 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvFill: Model Collaboration for Responsive Conversational Voice Agents
Nov 10, 2025Deploying conversational voice agents with large language models faces a critical challenge: cloud-based foundation models provide deep reasoning and domain knowledge but introduce latency that disrupts natural conversation, while on-device models respond immediately but lack sophistication. We propose conversational infill, a task where a lightweight on-device model generates contextually appropriate dialogue while seamlessly incorporating streaming knowledge from a powerful backend model. This approach decouples response latency from model capability, enabling systems that feel responsive while accessing the full power of large-scale models. We present ConvFill, a 360M parameter model trained on synthetic multi-domain conversations. Evaluation across multiple backend models shows that conversational infill can be successfully learned, with ConvFill achieving accuracy improvements of 36-42% over standalone small models of the same size while consistently retaining sub-200ms response latencies. Our results demonstrate the promise of this approach for building on-device conversational agents that are both immediately responsive and knowledgeable.
SnappyMeal: Design and Longitudinal Evaluation of a Multimodal AI Food Logging Application
Nov 05, 2025Food logging, both self-directed and prescribed, plays a critical role in uncovering correlations between diet, medical, fitness, and health outcomes. Through conversations with nutritional experts and individuals who practice dietary tracking, we find current logging methods, such as handwritten and app-based journaling, are inflexible and result in low adherence and potentially inaccurate nutritional summaries. These findings, corroborated by prior literature, emphasize the urgent need for improved food logging methods. In response, we propose SnappyMeal, an AI-powered dietary tracking system that leverages multimodal inputs to enable users to more flexibly log their food intake. SnappyMeal introduces goal-dependent follow-up questions to intelligently seek missing context from the user and information retrieval from user grocery receipts and nutritional databases to improve accuracy. We evaluate SnappyMeal through publicly available nutrition benchmarks and a multi-user, 3-week, in-the-wild deployment capturing over 500 logged food instances. Users strongly praised the multiple available input methods and reported a strong perceived accuracy. These insights suggest that multimodal AI systems can be leveraged to significantly improve dietary tracking flexibility and context-awareness, laying the groundwork for a new class of intelligent self-tracking applications.
Towards Autonomous Sustainability Assessment via Multimodal AI Agents
Jul 22, 2025



Interest in sustainability information has surged in recent years. However, the data required for a life cycle assessment (LCA) that maps the materials and processes from product manufacturing to disposal into environmental impacts (EI) are often unavailable. Here we reimagine conventional LCA by introducing multimodal AI agents that emulate interactions between LCA experts and stakeholders like product managers and engineers to calculate the cradle-to-gate (production) carbon emissions of electronic devices. The AI agents iteratively generate a detailed life-cycle inventory leveraging a custom data abstraction and software tools that extract information from online text and images from repair communities and government certifications. This approach reduces weeks or months of expert time to under one minute and closes data availability gaps while yielding carbon footprint estimates within 19% of expert LCAs with zero proprietary data. Additionally, we develop a method to directly estimate EI by comparing an input to a cluster of products with similar descriptions and known carbon footprints. This runs in 3 ms on a laptop with a MAPE of 12.28% on electronic products. Further, we develop a data-driven method to generate emission factors. We use the properties of an unknown material to represent it as a weighted sum of emission factors for similar materials. Compared to human experts picking the closest LCA database entry, this improves MAPE by 120.26%. We analyze the data and compute scaling of this approach and discuss its implications for future LCA workflows.
Set Phasers to Stun: Beaming Power and Control to Mobile Robots with Laser Light
Apr 24, 2025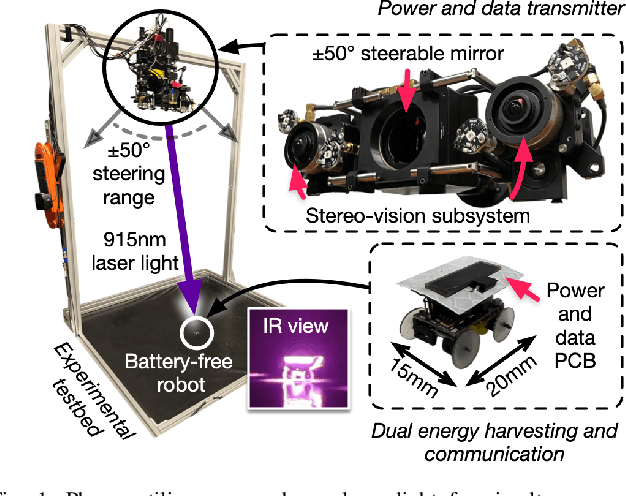
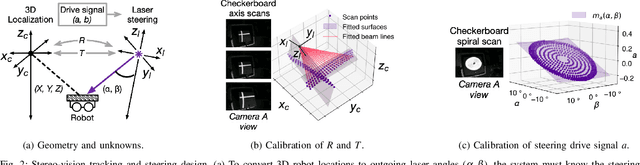
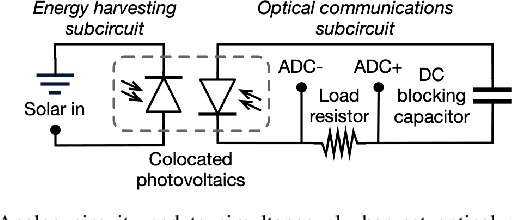
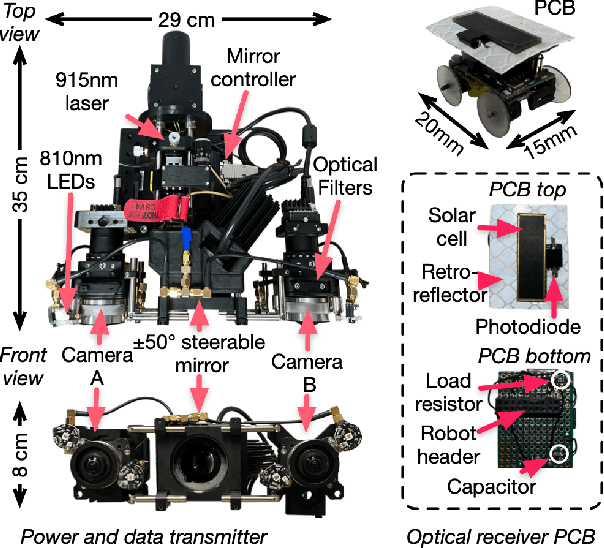
We present Phaser, a flexible system that directs narrow-beam laser light to moving robots for concurrent wireless power delivery and communication. We design a semi-automatic calibration procedure to enable fusion of stereo-vision-based 3D robot tracking with high-power beam steering, and a low-power optical communication scheme that reuses the laser light as a data channel. We fabricate a Phaser prototype using off-the-shelf hardware and evaluate its performance with battery-free autonomous robots. Phaser delivers optical power densities of over 110 mW/cm$^2$ and error-free data to mobile robots at multi-meter ranges, with on-board decoding drawing 0.3 mA (97\% less current than Bluetooth Low Energy). We demonstrate Phaser fully powering gram-scale battery-free robots to nearly 2x higher speeds than prior work while simultaneously controlling them to navigate around obstacles and along paths. Code, an open-source design guide, and a demonstration video of Phaser is available at https://mobilex.cs.columbia.edu/phaser.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.
Exploring and Characterizing Large Language Models For Embedded System Development and Debugging
Jul 07, 2023Large language models (LLMs) have shown remarkable abilities to generate code, however their ability to develop software for embedded systems, which requires cross-domain knowledge of hardware and software has not been studied. In this paper we systematically evaluate leading LLMs (GPT-3.5, GPT-4, PaLM 2) to assess their performance for embedded system development, study how human programmers interact with these tools, and develop an AI-based software engineering workflow for building embedded systems. We develop an an end-to-end hardware-in-the-loop evaluation platform for verifying LLM generated programs using sensor actuator pairs. We compare all three models with N=450 experiments and find surprisingly that GPT-4 especially shows an exceptional level of cross-domain understanding and reasoning, in some cases generating fully correct programs from a single prompt. In N=50 trials, GPT-4 produces functional I2C interfaces 66% of the time. GPT-4 also produces register-level drivers, code for LoRa communication, and context-specific power optimizations for an nRF52 program resulting in over 740x current reduction to 12.2 uA. We also characterize the models' limitations to develop a generalizable workflow for using LLMs in embedded system development. We evaluate the workflow with 15 users including novice and expert programmers. We find that our workflow improves productivity for all users and increases the success rate for building a LoRa environmental sensor from 25% to 100%, including for users with zero hardware or C/C++ experience.