 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Speech Synthesis with Context-Aware Memory
Aug 20, 2025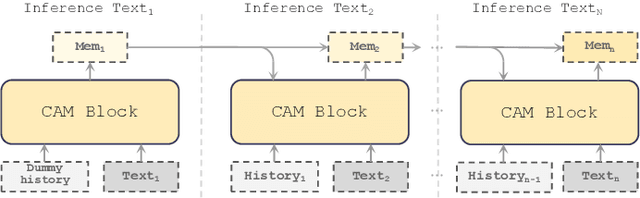
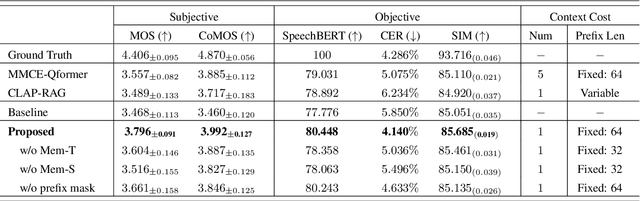
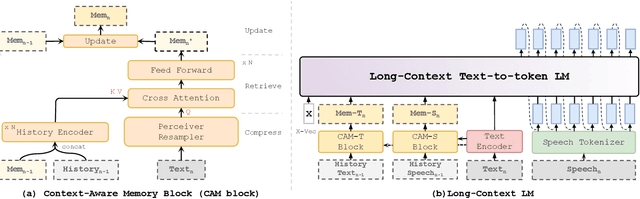
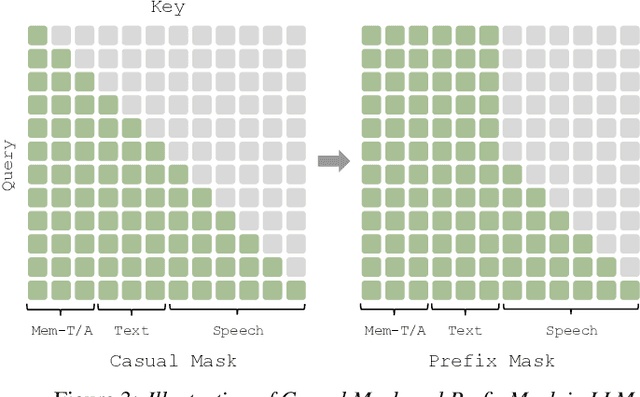
In long-text speech synthesis, current approaches typically convert text to speech at the sentence-level and concatenate the results to form pseudo-paragraph-level speech. These methods overlook the contextual coherence of paragraphs, leading to reduced naturalness and inconsistencies in style and timbre across the long-form speech. To address these issues, we propose a Context-Aware Memory (CAM)-based long-context Text-to-Speech (TTS) model. The CAM block integrates and retrieves both long-term memory and local context details, enabling dynamic memory updates and transfers within long paragraphs to guide sentence-level speech synthesis. Furthermore, the prefix mask enhances the in-context learning ability by enabling bidirectional attention on prefix tokens while maintaining unidirectional generation. Experimental results demonstrate that the proposed method outperforms baseline and state-of-the-art long-context methods in terms of prosody expressiveness, coherence and context inference cost across paragraph-level speech.
Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Aug 06, 2025Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model's output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
Control System Design and Experiments for Autonomous Underwater Helicopter Docking Procedure Based on Acoustic-inertial-optical Guidance
Oct 09, 2024
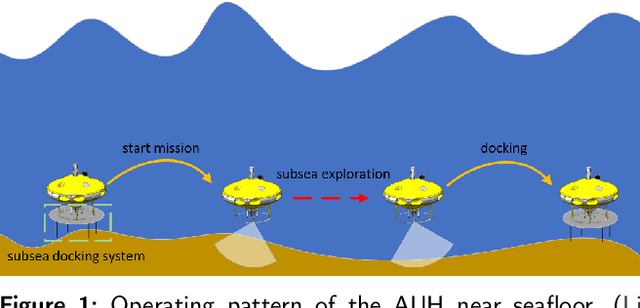
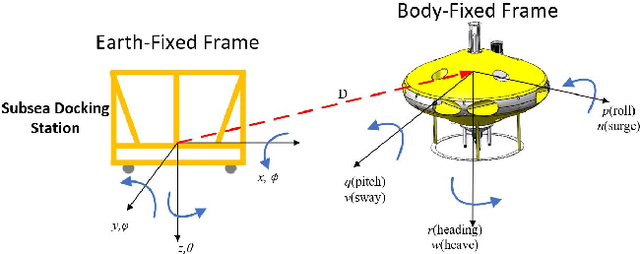

A control system structure for the underwater docking procedure of an Autonomous Underwater Helicopter (AUH) is proposed in this paper, which utilizes acoustic-inertial-optical guidance. Unlike conventional Autonomous Underwater Vehicles (AUVs), the maneuverability requirements for AUHs are more stringent during the docking procedure, requiring it to remain stationary or have minimal horizontal movement while moving vertically. The docking procedure is divided into two stages: Homing and Landing, each stage utilizing different guidance methods. Additionally, a segmented aligning strategy operating at various altitudes and a linear velocity decision are both adopted in Landing stage. Due to the unique structure of the Subsea Docking System (SDS), the AUH is required to dock onto the SDS in a fixed orientation with specific attitude and altitude. Therefore, a particular criterion is proposed to determine whether the AUH has successfully docked onto the SDS. Furthermore, the effectiveness and robustness of the proposed control method in AUH's docking procedure are demonstrated through pool experiments and sea trials.
Multi-Scale Temporal Transformer For Speech Emotion Recognition
Oct 01, 2024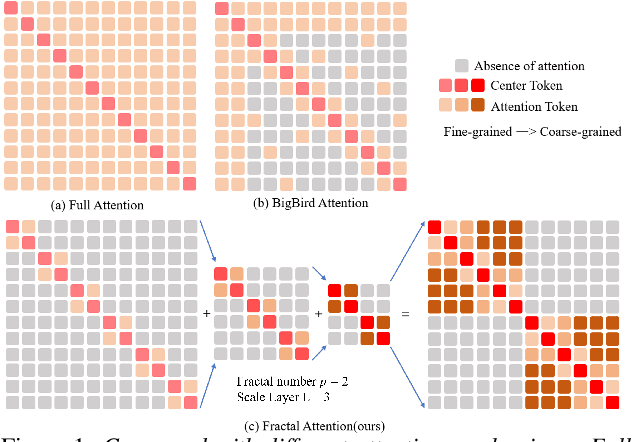
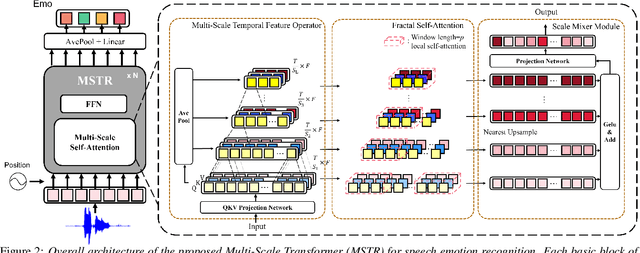
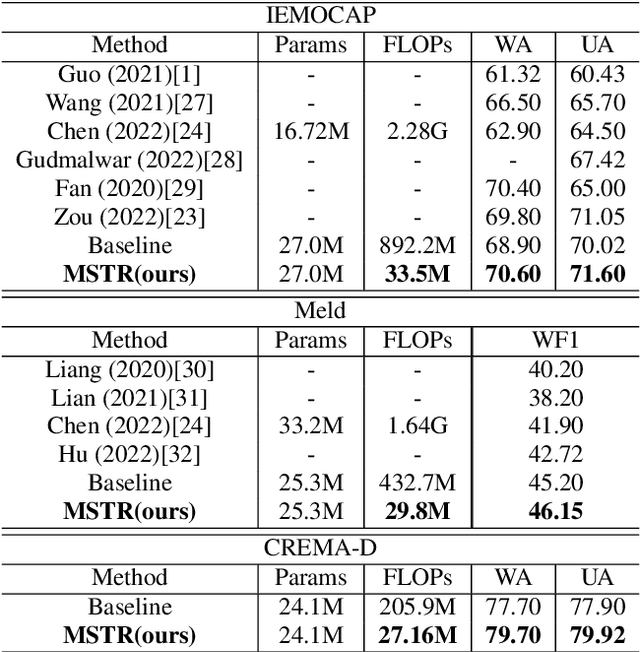
Speech emotion recognition plays a crucial role in human-machine interaction systems. Recently various optimized Transformers have been successfully applied to speech emotion recognition. However, the existing Transformer architectures focus more on global information and require large computation. On the other hand, abundant speech emotional representations exist locally on different parts of the input speech. To tackle these problems, we propose a Multi-Scale TRansfomer (MSTR) for speech emotion recognition. It comprises of three main components: (1) a multi-scale temporal feature operator, (2) a fractal self-attention module, and (3) a scale mixer module. These three components can effectively enhance the transformer's ability to learn multi-scale local emotion representations. Experimental results demonstrate that the proposed MSTR model significantly outperforms a vanilla Transformer and other state-of-the-art methods across three speech emotion datasets: IEMOCAP, MELD and, CREMAD. In addition, it can greatly reduce the computational cost.
AS-Speech: Adaptive Style For Speech Synthesis
Sep 09, 2024In recent years, there has been significant progress in Text-to-Speech (TTS) synthesis technology, enabling the high-quality synthesis of voices in common scenarios. In unseen situations, adaptive TTS requires a strong generalization capability to speaker style characteristics. However, the existing adaptive methods can only extract and integrate coarse-grained timbre or mixed rhythm attributes separately. In this paper, we propose AS-Speech, an adaptive style methodology that integrates the speaker timbre characteristics and rhythmic attributes into a unified framework for text-to-speech synthesis. Specifically, AS-Speech can accurately simulate style characteristics through fine-grained text-based timbre features and global rhythm information, and achieve high-fidelity speech synthesis through the diffusion model. Experiments show that the proposed model produces voices with higher naturalness and similarity in terms of timbre and rhythm compared to a series of adaptive TTS models.
Automated architectural space layout planning using a physics-inspired generative design framework
Jun 21, 2024



The determination of space layout is one of the primary activities in the schematic design stage of an architectural project. The initial layout planning defines the shape, dimension, and circulation pattern of internal spaces; which can also affect performance and cost of the construction. When carried out manually, space layout planning can be complicated, repetitive and time consuming. In this work, a generative design framework for the automatic generation of spatial architectural layout has been developed. The proposed approach integrates a novel physics-inspired parametric model for space layout planning and an evolutionary optimisation metaheuristic. Results revealed that such a generative design framework can generate a wide variety of design suggestions at the schematic design stage, applicable to complex design problems.
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
May 14, 2024Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
Time2Stop: Adaptive and Explainable Human-AI Loop for Smartphone Overuse Intervention
Mar 03, 2024Despite a rich history of investigating smartphone overuse intervention techniques, AI-based just-in-time adaptive intervention (JITAI) methods for overuse reduction are lacking. We develop Time2Stop, an intelligent, adaptive, and explainable JITAI system that leverages machine learning to identify optimal intervention timings, introduces interventions with transparent AI explanations, and collects user feedback to establish a human-AI loop and adapt the intervention model over time. We conducted an 8-week field experiment (N=71) to evaluate the effectiveness of both the adaptation and explanation aspects of Time2Stop. Our results indicate that our adaptive models significantly outperform the baseline methods on intervention accuracy (>32.8\% relatively) and receptivity (>8.0\%). In addition, incorporating explanations further enhances the effectiveness by 53.8\% and 11.4\% on accuracy and receptivity, respectively. Moreover, Time2Stop significantly reduces overuse, decreasing app visit frequency by 7.0$\sim$8.9\%. Our subjective data also echoed these quantitative measures. Participants preferred the adaptive interventions and rated the system highly on intervention time accuracy, effectiveness, and level of trust. We envision our work can inspire future research on JITAI systems with a human-AI loop to evolve with users.
Multi-perspective Feedback-attention Coupling Model for Continuous-time Dynamic Graphs
Dec 13, 2023Recently, representation learning over graph networks has gained popularity, with various models showing promising results. Despite this, several challenges persist: 1) most methods are designed for static or discrete-time dynamic graphs; 2) existing continuous-time dynamic graph algorithms focus on a single evolving perspective; and 3) many continuous-time dynamic graph approaches necessitate numerous temporal neighbors to capture long-term dependencies. In response, this paper introduces the Multi-Perspective Feedback-Attention Coupling (MPFA) model. MPFA incorporates information from both evolving and raw perspectives, efficiently learning the interleaved dynamics of observed processes. The evolving perspective employs temporal self-attention to distinguish continuously evolving temporal neighbors for information aggregation. Through dynamic updates, this perspective can capture long-term dependencies using a small number of temporal neighbors. Meanwhile, the raw perspective utilizes a feedback attention module with growth characteristic coefficients to aggregate raw neighborhood information. Experimental results on a self-organizing dataset and seven public datasets validate the efficacy and competitiveness of our proposed model.
Joint Channel Estimation and Turbo Equalization of Single-Carrier Systems over Time-Varying Channels
May 16, 2023



Block transmission systems have been proven successful over frequency-selective channels. For time-varying channel such as in high-speed mobile communication and underwater communication, existing equalizers assume that channels over different data frames are independent. However, the real-world channels over different data frames are correlated, thereby indicating potentials for performance improvement. In this paper, we propose a joint channel estimation and equalization/decoding algorithm for a single-carrier system that exploits temporal correlations of channel between transmitted data frames. Leveraging the concept of dynamic compressive sensing, our method can utilize the information of several data frames to achieve better performance. The information not only passes between the channel and symbol, but also the channels over different data frames. Numerical simulations using an extensively validated underwater acoustic model with a time-varying channel establish that the proposed algorithm outperforms the former bilinear generalized approximate message passing equalizer and classic minimum mean square error turbo equalizer in bit error rate and channel estimation normalized mean square error. The algorithm idea we present can also find applications in other bilinear multiple measurements vector compressive sensing problems.