 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Assist Video Content Analysis: An Exploratory Study of Short Videos on Depression
Jun 27, 2024


Despite the growing interest in leveraging Large Language Models (LLMs) for content analysis, current studies have primarily focused on text-based content. In the present work, we explored the potential of LLMs in assisting video content analysis by conducting a case study that followed a new workflow of LLM-assisted multimodal content analysis. The workflow encompasses codebook design, prompt engineering, LLM processing, and human evaluation. We strategically crafted annotation prompts to get LLM Annotations in structured form and explanation prompts to generate LLM Explanations for a better understanding of LLM reasoning and transparency. To test LLM's video annotation capabilities, we analyzed 203 keyframes extracted from 25 YouTube short videos about depression. We compared the LLM Annotations with those of two human coders and found that LLM has higher accuracy in object and activity Annotations than emotion and genre Annotations. Moreover, we identified the potential and limitations of LLM's capabilities in annotating videos. Based on the findings, we explore opportunities and challenges for future research and improvements to the workflow. We also discuss ethical concerns surrounding future studies based on LLM-assisted video analysis.
Time2Stop: Adaptive and Explainable Human-AI Loop for Smartphone Overuse Intervention
Mar 03, 2024

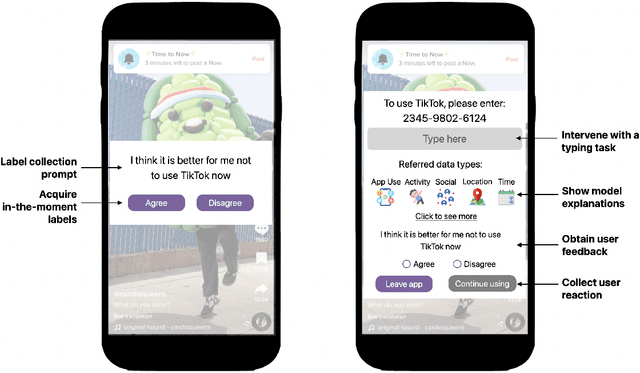

Despite a rich history of investigating smartphone overuse intervention techniques, AI-based just-in-time adaptive intervention (JITAI) methods for overuse reduction are lacking. We develop Time2Stop, an intelligent, adaptive, and explainable JITAI system that leverages machine learning to identify optimal intervention timings, introduces interventions with transparent AI explanations, and collects user feedback to establish a human-AI loop and adapt the intervention model over time. We conducted an 8-week field experiment (N=71) to evaluate the effectiveness of both the adaptation and explanation aspects of Time2Stop. Our results indicate that our adaptive models significantly outperform the baseline methods on intervention accuracy (>32.8\% relatively) and receptivity (>8.0\%). In addition, incorporating explanations further enhances the effectiveness by 53.8\% and 11.4\% on accuracy and receptivity, respectively. Moreover, Time2Stop significantly reduces overuse, decreasing app visit frequency by 7.0$\sim$8.9\%. Our subjective data also echoed these quantitative measures. Participants preferred the adaptive interventions and rated the system highly on intervention time accuracy, effectiveness, and level of trust. We envision our work can inspire future research on JITAI systems with a human-AI loop to evolve with users.
Towards Open-World Gesture Recognition
Jan 20, 2024



Static machine learning methods in gesture recognition assume that training and test data come from the same underlying distribution. However, in real-world applications involving gesture recognition on wrist-worn devices, data distribution may change over time. We formulate this problem of adapting recognition models to new tasks, where new data patterns emerge, as open-world gesture recognition (OWGR). We propose leveraging continual learning to make machine learning models adaptive to new tasks without degrading performance on previously learned tasks. However, the exploration of parameters for questions around when and how to train and deploy recognition models requires time-consuming user studies and is sometimes impractical. To address this challenge, we propose a design engineering approach that enables offline analysis on a collected large-scale dataset with various parameters and compares different continual learning methods. Finally, design guidelines are provided to enhance the development of an open-world wrist-worn gesture recognition process.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.