 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvFill: Model Collaboration for Responsive Conversational Voice Agents
Nov 10, 2025Deploying conversational voice agents with large language models faces a critical challenge: cloud-based foundation models provide deep reasoning and domain knowledge but introduce latency that disrupts natural conversation, while on-device models respond immediately but lack sophistication. We propose conversational infill, a task where a lightweight on-device model generates contextually appropriate dialogue while seamlessly incorporating streaming knowledge from a powerful backend model. This approach decouples response latency from model capability, enabling systems that feel responsive while accessing the full power of large-scale models. We present ConvFill, a 360M parameter model trained on synthetic multi-domain conversations. Evaluation across multiple backend models shows that conversational infill can be successfully learned, with ConvFill achieving accuracy improvements of 36-42% over standalone small models of the same size while consistently retaining sub-200ms response latencies. Our results demonstrate the promise of this approach for building on-device conversational agents that are both immediately responsive and knowledgeable.
SnappyMeal: Design and Longitudinal Evaluation of a Multimodal AI Food Logging Application
Nov 05, 2025Food logging, both self-directed and prescribed, plays a critical role in uncovering correlations between diet, medical, fitness, and health outcomes. Through conversations with nutritional experts and individuals who practice dietary tracking, we find current logging methods, such as handwritten and app-based journaling, are inflexible and result in low adherence and potentially inaccurate nutritional summaries. These findings, corroborated by prior literature, emphasize the urgent need for improved food logging methods. In response, we propose SnappyMeal, an AI-powered dietary tracking system that leverages multimodal inputs to enable users to more flexibly log their food intake. SnappyMeal introduces goal-dependent follow-up questions to intelligently seek missing context from the user and information retrieval from user grocery receipts and nutritional databases to improve accuracy. We evaluate SnappyMeal through publicly available nutrition benchmarks and a multi-user, 3-week, in-the-wild deployment capturing over 500 logged food instances. Users strongly praised the multiple available input methods and reported a strong perceived accuracy. These insights suggest that multimodal AI systems can be leveraged to significantly improve dietary tracking flexibility and context-awareness, laying the groundwork for a new class of intelligent self-tracking applications.
Towards Autonomous Sustainability Assessment via Multimodal AI Agents
Jul 22, 2025



Interest in sustainability information has surged in recent years. However, the data required for a life cycle assessment (LCA) that maps the materials and processes from product manufacturing to disposal into environmental impacts (EI) are often unavailable. Here we reimagine conventional LCA by introducing multimodal AI agents that emulate interactions between LCA experts and stakeholders like product managers and engineers to calculate the cradle-to-gate (production) carbon emissions of electronic devices. The AI agents iteratively generate a detailed life-cycle inventory leveraging a custom data abstraction and software tools that extract information from online text and images from repair communities and government certifications. This approach reduces weeks or months of expert time to under one minute and closes data availability gaps while yielding carbon footprint estimates within 19% of expert LCAs with zero proprietary data. Additionally, we develop a method to directly estimate EI by comparing an input to a cluster of products with similar descriptions and known carbon footprints. This runs in 3 ms on a laptop with a MAPE of 12.28% on electronic products. Further, we develop a data-driven method to generate emission factors. We use the properties of an unknown material to represent it as a weighted sum of emission factors for similar materials. Compared to human experts picking the closest LCA database entry, this improves MAPE by 120.26%. We analyze the data and compute scaling of this approach and discuss its implications for future LCA workflows.
Bishop: Sparsified Bundling Spiking Transformers on Heterogeneous Cores with Error-Constrained Pruning
May 18, 2025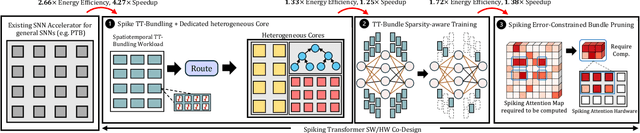
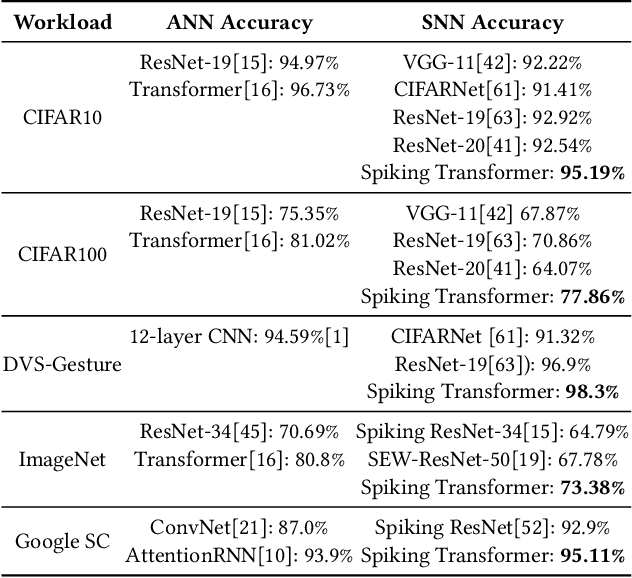
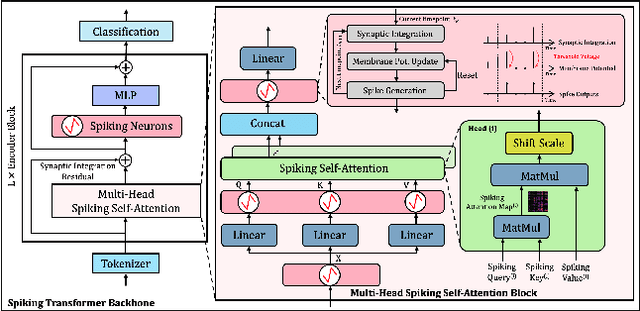
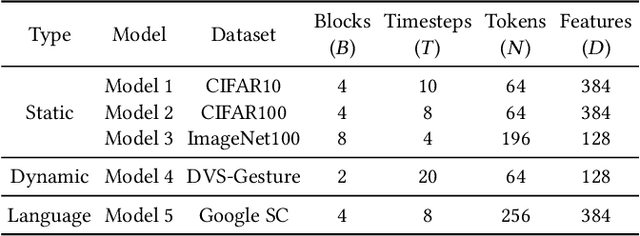
We present Bishop, the first dedicated hardware accelerator architecture and HW/SW co-design framework for spiking transformers that optimally represents, manages, and processes spike-based workloads while exploring spatiotemporal sparsity and data reuse. Specifically, we introduce the concept of Token-Time Bundle (TTB), a container that bundles spiking data of a set of tokens over multiple time points. Our heterogeneous accelerator architecture Bishop concurrently processes workload packed in TTBs and explores intra- and inter-bundle multiple-bit weight reuse to significantly reduce memory access. Bishop utilizes a stratifier, a dense core array, and a sparse core array to process MLP blocks and projection layers. The stratifier routes high-density spiking activation workload to the dense core and low-density counterpart to the sparse core, ensuring optimized processing tailored to the given spatiotemporal sparsity level. To further reduce data access and computation, we introduce a novel Bundle Sparsity-Aware (BSA) training pipeline that enhances not only the overall but also structured TTB-level firing sparsity. Moreover, the processing efficiency of self-attention layers is boosted by the proposed Error-Constrained TTB Pruning (ECP), which trims activities in spiking queries, keys, and values both before and after the computation of spiking attention maps with a well-defined error bound. Finally, we design a reconfigurable TTB spiking attention core to efficiently compute spiking attention maps by executing highly simplified "AND" and "Accumulate" operations. On average, Bishop achieves a 5.91x speedup and 6.11x improvement in energy efficiency over previous SNN accelerators, while delivering higher accuracy across multiple datasets.
Set Phasers to Stun: Beaming Power and Control to Mobile Robots with Laser Light
Apr 24, 2025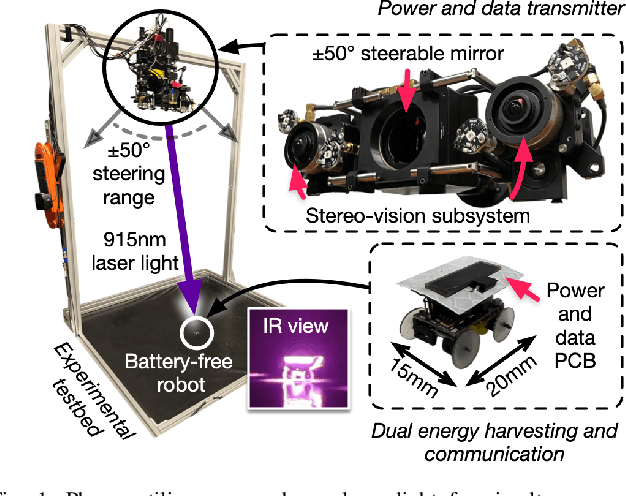
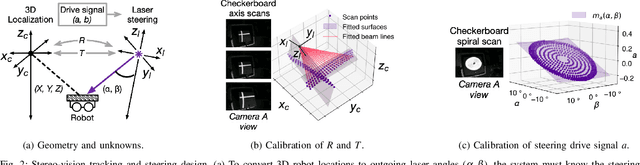
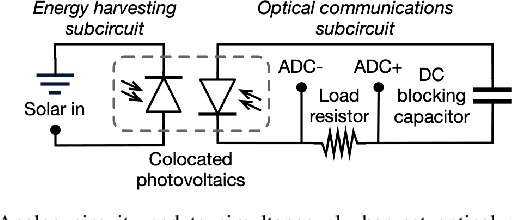
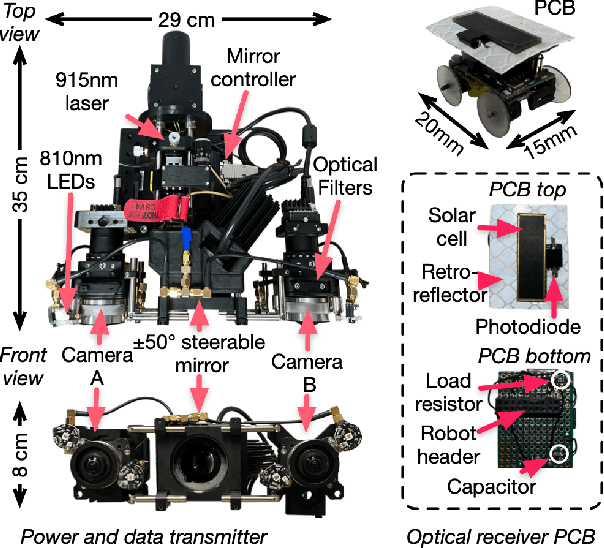
We present Phaser, a flexible system that directs narrow-beam laser light to moving robots for concurrent wireless power delivery and communication. We design a semi-automatic calibration procedure to enable fusion of stereo-vision-based 3D robot tracking with high-power beam steering, and a low-power optical communication scheme that reuses the laser light as a data channel. We fabricate a Phaser prototype using off-the-shelf hardware and evaluate its performance with battery-free autonomous robots. Phaser delivers optical power densities of over 110 mW/cm$^2$ and error-free data to mobile robots at multi-meter ranges, with on-board decoding drawing 0.3 mA (97\% less current than Bluetooth Low Energy). We demonstrate Phaser fully powering gram-scale battery-free robots to nearly 2x higher speeds than prior work while simultaneously controlling them to navigate around obstacles and along paths. Code, an open-source design guide, and a demonstration video of Phaser is available at https://mobilex.cs.columbia.edu/phaser.
TerraTrace: Temporal Signature Land Use Mapping System
Feb 25, 2025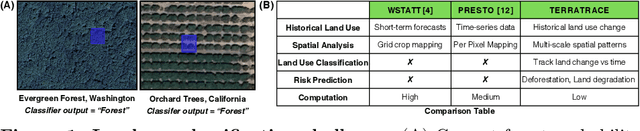
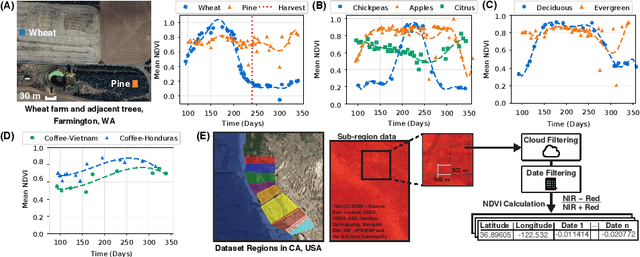
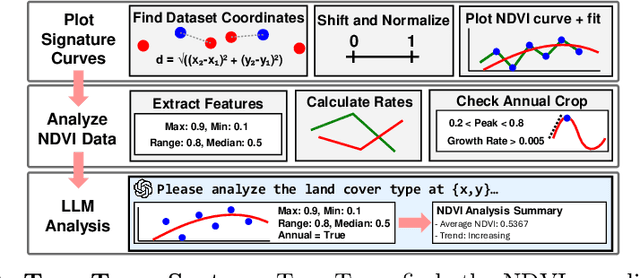

Understanding land use over time is critical to tracking events related to climate change, like deforestation. However, satellite-based remote sensing tools which are used for monitoring struggle to differentiate vegetation types in farms and orchards from forests. We observe that metrics such as the Normalized Difference Vegetation Index (NDVI), based on plant photosynthesis, have unique temporal signatures that reflect agricultural practices and seasonal cycles. We analyze yearly NDVI changes on 20 farms for 10 unique crops. Initial results show that NDVI curves are coherent with agricultural practices, are unique to each crop, consistent globally, and can differentiate farms from forests. We develop a novel longitudinal NDVI dataset for the state of California from 2020-2023 with 500~m resolution and over 70 million points. We use this to develop the TerraTrace platform, an end-to-end analytic tool that classifies land use using NDVI signatures and allows users to query the system through an LLM chatbot and graphical interface.
WeatherQA: Can Multimodal Language Models Reason about Severe Weather?
Jun 17, 2024



Severe convective weather events, such as hail, tornadoes, and thunderstorms, often occur quickly yet cause significant damage, costing billions of dollars every year. This highlights the importance of forecasting severe weather threats hours in advance to better prepare meteorologists and residents in at-risk areas. Can modern large foundation models perform such forecasting? Existing weather benchmarks typically focus only on predicting time-series changes in certain weather parameters (e.g., temperature, moisture) with text-only features. In this work, we introduce WeatherQA, the first multimodal dataset designed for machines to reason about complex combinations of weather parameters (a.k.a., ingredients) and predict severe weather in real-world scenarios. The dataset includes over 8,000 (multi-images, text) pairs for diverse severe weather events. Each pair contains rich information crucial for forecasting -- the images describe the ingredients capturing environmental instability, surface observations, and radar reflectivity, and the text contains forecast analyses written by human experts. With WeatherQA, we evaluate state-of-the-art vision language models , including GPT4, Claude3, Gemini-1.5, and a fine-tuned Llama3-based VLM, by designing two challenging tasks: (1) multi-choice QA for predicting affected area and (2) classification of the development potential of severe convection. These tasks require deep understanding of domain knowledge (e.g., atmospheric dynamics) and complex reasoning over multimodal data (e.g., interactions between weather parameters). We show a substantial gap between the strongest VLM, GPT4o, and human reasoning. Our comprehensive case study with meteorologists further reveals the weaknesses of the models, suggesting that better training and data integration are necessary to bridge this gap. WeatherQA link: https://github.com/chengqianma/WeatherQA.
LabelAId: Just-in-time AI Interventions for Improving Human Labeling Quality and Domain Knowledge in Crowdsourcing Systems
Mar 14, 2024



Crowdsourcing platforms have transformed distributed problem-solving, yet quality control remains a persistent challenge. Traditional quality control measures, such as prescreening workers and refining instructions, often focus solely on optimizing economic output. This paper explores just-in-time AI interventions to enhance both labeling quality and domain-specific knowledge among crowdworkers. We introduce LabelAId, an advanced inference model combining Programmatic Weak Supervision (PWS) with FT-Transformers to infer label correctness based on user behavior and domain knowledge. Our technical evaluation shows that our LabelAId pipeline consistently outperforms state-of-the-art ML baselines, improving mistake inference accuracy by 36.7% with 50 downstream samples. We then implemented LabelAId into Project Sidewalk, an open-source crowdsourcing platform for urban accessibility. A between-subjects study with 34 participants demonstrates that LabelAId significantly enhances label precision without compromising efficiency while also increasing labeler confidence. We discuss LabelAId's success factors, limitations, and its generalizability to other crowdsourced science domains.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.
Solar-powered shape-changing origami microfliers
Sep 13, 2023Using wind to disperse microfliers that fall like seeds and leaves can help automate large-scale sensor deployments. Here, we present battery-free microfliers that can change shape in mid-air to vary their dispersal distance. We design origami microfliers using bi-stable leaf-out structures and uncover an important property: a simple change in the shape of these origami structures causes two dramatically different falling behaviors. When unfolded and flat, the microfliers exhibit a tumbling behavior that increases lateral displacement in the wind. When folded inward, their orientation is stabilized, resulting in a downward descent that is less influenced by wind. To electronically transition between these two shapes, we designed a low-power electromagnetic actuator that produces peak forces of up to 200 millinewtons within 25 milliseconds while powered by solar cells. We fabricated a circuit directly on the folded origami structure that includes a programmable microcontroller, Bluetooth radio, solar power harvesting circuit, a pressure sensor to estimate altitude and a temperature sensor. Outdoor evaluations show that our 414 milligram origami microfliers are able to electronically change their shape mid-air, travel up to 98 meters in a light breeze, and wirelessly transmit data via Bluetooth up to 60 meters away, using only power collected from the sun.