 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for chromate replacements using natural language processing and machine learning algorithms
Paper and Code
Aug 11, 2022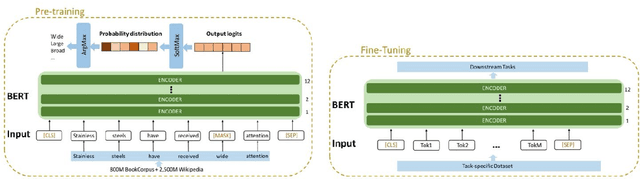

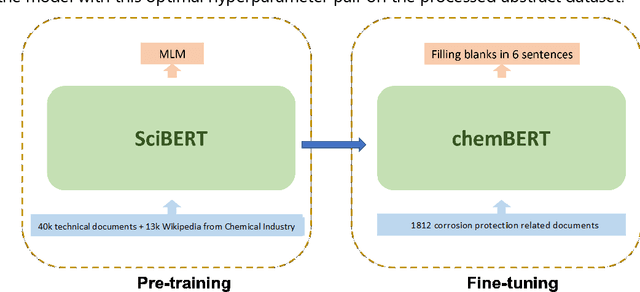
The past few years has seen the application of machine learning utilised in the exploration of new materials. As in many fields of research - the vast majority of knowledge is published as text, which poses challenges in either a consolidated or statistical analysis across studies and reports. Such challenges include the inability to extract quantitative information, and in accessing the breadth of non-numerical information. To address this issue, the application of natural language processing (NLP) has been explored in several studies to date. In NLP, assignment of high-dimensional vectors, known as embeddings, to passages of text preserves the syntactic and semantic relationship between words. Embeddings rely on machine learning algorithms and in the present work, we have employed the Word2Vec model, previously explored by others, and the BERT model - applying them towards a unique challenge in materials engineering. That challenge is the search for chromate replacements in the field of corrosion protection. From a database of over 80 million records, a down-selection of 5990 papers focused on the topic of corrosion protection were examined using NLP. This study demonstrates it is possible to extract knowledge from the automated interpretation of the scientific literature and achieve expert human level insights.