 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters When Cotraining Robot Manipulation Policies on Everyday Human Videos?
Jun 04, 2026Human video datasets used for cotraining robot manipulation policies largely consist of curated demonstrations where motions are orchestrated to resemble robot behavior and 3D hand poses are captured with specialized hardware. A more plentiful source of data is everyday Internet video, but it is an open question what factors enable transfer from such videos to robots. We investigate this using a new dataset of 532 human videos with 28 hours of high-quality triangulated hand labels and natural motions. We find that hand pose quality affects transfer, but even with accurate hands, the inherent motion gap hinders transfer unless the vision and policy networks specialize to each embodiment. Our cotraining recipe yields consistent improvements, with an absolute success rate gain of $29.7\%$ in the low-robot-data regime across six manipulation tasks.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
UMArm: Untethered, Modular, Wearable, Soft Pneumatic Arm
May 16, 2025Robotic arms are essential to modern industries, however, their adaptability to unstructured environments remains limited. Soft robotic arms, particularly those actuated pneumatically, offer greater adaptability in unstructured environments and enhanced safety for human-robot interaction. However, current pneumatic soft arms are constrained by limited degrees of freedom, precision, payload capacity, and reliance on bulky external pressure regulators. In this work, a novel pneumatically driven rigid-soft hybrid arm, ``UMArm'', is presented. The shortcomings of pneumatically actuated soft arms are addressed by densely integrating high-force-to-weight-ratio, self-regulated McKibben actuators onto a lightweight rigid spine structure. The modified McKibben actuators incorporate valves and controllers directly inside, eliminating the need for individual pressure lines and external regulators, significantly reducing system weight and complexity. Full untethered operation, high payload capacity, precision, and directionally tunable compliance are achieved by the UMArm. Portability is demonstrated through a wearable assistive arm experiment, and versatility is showcased by reconfiguring the system into an inchworm robot. The results of this work show that the high-degree-of-freedom, external-regulator-free pneumatically driven arm systems like the UMArm possess great potential for real-world unstructured environments.
Semantic Revolution from Communications to Orchestration for 6G: Challenges, Enablers, and Research Directions
Jun 24, 2024In the context of emerging 6G services, the realization of everything-to-everything interactions involving a myriad of physical and digital entities presents a crucial challenge. This challenge is exacerbated by resource scarcity in communication infrastructures, necessitating innovative solutions for effective service implementation. Exploring the potential of Semantic Communications (SemCom) to enhance point-to-point physical layer efficiency shows great promise in addressing this challenge. However, achieving efficient SemCom requires overcoming the significant hurdle of knowledge sharing between semantic decoders and encoders, particularly in the dynamic and non-stationary environment with stringent end-to-end quality requirements. To bridge this gap in existing literature, this paper introduces the Knowledge Base Management And Orchestration (KB-MANO) framework. Rooted in the concepts of Computing-Network Convergence (CNC) and lifelong learning, KB-MANO is crafted for the allocation of network and computing resources dedicated to updating and redistributing KBs across the system. The primary objective is to minimize the impact of knowledge management activities on actual service provisioning. A proof-of-concept is proposed to showcase the integration of KB-MANO with resource allocation in radio access networks. Finally, the paper offers insights into future research directions, emphasizing the transformative potential of semantic-oriented communication systems in the realm of 6G technology.
Towards a Dynamic Future with Adaptable Computing and Network Convergence (ACNC)
Mar 12, 2024



In the context of advancing 6G, a substantial paradigm shift is anticipated, highlighting comprehensive everything-to-everything interactions characterized by numerous connections and stringent adherence to Quality of Service/Experience (QoS/E) prerequisites. The imminent challenge stems from resource scarcity, prompting a deliberate transition to Computing-Network Convergence (CNC) as an auspicious approach for joint resource orchestration. While CNC-based mechanisms have garnered attention, their effectiveness in realizing future services, particularly in use cases like the Metaverse, may encounter limitations due to the continually changing nature of users, services, and resources. Hence, this paper presents the concept of Adaptable CNC (ACNC) as an autonomous Machine Learning (ML)-aided mechanism crafted for the joint orchestration of computing and network resources, catering to dynamic and voluminous user requests with stringent requirements. ACNC encompasses two primary functionalities: state recognition and context detection. Given the intricate nature of the user-service-computing-network space, the paper employs dimension reduction to generate live, holistic, abstract system states in a hierarchical structure. To address the challenges posed by dynamic changes, Continual Learning (CL) is employed, classifying the system state into contexts controlled by dedicated ML agents, enabling them to operate efficiently. These two functionalities are intricately linked within a closed loop overseen by the End-to-End (E2E) orchestrator to allocate resources. The paper introduces the components of ACNC, proposes a Metaverse scenario to exemplify ACNC's role in resource provisioning with Segment Routing v6 (SRv6), outlines ACNC's workflow, details a numerical analysis for efficiency assessment, and concludes with discussions on relevant challenges and potential avenues for future research.
The Invisible Map: Visual-Inertial SLAM with Fiducial Markers for Smartphone-based Indoor Navigation
Oct 16, 2023We present a system for creating building-scale, easily navigable 3D maps using mainstream smartphones. In our approach, we formulate the 3D-mapping problem as an instance of Graph SLAM and infer the position of both building landmarks (fiducial markers) and navigable paths through the environment (phone poses). Our results demonstrate the system's ability to create accurate 3D maps. Further, we highlight the importance of careful selection of mapping hyperparameters and provide a novel technique for tuning these hyperparameters to adapt our algorithm to new environments.
Self-Sustaining Multiple Access with Continual Deep Reinforcement Learning for Dynamic Metaverse Applications
Sep 18, 2023The Metaverse is a new paradigm that aims to create a virtual environment consisting of numerous worlds, each of which will offer a different set of services. To deal with such a dynamic and complex scenario, considering the stringent quality of service requirements aimed at the 6th generation of communication systems (6G), one potential approach is to adopt self-sustaining strategies, which can be realized by employing Adaptive Artificial Intelligence (Adaptive AI) where models are continually re-trained with new data and conditions. One aspect of self-sustainability is the management of multiple access to the frequency spectrum. Although several innovative methods have been proposed to address this challenge, mostly using Deep Reinforcement Learning (DRL), the problem of adapting agents to a non-stationary environment has not yet been precisely addressed. This paper fills in the gap in the current literature by investigating the problem of multiple access in multi-channel environments to maximize the throughput of the intelligent agent when the number of active User Equipments (UEs) may fluctuate over time. To solve the problem, a Double Deep Q-Learning (DDQL) technique empowered by Continual Learning (CL) is proposed to overcome the non-stationary situation, while the environment is unknown. Numerical simulations demonstrate that, compared to other well-known methods, the CL-DDQL algorithm achieves significantly higher throughputs with a considerably shorter convergence time in highly dynamic scenarios.
Exploring and Characterizing Large Language Models For Embedded System Development and Debugging
Jul 07, 2023Large language models (LLMs) have shown remarkable abilities to generate code, however their ability to develop software for embedded systems, which requires cross-domain knowledge of hardware and software has not been studied. In this paper we systematically evaluate leading LLMs (GPT-3.5, GPT-4, PaLM 2) to assess their performance for embedded system development, study how human programmers interact with these tools, and develop an AI-based software engineering workflow for building embedded systems. We develop an an end-to-end hardware-in-the-loop evaluation platform for verifying LLM generated programs using sensor actuator pairs. We compare all three models with N=450 experiments and find surprisingly that GPT-4 especially shows an exceptional level of cross-domain understanding and reasoning, in some cases generating fully correct programs from a single prompt. In N=50 trials, GPT-4 produces functional I2C interfaces 66% of the time. GPT-4 also produces register-level drivers, code for LoRa communication, and context-specific power optimizations for an nRF52 program resulting in over 740x current reduction to 12.2 uA. We also characterize the models' limitations to develop a generalizable workflow for using LLMs in embedded system development. We evaluate the workflow with 15 users including novice and expert programmers. We find that our workflow improves productivity for all users and increases the success rate for building a LoRa environmental sensor from 25% to 100%, including for users with zero hardware or C/C++ experience.
Stable Object Reorientation using Contact Plane Registration
Aug 18, 2022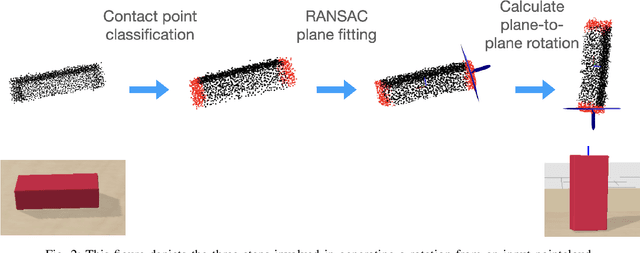
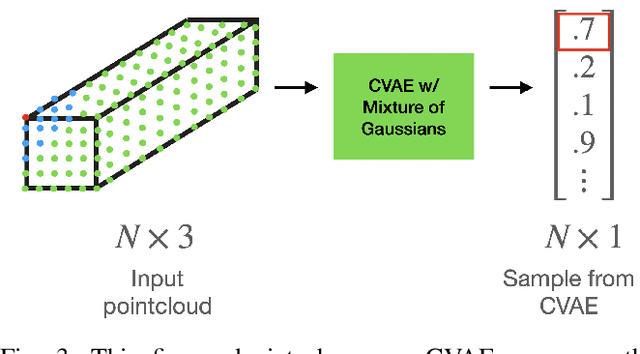
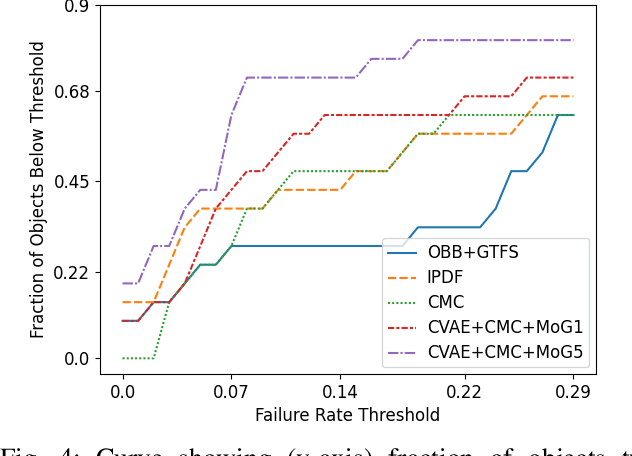
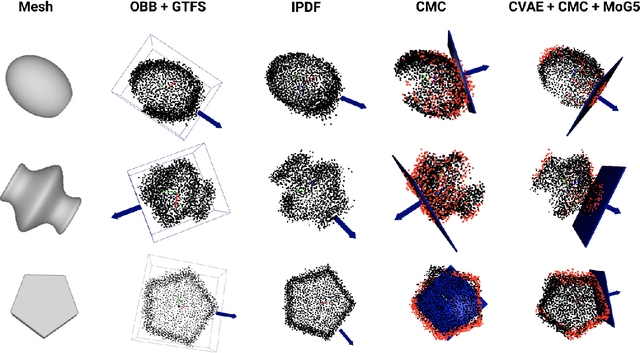
We present a system for accurately predicting stable orientations for diverse rigid objects. We propose to overcome the critical issue of modelling multimodality in the space of rotations by using a conditional generative model to accurately classify contact surfaces. Our system is capable of operating from noisy and partially-observed pointcloud observations captured by real world depth cameras. Our method substantially outperforms the current state-of-the-art systems on a simulated stacking task requiring highly accurate rotations, and demonstrates strong sim2real zero-shot transfer results across a variety of unseen objects on a real world reorientation task. Project website: \url{https://richardrl.github.io/stable-reorientation/}
* 7 pages, 1 additional page for references
Forecasting Future World Events with Neural Networks
Jun 30, 2022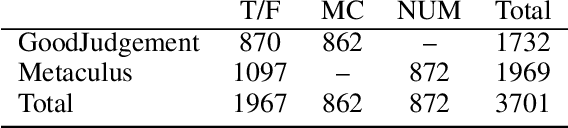
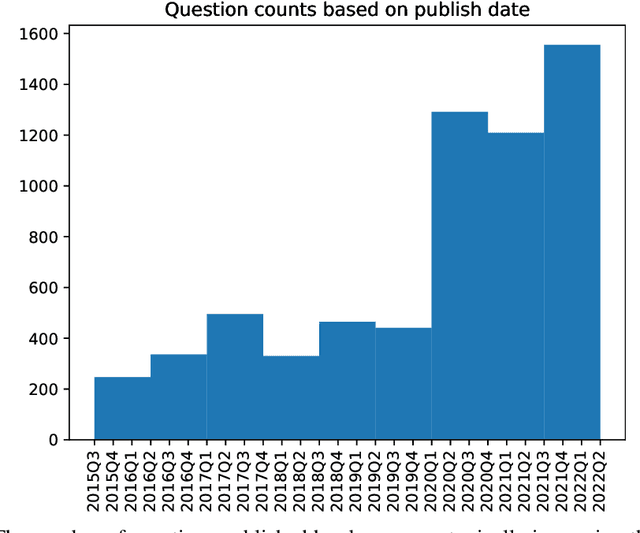
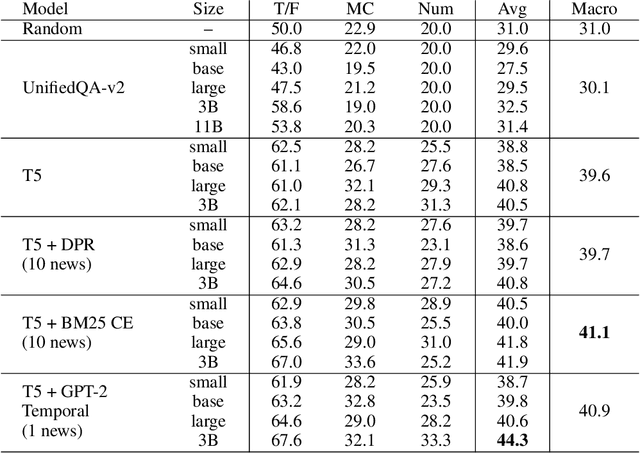

Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration. We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits.