 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mode Elicitation: Diversity-Preserving Reinforcement Learning via Latent Diffusion Reasoner
Feb 02, 2026Recent reinforcement learning (RL) methods improve LLM reasoning by optimizing discrete Chain-of-Thought (CoT) generation; however, exploration in token space often suffers from diversity collapse as policy entropy decreases due to mode elicitation behavior in discrete RL. To mitigate this issue, we propose Latent Diffusion Reasoning with Reinforcement Learning (LaDi-RL), a framework that conducts exploration directly in a continuous latent space, where latent variables encode semantic-level reasoning trajectories. By modeling exploration via guided diffusion, multi-step denoising distributes stochasticity and preserves multiple coexisting solution modes without mutual suppression. Furthermore, by decoupling latent-space exploration from text-space generation, we show that latent diffusion-based optimization is more effective than text-space policy optimization alone, while a complementary text policy provides additional gains when combined with latent exploration. Experiments on code generation and mathematical reasoning benchmarks demonstrate consistent improvements in both pass@1 and pass@k over discrete RL baselines, with absolute pass@1 gains of +9.4% on code generation and +5.7% on mathematical reasoning, highlighting diffusion-based latent RL as a principled alternative to discrete token-level RL for reasoning.
COLT: Lightweight Multi-LLM Collaboration through Shared MCTS Reasoning for Model Compilation
Feb 02, 2026Model serving costs dominate AI systems, making compiler optimization essential for scalable deployment. Recent works show that a large language model (LLM) can guide compiler search by reasoning over program structure and optimization history. However, using a single large model throughout the search is expensive, while smaller models are less reliable when used alone. Thus, this paper seeks to answer whether multi-LLM collaborative reasoning relying primarily on small LLMs can match or exceed the performance of a single large model. As such, we propose a lightweight collaborative multi-LLM framework, dubbed COLT, for compiler optimization that enables coordinated reasoning across multiple models within a single Monte Carlo tree search (MCTS) process. A key contribution is the use of a single shared MCTS tree as the collaboration substrate across LLMs, enabling the reuse of transformation prefixes and cross-model value propagation. Hence, we circumvent both heavy internal reasoning mechanisms and conventional agentic machinery that relies on external planners, multiple concurrent LLMs, databases, external memory/versioning of intermediate results, and controllers by simply endogenizing model selection within the lightweight MCTS optimization loop. Every iteration, the acting LLM proposes a joint action: (compiler transformation, model to be queried next). We also introduce a model-aware tree policy that biases search toward smaller models while preserving exploration, and a course-alteration mechanism that escalates to the largest model when the search exhibits persistent regressions attributable to smaller models.
TSRBench: A Comprehensive Multi-task Multi-modal Time Series Reasoning Benchmark for Generalist Models
Jan 26, 2026Time series data is ubiquitous in real-world scenarios and crucial for critical applications ranging from energy management to traffic control. Consequently, the ability to reason over time series is a fundamental skill for generalist models to solve practical problems. However, this dimension is notably absent from existing benchmarks of generalist models. To bridge this gap, we introduce TSRBench, a comprehensive multi-modal benchmark designed to stress-test the full spectrum of time series reasoning capabilities. TSRBench features: i) a diverse set of 4125 problems from 14 domains, and is categorized into 4 major dimensions: Perception, Reasoning, Prediction, and Decision-Making. ii) 15 tasks from the 4 dimensions evaluating essential reasoning capabilities (e.g., numerical reasoning). Through extensive experiments, we evaluated over 30 leading proprietary and open-source LLMs, VLMs, and TSLLMs within TSRBench. Our findings reveal that: i) scaling laws hold for perception and reasoning but break down for prediction; ii) strong reasoning does not guarantee accurate context-aware forecasting, indicating a decoupling between semantic understanding and numerical prediction; and iii) despite the complementary nature of textual and visual represenations of time series as inputs, current multimodal models fail to effectively fuse them for reciprocal performance gains. TSRBench provides a standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance generalist models. Our code and dataset are available at https://tsrbench.github.io/.
PrivacyReasoner: Can LLM Emulate a Human-like Privacy Mind?
Jan 14, 2026This paper introduces PRA, an AI-agent design for simulating how individual users form privacy concerns in response to real-world news. Moving beyond population-level sentiment analysis, PRA integrates privacy and cognitive theories to simulate user-specific privacy reasoning grounded in personal comment histories and contextual cues. The agent reconstructs each user's "privacy mind", dynamically activates relevant privacy memory through a contextual filter that emulates bounded rationality, and generates synthetic comments reflecting how that user would likely respond to new privacy scenarios. A complementary LLM-as-a-Judge evaluator, calibrated against an established privacy concern taxonomy, quantifies the faithfulness of generated reasoning. Experiments on real-world Hacker News discussions show that \PRA outperforms baseline agents in privacy concern prediction and captures transferable reasoning patterns across domains including AI, e-commerce, and healthcare.
ToolGym: an Open-world Tool-using Environment for Scalable Agent Testing and Data Curation
Jan 09, 2026Tool-using LLM agents still struggle in open-world settings with large tool pools, long-horizon objectives, wild constraints, and unreliable tool states. For scalable and realistic training and testing, we introduce an open-world tool-using environment, built on 5,571 format unified tools across 204 commonly used apps. It includes a task creation engine that synthesizes long-horizon, multi-tool workflows with wild constraints, and a state controller that injects interruptions and failures to stress-test robustness. On top of this environment, we develop a tool select-then-execute agent framework with a planner-actor decomposition to separate deliberate reasoning and self-correction from step-wise execution. Comprehensive evaluation of state-of-the-art LLMs reveals the misalignment between tool planning and execution abilities, the constraint following weakness of existing LLMs, and DeepSeek-v3.2's strongest robustness. Finally, we collect 1,170 trajectories from our environment to fine-tune LLMs, achieving superior performance to baselines using 119k samples, indicating the environment's value as both a realistic benchmark and a data engine for tool-using agents. Our code and data will be publicly released.
DeliveryBench: Can Agents Earn Profit in Real World?
Dec 22, 2025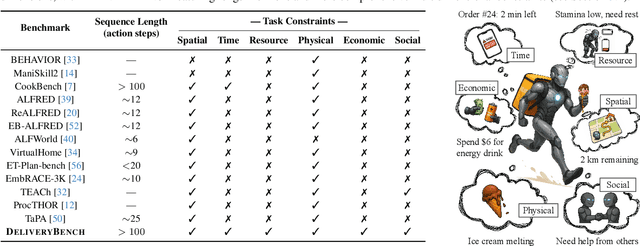
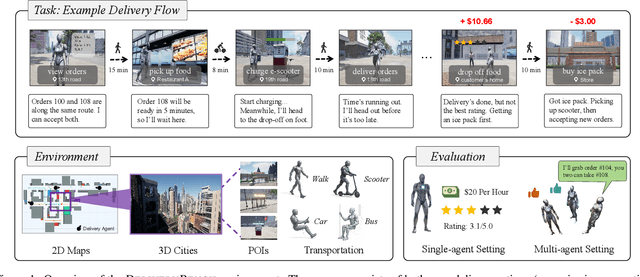
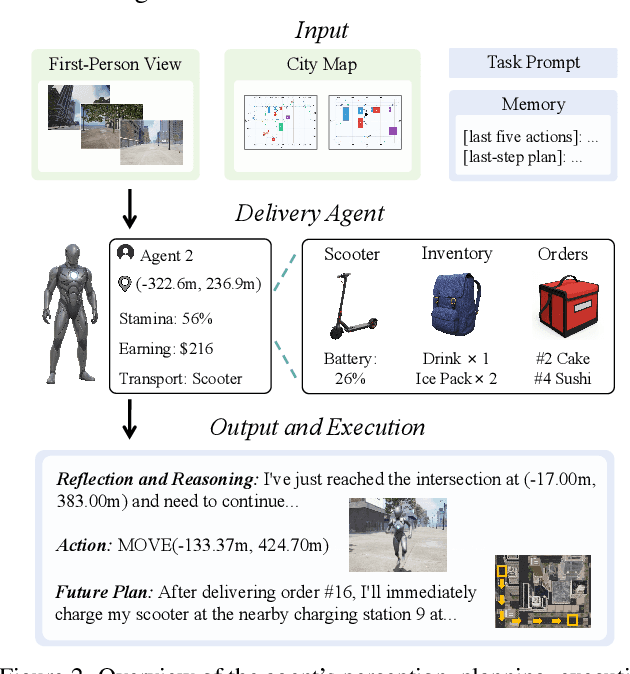
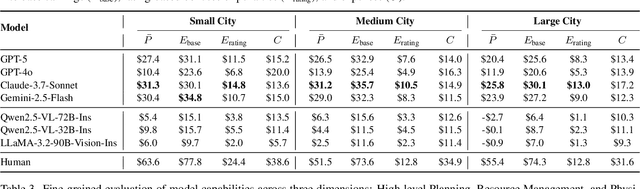
LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadline, transportation expense, vehicle battery, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning. We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments. Our code, data, and benchmark are available at https://deliverybench.github.io.
SimWorld-Robotics: Synthesizing Photorealistic and Dynamic Urban Environments for Multimodal Robot Navigation and Collaboration
Dec 10, 2025Recent advances in foundation models have shown promising results in developing generalist robotics that can perform diverse tasks in open-ended scenarios given multimodal inputs. However, current work has been mainly focused on indoor, household scenarios. In this work, we present SimWorld-Robotics~(SWR), a simulation platform for embodied AI in large-scale, photorealistic urban environments. Built on Unreal Engine 5, SWR procedurally generates unlimited photorealistic urban scenes populated with dynamic elements such as pedestrians and traffic systems, surpassing prior urban simulations in realism, complexity, and scalability. It also supports multi-robot control and communication. With these key features, we build two challenging robot benchmarks: (1) a multimodal instruction-following task, where a robot must follow vision-language navigation instructions to reach a destination in the presence of pedestrians and traffic; and (2) a multi-agent search task, where two robots must communicate to cooperatively locate and meet each other. Unlike existing benchmarks, these two new benchmarks comprehensively evaluate a wide range of critical robot capacities in realistic scenarios, including (1) multimodal instructions grounding, (2) 3D spatial reasoning in large environments, (3) safe, long-range navigation with people and traffic, (4) multi-robot collaboration, and (5) grounded communication. Our experimental results demonstrate that state-of-the-art models, including vision-language models (VLMs), struggle with our tasks, lacking robust perception, reasoning, and planning abilities necessary for urban environments.
Multi-agent Self-triage System with Medical Flowcharts
Nov 16, 2025Online health resources and large language models (LLMs) are increasingly used as a first point of contact for medical decision-making, yet their reliability in healthcare remains limited by low accuracy, lack of transparency, and susceptibility to unverified information. We introduce a proof-of-concept conversational self-triage system that guides LLMs with 100 clinically validated flowcharts from the American Medical Association, providing a structured and auditable framework for patient decision support. The system leverages a multi-agent framework consisting of a retrieval agent, a decision agent, and a chat agent to identify the most relevant flowchart, interpret patient responses, and deliver personalized, patient-friendly recommendations, respectively. Performance was evaluated at scale using synthetic datasets of simulated conversations. The system achieved 95.29% top-3 accuracy in flowchart retrieval (N=2,000) and 99.10% accuracy in flowchart navigation across varied conversational styles and conditions (N=37,200). By combining the flexibility of free-text interaction with the rigor of standardized clinical protocols, this approach demonstrates the feasibility of transparent, accurate, and generalizable AI-assisted self-triage, with potential to support informed patient decision-making while improving healthcare resource utilization.
Small Drafts, Big Verdict: Information-Intensive Visual Reasoning via Speculation
Oct 23, 2025Large Vision-Language Models (VLMs) have achieved remarkable progress in multimodal understanding, yet they struggle when reasoning over information-intensive images that densely interleave textual annotations with fine-grained graphical elements. The main challenges lie in precisely localizing critical cues in dense layouts and multi-hop reasoning to integrate dispersed evidence. We propose Speculative Verdict (SV), a training-free framework inspired by speculative decoding that combines multiple lightweight draft experts with a large verdict model. In the draft stage, small VLMs act as draft experts to generate reasoning paths that provide diverse localization candidates; in the verdict stage, a strong VLM synthesizes these paths to produce the final answer, minimizing computational cost while recovering correct answers. To further improve efficiency and accuracy, SV introduces a consensus expert selection mechanism that forwards only high-agreement reasoning paths to the verdict. Empirically, SV achieves consistent gains on challenging information-intensive and high-resolution visual question answering benchmarks, including InfographicVQA, ChartMuseum, ChartQAPro, and HR-Bench 4K. By synthesizing correct insights from multiple partially accurate reasoning paths, SV achieves both error correction and cost-efficiency compared to large proprietary models or training pipelines. Code is available at https://github.com/Tinaliu0123/speculative-verdict
LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
Oct 06, 2025



Large Language Models (LLMs) demonstrate their reasoning ability through chain-of-thought (CoT) generation. However, LLM's autoregressive decoding may limit the ability to revisit and refine earlier tokens in a holistic manner, which can also lead to inefficient exploration for diverse solutions. In this paper, we propose LaDiR (Latent Diffusion Reasoner), a novel reasoning framework that unifies the expressiveness of continuous latent representation with the iterative refinement capabilities of latent diffusion models for an existing LLM. We first construct a structured latent reasoning space using a Variational Autoencoder (VAE) that encodes text reasoning steps into blocks of thought tokens, preserving semantic information and interpretability while offering compact but expressive representations. Subsequently, we utilize a latent diffusion model that learns to denoise a block of latent thought tokens with a blockwise bidirectional attention mask, enabling longer horizon and iterative refinement with adaptive test-time compute. This design allows efficient parallel generation of diverse reasoning trajectories, allowing the model to plan and revise the reasoning process holistically. We conduct evaluations on a suite of mathematical reasoning and planning benchmarks. Empirical results show that LaDiR consistently improves accuracy, diversity, and interpretability over existing autoregressive, diffusion-based, and latent reasoning methods, revealing a new paradigm for text reasoning with latent diffusion.