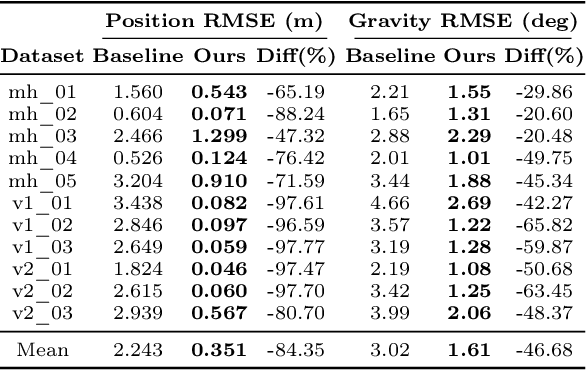
Visual-inertial odometry (VIO) is the pose estimation backbone for most AR/VR and autonomous robotic systems today, in both academia and industry. However, these systems are highly sensitive to the initialization of key parameters such as sensor biases, gravity direction, and metric scale. In practical scenarios where high-parallax or variable acceleration assumptions are rarely met (e.g. hovering aerial robot, smartphone AR user not gesticulating with phone), classical visual-inertial initialization formulations often become ill-conditioned and/or fail to meaningfully converge. In this paper we target visual-inertial initialization specifically for these low-excitation scenarios critical to in-the-wild usage. We propose to circumvent the limitations of classical visual-inertial structure-from-motion (SfM) initialization by incorporating a new learning-based measurement as a higher-level input. We leverage learned monocular depth images (mono-depth) to constrain the relative depth of features, and upgrade the mono-depth to metric scale by jointly optimizing for its scale and shift. Our experiments show a significant improvement in problem conditioning compared to a classical formulation for visual-inertial initialization, and demonstrate significant accuracy and robustness improvements relative to the state-of-the-art on public benchmarks, particularly under motion-restricted scenarios. We further extend this improvement to implementation within an existing odometry system to illustrate the impact of our improved initialization method on resulting tracking trajectories.
A Simple Hierarchical Pooling Data Structure for Loop Closure
Oct 23, 2018
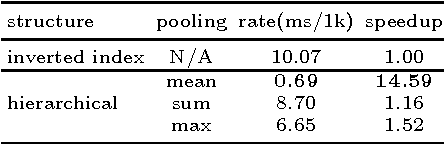
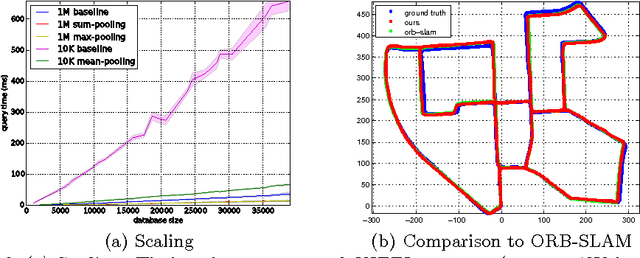

We propose a data structure obtained by hierarchically averaging bag-of-word descriptors during a sequence of views that achieves average speedups in large-scale loop closure applications ranging from 4 to 20 times on benchmark datasets. Although simple, the method works as well as sophisticated agglomerative schemes at a fraction of the cost with minimal loss of performance.
Observability, Identifiability and Sensitivity of Vision-Aided Navigation
Apr 26, 2015We analyze the observability of motion estimates from the fusion of visual and inertial sensors. Because the model contains unknown parameters, such as sensor biases, the problem is usually cast as a mixed identification/filtering, and the resulting observability analysis provides a necessary condition for any algorithm to converge to a unique point estimate. Unfortunately, most models treat sensor bias rates as noise, independent of other states including biases themselves, an assumption that is patently violated in practice. When this assumption is lifted, the resulting model is not observable, and therefore past analyses cannot be used to conclude that the set of states that are indistinguishable from the measurements is a singleton. In other words, the resulting model is not observable. We therefore re-cast the analysis as one of sensitivity: Rather than attempting to prove that the indistinguishable set is a singleton, which is not the case, we derive bounds on its volume, as a function of characteristics of the input and its sufficient excitation. This provides an explicit characterization of the indistinguishable set that can be used for analysis and validation purposes.
Robust Inference for Visual-Inertial Sensor Fusion
Dec 16, 2014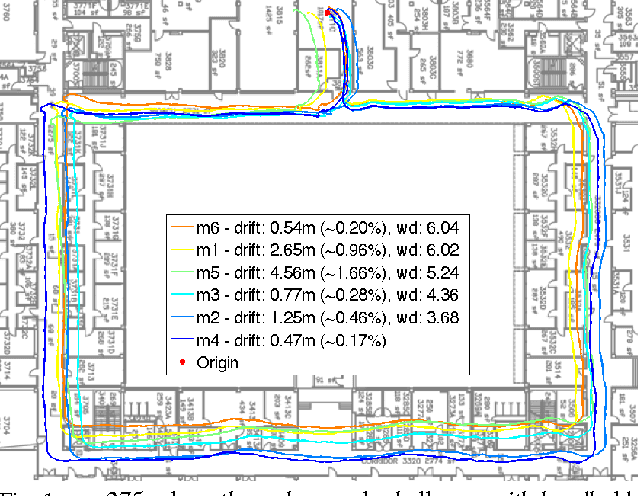
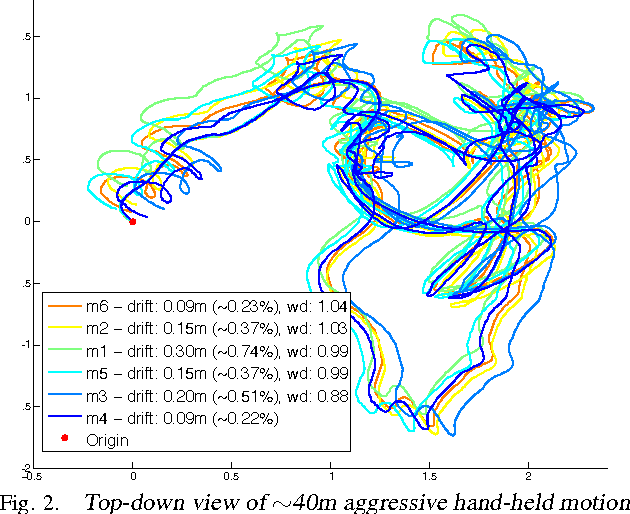

Inference of three-dimensional motion from the fusion of inertial and visual sensory data has to contend with the preponderance of outliers in the latter. Robust filtering deals with the joint inference and classification task of selecting which data fits the model, and estimating its state. We derive the optimal discriminant and propose several approximations, some used in the literature, others new. We compare them analytically, by pointing to the assumptions underlying their approximations, and empirically. We show that the best performing method improves the performance of state-of-the-art visual-inertial sensor fusion systems, while retaining the same computational complexity.