 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Image Tokenizer
Dec 12, 2024



Image tokenizers map images to sequences of discrete tokens, and are a crucial component of autoregressive transformer-based image generation. The tokens are typically associated with spatial locations in the input image, arranged in raster scan order, which is not ideal for autoregressive modeling. In this paper, we propose to tokenize the image spectrum instead, obtained from a discrete wavelet transform (DWT), such that the sequence of tokens represents the image in a coarse-to-fine fashion. Our tokenizer brings several advantages: 1) it leverages that natural images are more compressible at high frequencies, 2) it can take and reconstruct images of different resolutions without retraining, 3) it improves the conditioning for next-token prediction -- instead of conditioning on a partial line-by-line reconstruction of the image, it takes a coarse reconstruction of the full image, 4) it enables partial decoding where the first few generated tokens can reconstruct a coarse version of the image, 5) it enables autoregressive models to be used for image upsampling. We evaluate the tokenizer reconstruction metrics as well as multiscale image generation, text-guided image upsampling and editing.
Four-Plane Factorized Video Autoencoders
Dec 05, 2024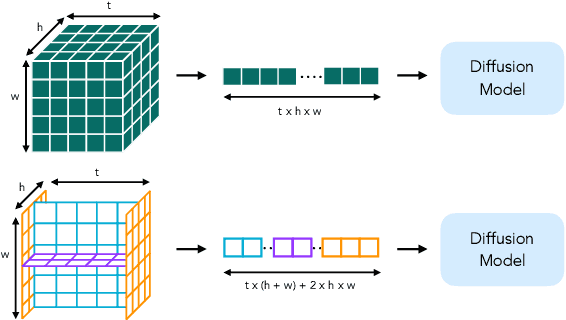
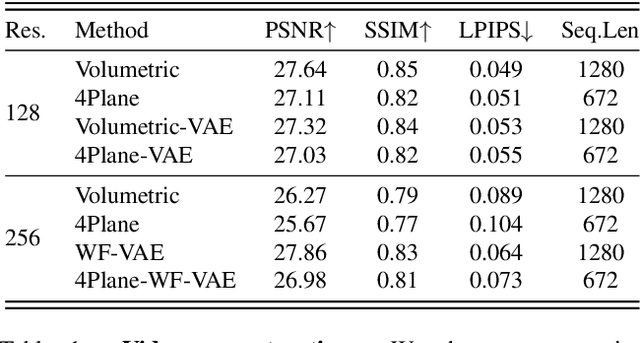
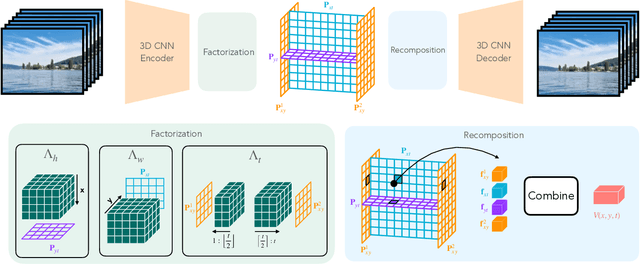

Latent variable generative models have emerged as powerful tools for generative tasks including image and video synthesis. These models are enabled by pretrained autoencoders that map high resolution data into a compressed lower dimensional latent space, where the generative models can subsequently be developed while requiring fewer computational resources. Despite their effectiveness, the direct application of latent variable models to higher dimensional domains such as videos continues to pose challenges for efficient training and inference. In this paper, we propose an autoencoder that projects volumetric data onto a four-plane factorized latent space that grows sublinearly with the input size, making it ideal for higher dimensional data like videos. The design of our factorized model supports straightforward adoption in a number of conditional generation tasks with latent diffusion models (LDMs), such as class-conditional generation, frame prediction, and video interpolation. Our results show that the proposed four-plane latent space retains a rich representation needed for high-fidelity reconstructions despite the heavy compression, while simultaneously enabling LDMs to operate with significant improvements in speed and memory.
Single Mesh Diffusion Models with Field Latents for Texture Generation
Dec 14, 2023



We introduce a framework for intrinsic latent diffusion models operating directly on the surfaces of 3D shapes, with the goal of synthesizing high-quality textures. Our approach is underpinned by two contributions: field latents, a latent representation encoding textures as discrete vector fields on the mesh vertices, and field latent diffusion models, which learn to denoise a diffusion process in the learned latent space on the surface. We consider a single-textured-mesh paradigm, where our models are trained to generate variations of a given texture on a mesh. We show the synthesized textures are of superior fidelity compared those from existing single-textured-mesh generative models. Our models can also be adapted for user-controlled editing tasks such as inpainting and label-guided generation. The efficacy of our approach is due in part to the equivariance of our proposed framework under isometries, allowing our models to seamlessly reproduce details across locally similar regions and opening the door to a notion of generative texture transfer.
Learning to Transform for Generalizable Instance-wise Invariance
Sep 28, 2023Computer vision research has long aimed to build systems that are robust to spatial transformations found in natural data. Traditionally, this is done using data augmentation or hard-coding invariances into the architecture. However, too much or too little invariance can hurt, and the correct amount is unknown a priori and dependent on the instance. Ideally, the appropriate invariance would be learned from data and inferred at test-time. We treat invariance as a prediction problem. Given any image, we use a normalizing flow to predict a distribution over transformations and average the predictions over them. Since this distribution only depends on the instance, we can align instances before classifying them and generalize invariance across classes. The same distribution can also be used to adapt to out-of-distribution poses. This normalizing flow is trained end-to-end and can learn a much larger range of transformations than Augerino and InstaAug. When used as data augmentation, our method shows accuracy and robustness gains on CIFAR 10, CIFAR10-LT, and TinyImageNet.
Scaling Spherical CNNs
Jun 08, 2023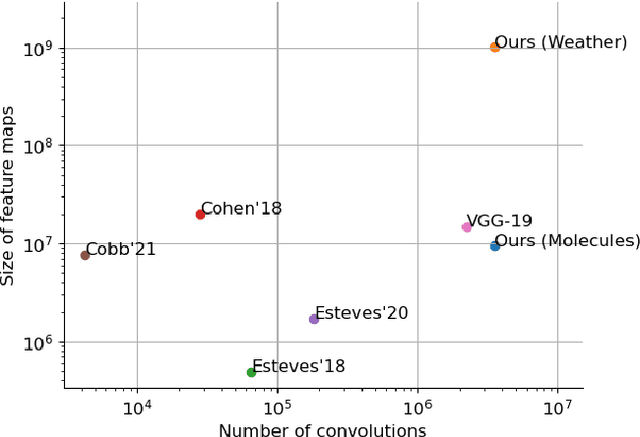
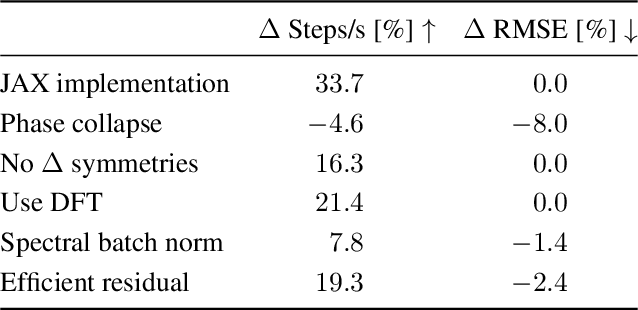
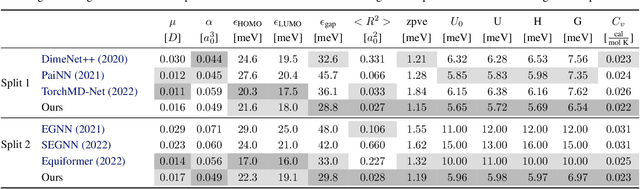
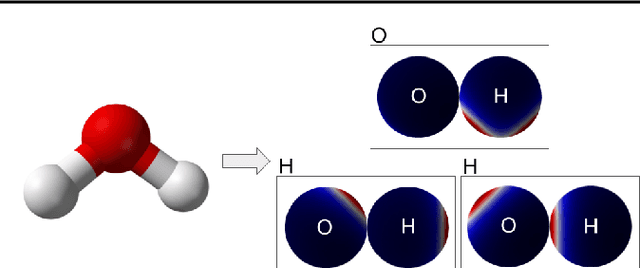
Spherical CNNs generalize CNNs to functions on the sphere, by using spherical convolutions as the main linear operation. The most accurate and efficient way to compute spherical convolutions is in the spectral domain (via the convolution theorem), which is still costlier than the usual planar convolutions. For this reason, applications of spherical CNNs have so far been limited to small problems that can be approached with low model capacity. In this work, we show how spherical CNNs can be scaled for much larger problems. To achieve this, we make critical improvements including novel variants of common model components, an implementation of core operations to exploit hardware accelerator characteristics, and application-specific input representations that exploit the properties of our model. Experiments show our larger spherical CNNs reach state-of-the-art on several targets of the QM9 molecular benchmark, which was previously dominated by equivariant graph neural networks, and achieve competitive performance on multiple weather forecasting tasks. Our code is available at https://github.com/google-research/spherical-cnn.
LU-NeRF: Scene and Pose Estimation by Synchronizing Local Unposed NeRFs
Jun 08, 2023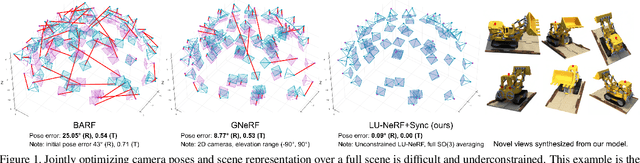
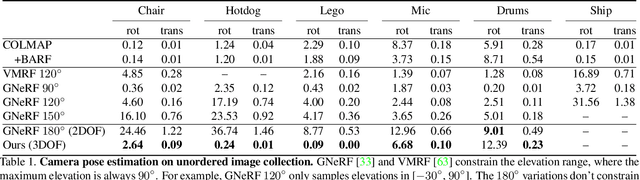
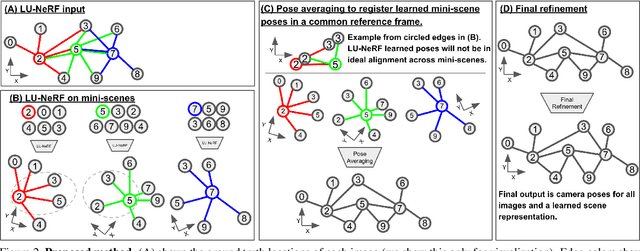
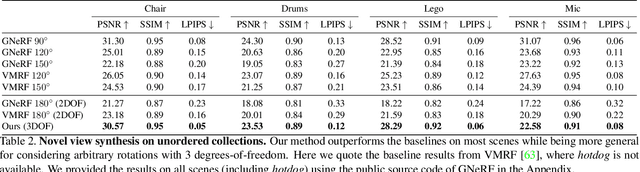
A critical obstacle preventing NeRF models from being deployed broadly in the wild is their reliance on accurate camera poses. Consequently, there is growing interest in extending NeRF models to jointly optimize camera poses and scene representation, which offers an alternative to off-the-shelf SfM pipelines which have well-understood failure modes. Existing approaches for unposed NeRF operate under limited assumptions, such as a prior pose distribution or coarse pose initialization, making them less effective in a general setting. In this work, we propose a novel approach, LU-NeRF, that jointly estimates camera poses and neural radiance fields with relaxed assumptions on pose configuration. Our approach operates in a local-to-global manner, where we first optimize over local subsets of the data, dubbed mini-scenes. LU-NeRF estimates local pose and geometry for this challenging few-shot task. The mini-scene poses are brought into a global reference frame through a robust pose synchronization step, where a final global optimization of pose and scene can be performed. We show our LU-NeRF pipeline outperforms prior attempts at unposed NeRF without making restrictive assumptions on the pose prior. This allows us to operate in the general SE(3) pose setting, unlike the baselines. Our results also indicate our model can be complementary to feature-based SfM pipelines as it compares favorably to COLMAP on low-texture and low-resolution images.
ASIC: Aligning Sparse in-the-wild Image Collections
Mar 28, 2023We present a method for joint alignment of sparse in-the-wild image collections of an object category. Most prior works assume either ground-truth keypoint annotations or a large dataset of images of a single object category. However, neither of the above assumptions hold true for the long-tail of the objects present in the world. We present a self-supervised technique that directly optimizes on a sparse collection of images of a particular object/object category to obtain consistent dense correspondences across the collection. We use pairwise nearest neighbors obtained from deep features of a pre-trained vision transformer (ViT) model as noisy and sparse keypoint matches and make them dense and accurate matches by optimizing a neural network that jointly maps the image collection into a learned canonical grid. Experiments on CUB and SPair-71k benchmarks demonstrate that our method can produce globally consistent and higher quality correspondences across the image collection when compared to existing self-supervised methods. Code and other material will be made available at \url{https://kampta.github.io/asic}.
Stable Object Reorientation using Contact Plane Registration
Aug 18, 2022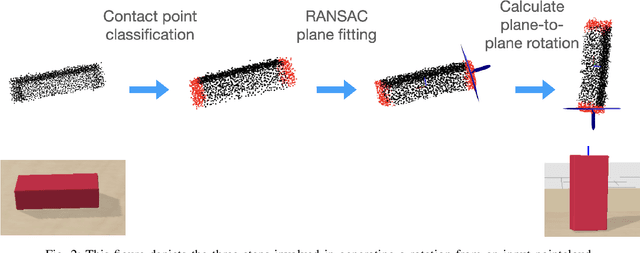
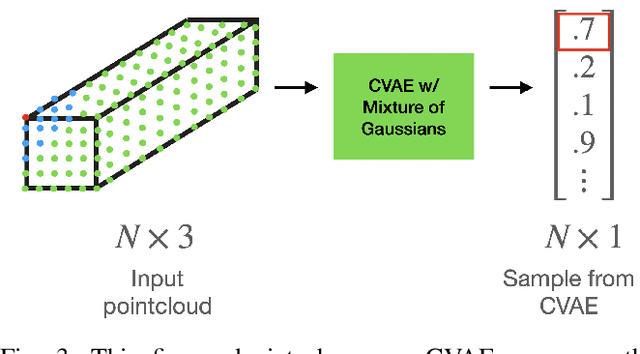
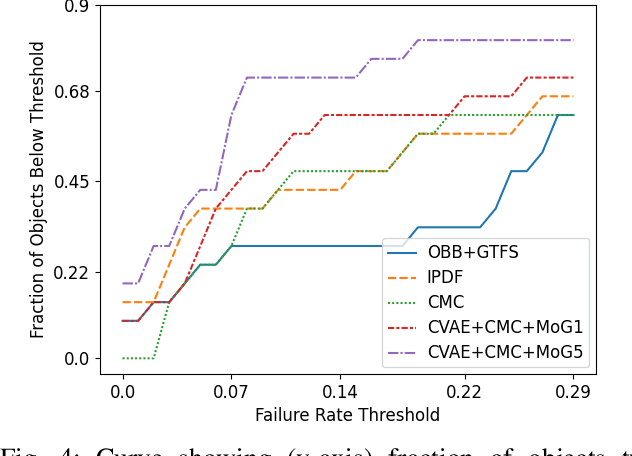
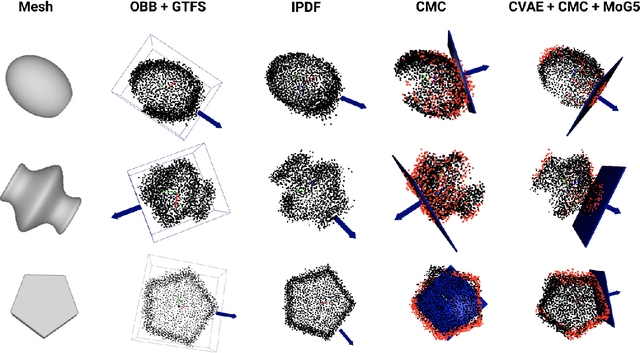
We present a system for accurately predicting stable orientations for diverse rigid objects. We propose to overcome the critical issue of modelling multimodality in the space of rotations by using a conditional generative model to accurately classify contact surfaces. Our system is capable of operating from noisy and partially-observed pointcloud observations captured by real world depth cameras. Our method substantially outperforms the current state-of-the-art systems on a simulated stacking task requiring highly accurate rotations, and demonstrates strong sim2real zero-shot transfer results across a variety of unseen objects on a real world reorientation task. Project website: \url{https://richardrl.github.io/stable-reorientation/}
* 7 pages, 1 additional page for references
Generalizable Patch-Based Neural Rendering
Jul 28, 2022
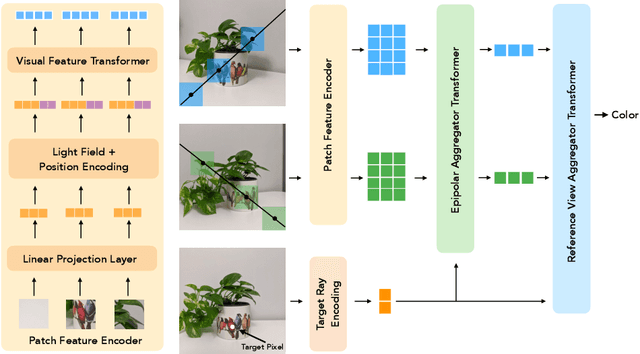
Neural rendering has received tremendous attention since the advent of Neural Radiance Fields (NeRF), and has pushed the state-of-the-art on novel-view synthesis considerably. The recent focus has been on models that overfit to a single scene, and the few attempts to learn models that can synthesize novel views of unseen scenes mostly consist of combining deep convolutional features with a NeRF-like model. We propose a different paradigm, where no deep features and no NeRF-like volume rendering are needed. Our method is capable of predicting the color of a target ray in a novel scene directly, just from a collection of patches sampled from the scene. We first leverage epipolar geometry to extract patches along the epipolar lines of each reference view. Each patch is linearly projected into a 1D feature vector and a sequence of transformers process the collection. For positional encoding, we parameterize rays as in a light field representation, with the crucial difference that the coordinates are canonicalized with respect to the target ray, which makes our method independent of the reference frame and improves generalization. We show that our approach outperforms the state-of-the-art on novel view synthesis of unseen scenes even when being trained with considerably less data than prior work.
Light Field Neural Rendering
Dec 17, 2021

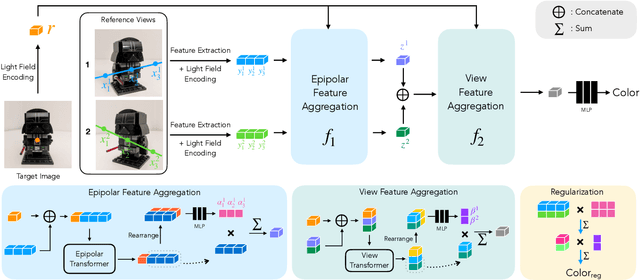
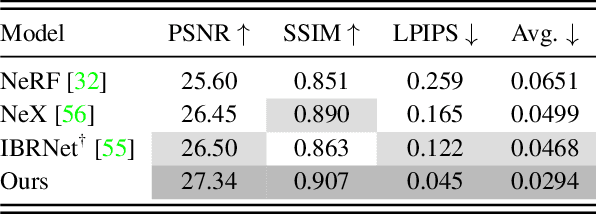
Classical light field rendering for novel view synthesis can accurately reproduce view-dependent effects such as reflection, refraction, and translucency, but requires a dense view sampling of the scene. Methods based on geometric reconstruction need only sparse views, but cannot accurately model non-Lambertian effects. We introduce a model that combines the strengths and mitigates the limitations of these two directions. By operating on a four-dimensional representation of the light field, our model learns to represent view-dependent effects accurately. By enforcing geometric constraints during training and inference, the scene geometry is implicitly learned from a sparse set of views. Concretely, we introduce a two-stage transformer-based model that first aggregates features along epipolar lines, then aggregates features along reference views to produce the color of a target ray. Our model outperforms the state-of-the-art on multiple forward-facing and 360{\deg} datasets, with larger margins on scenes with severe view-dependent variations.