 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity beats quality for semantic segmentation of corrosion in images
Jun 30, 2018
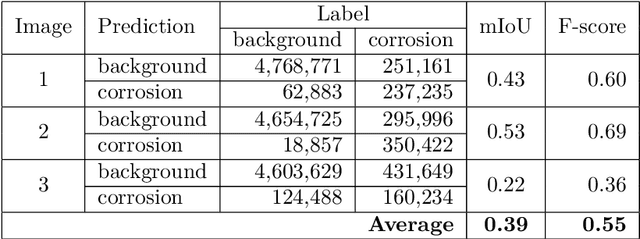

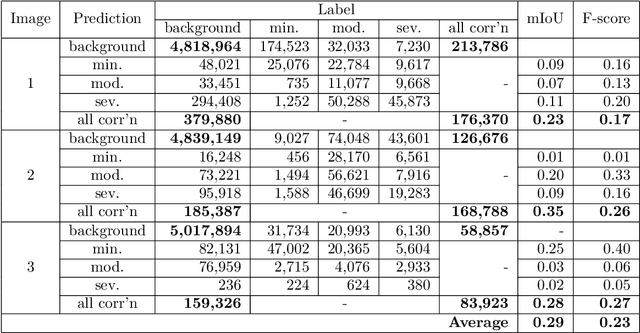
Dataset creation is typically one of the first steps when applying Artificial Intelligence methods to a new task; and the real world performance of models hinges on the quality and quantity of data available. Producing an image dataset for semantic segmentation is resource intensive, particularly for specialist subjects where class segmentation is not able to be effectively farmed out. The benefit of producing a large, but poorly labelled, dataset versus a small, expertly segmented dataset for semantic segmentation is an open question. Here we show that a large, noisy dataset outperforms a small, expertly segmented dataset for training a Fully Convolutional Network model for semantic segmentation of corrosion in images. A large dataset of 250 images with segmentations labelled by undergraduates and a second dataset of just 10 images, with segmentations labelled by subject matter experts were produced. The mean Intersection over Union and micro F-score metrics were compared after training for 50,000 epochs. This work is illustrative for researchers setting out to develop deep learning models for detection and location of specialist features.