 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated architectural space layout planning using a physics-inspired generative design framework
Jun 21, 2024



The determination of space layout is one of the primary activities in the schematic design stage of an architectural project. The initial layout planning defines the shape, dimension, and circulation pattern of internal spaces; which can also affect performance and cost of the construction. When carried out manually, space layout planning can be complicated, repetitive and time consuming. In this work, a generative design framework for the automatic generation of spatial architectural layout has been developed. The proposed approach integrates a novel physics-inspired parametric model for space layout planning and an evolutionary optimisation metaheuristic. Results revealed that such a generative design framework can generate a wide variety of design suggestions at the schematic design stage, applicable to complex design problems.
Searching for chromate replacements using natural language processing and machine learning algorithms
Aug 11, 2022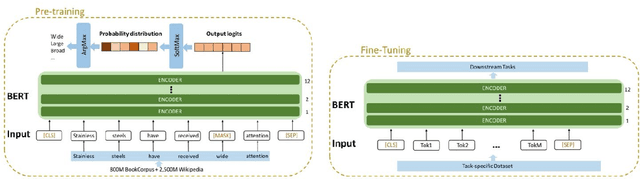

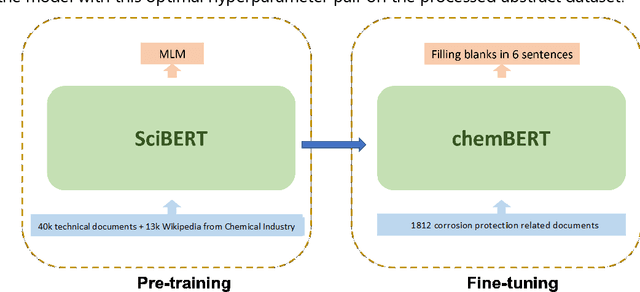
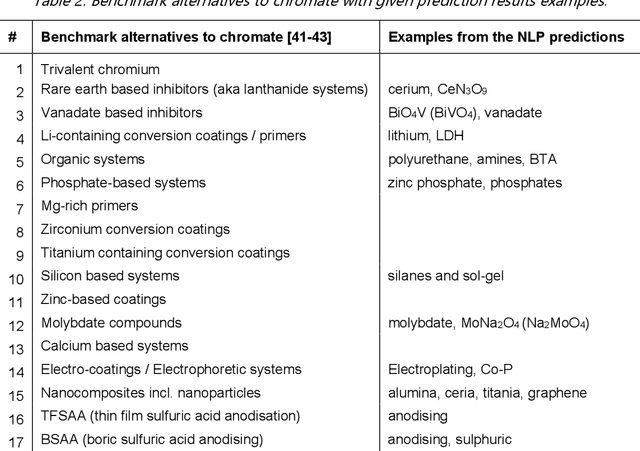
The past few years has seen the application of machine learning utilised in the exploration of new materials. As in many fields of research - the vast majority of knowledge is published as text, which poses challenges in either a consolidated or statistical analysis across studies and reports. Such challenges include the inability to extract quantitative information, and in accessing the breadth of non-numerical information. To address this issue, the application of natural language processing (NLP) has been explored in several studies to date. In NLP, assignment of high-dimensional vectors, known as embeddings, to passages of text preserves the syntactic and semantic relationship between words. Embeddings rely on machine learning algorithms and in the present work, we have employed the Word2Vec model, previously explored by others, and the BERT model - applying them towards a unique challenge in materials engineering. That challenge is the search for chromate replacements in the field of corrosion protection. From a database of over 80 million records, a down-selection of 5990 papers focused on the topic of corrosion protection were examined using NLP. This study demonstrates it is possible to extract knowledge from the automated interpretation of the scientific literature and achieve expert human level insights.
Quantity beats quality for semantic segmentation of corrosion in images
Jun 30, 2018
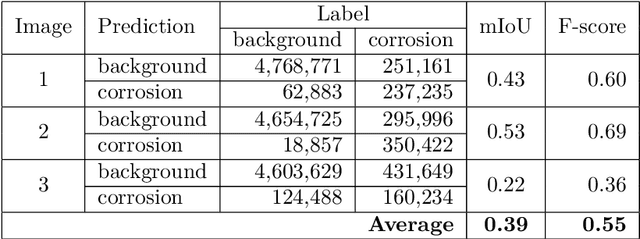

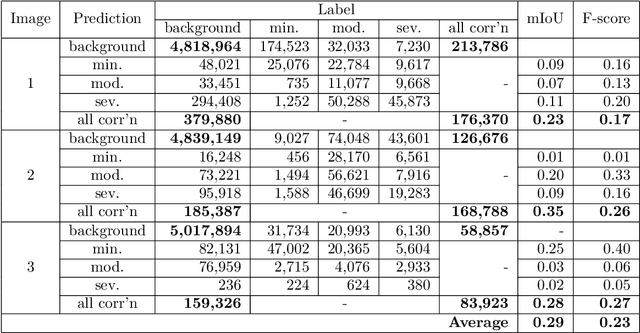
Dataset creation is typically one of the first steps when applying Artificial Intelligence methods to a new task; and the real world performance of models hinges on the quality and quantity of data available. Producing an image dataset for semantic segmentation is resource intensive, particularly for specialist subjects where class segmentation is not able to be effectively farmed out. The benefit of producing a large, but poorly labelled, dataset versus a small, expertly segmented dataset for semantic segmentation is an open question. Here we show that a large, noisy dataset outperforms a small, expertly segmented dataset for training a Fully Convolutional Network model for semantic segmentation of corrosion in images. A large dataset of 250 images with segmentations labelled by undergraduates and a second dataset of just 10 images, with segmentations labelled by subject matter experts were produced. The mean Intersection over Union and micro F-score metrics were compared after training for 50,000 epochs. This work is illustrative for researchers setting out to develop deep learning models for detection and location of specialist features.