 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Arena: Iterative Optimization via Hardware Feedback
Jun 15, 2026Embedded devices from wildlife monitoring stations to clinical wearables require local AI inference due to latency, communication, or privacy constraints. Optimizing models for heterogeneous microcontrollers (MCUs) requires simultaneously satisfying hard physical constraints on memory, power, and temperature while preserving accuracy, a multidimensional optimization that is today performed manually by experts. We ask whether an LLM agent can autonomously navigate this complex, multi-turn pipeline guided by real hardware feedback, and introduce a hardware-in-the-loop agent arena in which the agent iteratively refines both model and firmware -- compiling, flashing, and measuring on real hardware -- to enable closed-loop optimization. Frontier models, including Claude Opus 4.7 and Gemini 3.1 Pro, fail entirely without hardware feedback (0% deployment success), whereas our hardware-in-the-loop formulation achieves the first successful deployment within three iterations and can surpass human expert results within seven. This agentic co-optimization achieves 250x compression for vision models with <3.3% accuracy loss and 400x for audio with <6% Feature Error Rate loss, enabling battery-free operation on a commercial MCU via solar harvesting. We demonstrate practical impact in two real-world systems: an elk-detection camera trap (96.7% accuracy) and a phonetic-transcription wearable (8.44% FER) for child development research.
Set Phasers to Stun: Beaming Power and Control to Mobile Robots with Laser Light
Apr 24, 2025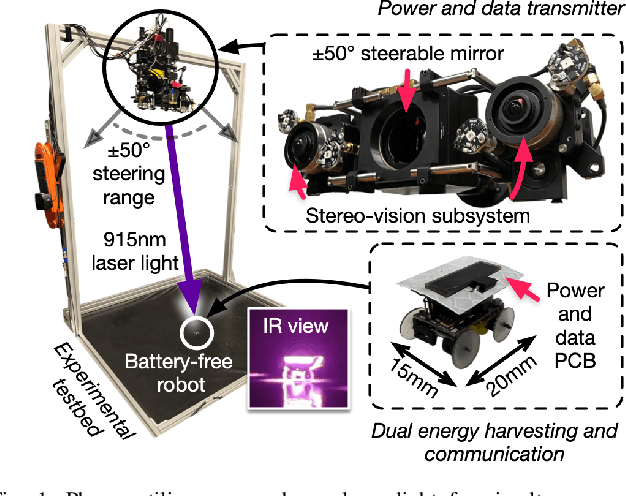
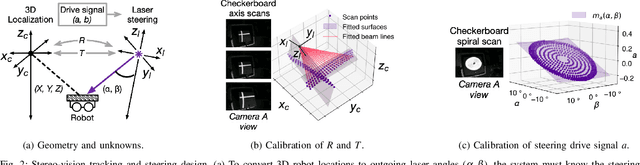
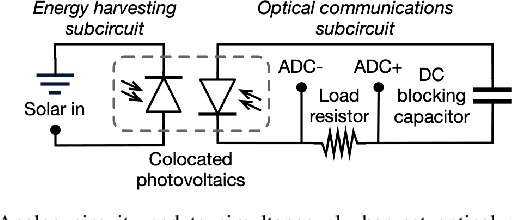
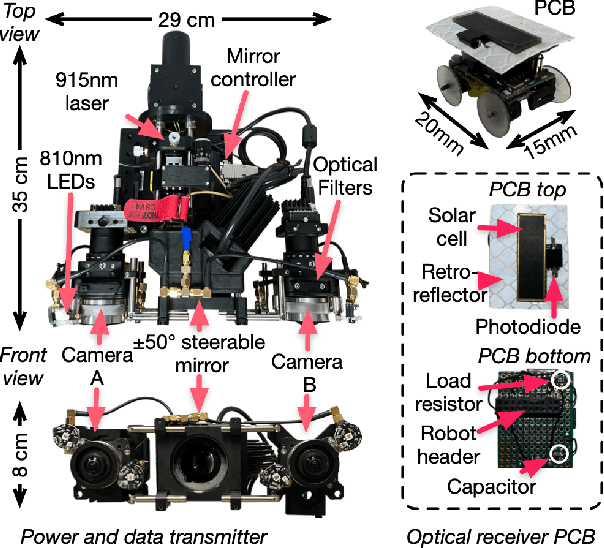
We present Phaser, a flexible system that directs narrow-beam laser light to moving robots for concurrent wireless power delivery and communication. We design a semi-automatic calibration procedure to enable fusion of stereo-vision-based 3D robot tracking with high-power beam steering, and a low-power optical communication scheme that reuses the laser light as a data channel. We fabricate a Phaser prototype using off-the-shelf hardware and evaluate its performance with battery-free autonomous robots. Phaser delivers optical power densities of over 110 mW/cm$^2$ and error-free data to mobile robots at multi-meter ranges, with on-board decoding drawing 0.3 mA (97\% less current than Bluetooth Low Energy). We demonstrate Phaser fully powering gram-scale battery-free robots to nearly 2x higher speeds than prior work while simultaneously controlling them to navigate around obstacles and along paths. Code, an open-source design guide, and a demonstration video of Phaser is available at https://mobilex.cs.columbia.edu/phaser.
EVE: Enabling Anyone to Train Robot using Augmented Reality
Apr 09, 2024



The increasing affordability of robot hardware is accelerating the integration of robots into everyday activities. However, training a robot to automate a task typically requires physical robots and expensive demonstration data from trained human annotators. Consequently, only those with access to physical robots produce demonstrations to train robots. To mitigate this issue, we introduce EVE, an iOS app that enables everyday users to train robots using intuitive augmented reality visualizations without needing a physical robot. With EVE, users can collect demonstrations by specifying waypoints with their hands, visually inspecting the environment for obstacles, modifying existing waypoints, and verifying collected trajectories. In a user study ($N=14$, $D=30$) consisting of three common tabletop tasks, EVE outperformed three state-of-the-art interfaces in success rate and was comparable to kinesthetic teaching-physically moving a real robot-in completion time, usability, motion intent communication, enjoyment, and preference ($mean_{p}=0.30$). We conclude by enumerating limitations and design considerations for future AR-based demonstration collection systems for robotics.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.