 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gaussian Splatting as Markov Chain Monte Carlo
Apr 15, 2024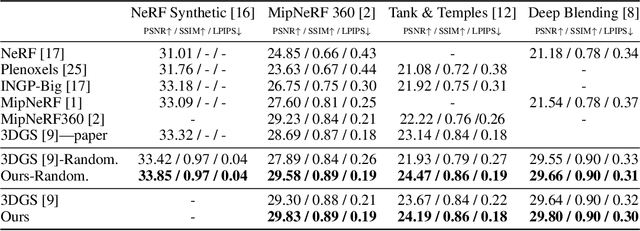


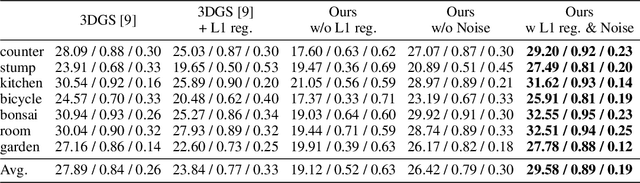
While 3D Gaussian Splatting has recently become popular for neural rendering, current methods rely on carefully engineered cloning and splitting strategies for placing Gaussians, which does not always generalize and may lead to poor-quality renderings. In addition, for real-world scenes, they rely on a good initial point cloud to perform well. In this work, we rethink 3D Gaussians as random samples drawn from an underlying probability distribution describing the physical representation of the scene -- in other words, Markov Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian updates are strikingly similar to a Stochastic Langevin Gradient Descent (SGLD) update. As with MCMC, samples are nothing but past visit locations, adding new Gaussians under our framework can simply be realized without heuristics as placing Gaussians at existing Gaussian locations. To encourage using fewer Gaussians for efficiency, we introduce an L1-regularizer on the Gaussians. On various standard evaluation scenes, we show that our method provides improved rendering quality, easy control over the number of Gaussians, and robustness to initialization.
Probing the 3D Awareness of Visual Foundation Models
Apr 12, 2024Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
SHINOBI: Shape and Illumination using Neural Object Decomposition via BRDF Optimization In-the-wild
Jan 18, 2024We present SHINOBI, an end-to-end framework for the reconstruction of shape, material, and illumination from object images captured with varying lighting, pose, and background. Inverse rendering of an object based on unconstrained image collections is a long-standing challenge in computer vision and graphics and requires a joint optimization over shape, radiance, and pose. We show that an implicit shape representation based on a multi-resolution hash encoding enables faster and robust shape reconstruction with joint camera alignment optimization that outperforms prior work. Further, to enable the editing of illumination and object reflectance (i.e. material) we jointly optimize BRDF and illumination together with the object's shape. Our method is class-agnostic and works on in-the-wild image collections of objects to produce relightable 3D assets for several use cases such as AR/VR, movies, games, etc. Project page: https://shinobi.aengelhardt.com Video: https://www.youtube.com/watch?v=iFENQ6AcYd8&feature=youtu.be
NeRFiller: Completing Scenes via Generative 3D Inpainting
Dec 07, 2023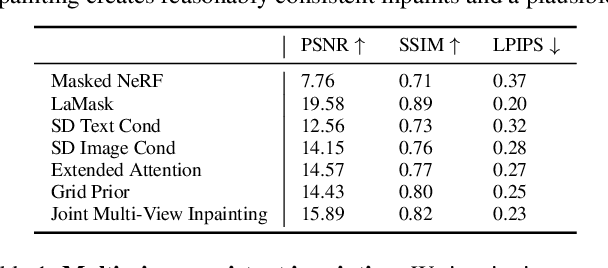

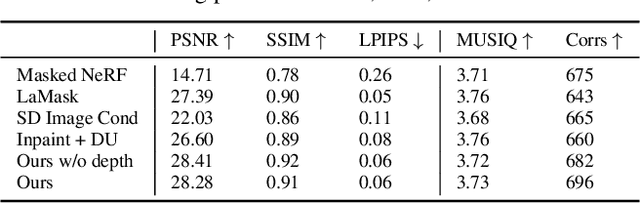

We propose NeRFiller, an approach that completes missing portions of a 3D capture via generative 3D inpainting using off-the-shelf 2D visual generative models. Often parts of a captured 3D scene or object are missing due to mesh reconstruction failures or a lack of observations (e.g., contact regions, such as the bottom of objects, or hard-to-reach areas). We approach this challenging 3D inpainting problem by leveraging a 2D inpainting diffusion model. We identify a surprising behavior of these models, where they generate more 3D consistent inpaints when images form a 2$\times$2 grid, and show how to generalize this behavior to more than four images. We then present an iterative framework to distill these inpainted regions into a single consistent 3D scene. In contrast to related works, we focus on completing scenes rather than deleting foreground objects, and our approach does not require tight 2D object masks or text. We compare our approach to relevant baselines adapted to our setting on a variety of scenes, where NeRFiller creates the most 3D consistent and plausible scene completions. Our project page is at https://ethanweber.me/nerfiller.
Accelerating Neural Field Training via Soft Mining
Nov 29, 2023We present an approach to accelerate Neural Field training by efficiently selecting sampling locations. While Neural Fields have recently become popular, it is often trained by uniformly sampling the training domain, or through handcrafted heuristics. We show that improved convergence and final training quality can be achieved by a soft mining technique based on importance sampling: rather than either considering or ignoring a pixel completely, we weigh the corresponding loss by a scalar. To implement our idea we use Langevin Monte-Carlo sampling. We show that by doing so, regions with higher error are being selected more frequently, leading to more than 2x improvement in convergence speed. The code and related resources for this study are publicly available at https://ubc-vision.github.io/nf-soft-mining/.
LU-NeRF: Scene and Pose Estimation by Synchronizing Local Unposed NeRFs
Jun 08, 2023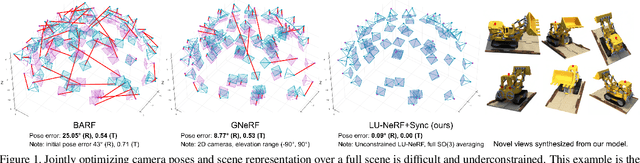
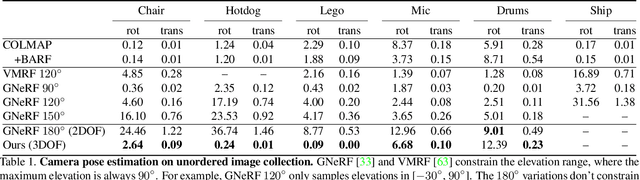
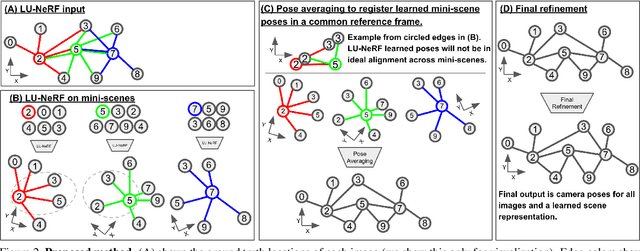
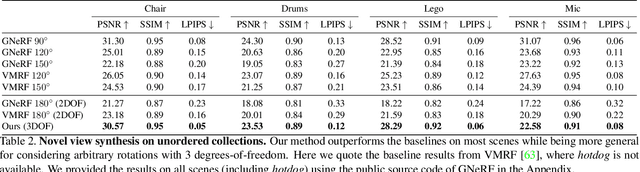
A critical obstacle preventing NeRF models from being deployed broadly in the wild is their reliance on accurate camera poses. Consequently, there is growing interest in extending NeRF models to jointly optimize camera poses and scene representation, which offers an alternative to off-the-shelf SfM pipelines which have well-understood failure modes. Existing approaches for unposed NeRF operate under limited assumptions, such as a prior pose distribution or coarse pose initialization, making them less effective in a general setting. In this work, we propose a novel approach, LU-NeRF, that jointly estimates camera poses and neural radiance fields with relaxed assumptions on pose configuration. Our approach operates in a local-to-global manner, where we first optimize over local subsets of the data, dubbed mini-scenes. LU-NeRF estimates local pose and geometry for this challenging few-shot task. The mini-scene poses are brought into a global reference frame through a robust pose synchronization step, where a final global optimization of pose and scene can be performed. We show our LU-NeRF pipeline outperforms prior attempts at unposed NeRF without making restrictive assumptions on the pose prior. This allows us to operate in the general SE(3) pose setting, unlike the baselines. Our results also indicate our model can be complementary to feature-based SfM pipelines as it compares favorably to COLMAP on low-texture and low-resolution images.
The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation
Jun 02, 2023Denoising diffusion probabilistic models have transformed image generation with their impressive fidelity and diversity. We show that they also excel in estimating optical flow and monocular depth, surprisingly, without task-specific architectures and loss functions that are predominant for these tasks. Compared to the point estimates of conventional regression-based methods, diffusion models also enable Monte Carlo inference, e.g., capturing uncertainty and ambiguity in flow and depth. With self-supervised pre-training, the combined use of synthetic and real data for supervised training, and technical innovations (infilling and step-unrolled denoising diffusion training) to handle noisy-incomplete training data, and a simple form of coarse-to-fine refinement, one can train state-of-the-art diffusion models for depth and optical flow estimation. Extensive experiments focus on quantitative performance against benchmarks, ablations, and the model's ability to capture uncertainty and multimodality, and impute missing values. Our model, DDVM (Denoising Diffusion Vision Model), obtains a state-of-the-art relative depth error of 0.074 on the indoor NYU benchmark and an Fl-all outlier rate of 3.26\% on the KITTI optical flow benchmark, about 25\% better than the best published method. For an overview see https://diffusion-vision.github.io.
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
$\text{DC}^2$: Dual-Camera Defocus Control by Learning to Refocus
Apr 06, 2023Smartphone cameras today are increasingly approaching the versatility and quality of professional cameras through a combination of hardware and software advancements. However, fixed aperture remains a key limitation, preventing users from controlling the depth of field (DoF) of captured images. At the same time, many smartphones now have multiple cameras with different fixed apertures -- specifically, an ultra-wide camera with wider field of view and deeper DoF and a higher resolution primary camera with shallower DoF. In this work, we propose $\text{DC}^2$, a system for defocus control for synthetically varying camera aperture, focus distance and arbitrary defocus effects by fusing information from such a dual-camera system. Our key insight is to leverage real-world smartphone camera dataset by using image refocus as a proxy task for learning to control defocus. Quantitative and qualitative evaluations on real-world data demonstrate our system's efficacy where we outperform state-of-the-art on defocus deblurring, bokeh rendering, and image refocus. Finally, we demonstrate creative post-capture defocus control enabled by our method, including tilt-shift and content-based defocus effects.
ASIC: Aligning Sparse in-the-wild Image Collections
Mar 28, 2023We present a method for joint alignment of sparse in-the-wild image collections of an object category. Most prior works assume either ground-truth keypoint annotations or a large dataset of images of a single object category. However, neither of the above assumptions hold true for the long-tail of the objects present in the world. We present a self-supervised technique that directly optimizes on a sparse collection of images of a particular object/object category to obtain consistent dense correspondences across the collection. We use pairwise nearest neighbors obtained from deep features of a pre-trained vision transformer (ViT) model as noisy and sparse keypoint matches and make them dense and accurate matches by optimizing a neural network that jointly maps the image collection into a learned canonical grid. Experiments on CUB and SPair-71k benchmarks demonstrate that our method can produce globally consistent and higher quality correspondences across the image collection when compared to existing self-supervised methods. Code and other material will be made available at \url{https://kampta.github.io/asic}.