 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Hybrid-Level Instruction Injection for Video Token Compression in Multi-modal Large Language Models
Mar 20, 2025Recent Multi-modal Large Language Models (MLLMs) have been challenged by the computational overhead resulting from massive video frames, often alleviated through compression strategies. However, the visual content is not equally contributed to user instructions, existing strategies (\eg, average pool) inevitably lead to the loss of potentially useful information. To tackle this, we propose the Hybrid-level Instruction Injection Strategy for Conditional Token Compression in MLLMs (HICom), utilizing the instruction as a condition to guide the compression from both local and global levels. This encourages the compression to retain the maximum amount of user-focused information while reducing visual tokens to minimize computational burden. Specifically, the instruction condition is injected into the grouped visual tokens at the local level and the learnable tokens at the global level, and we conduct the attention mechanism to complete the conditional compression. From the hybrid-level compression, the instruction-relevant visual parts are highlighted while the temporal-spatial structure is also preserved for easier understanding of LLMs. To further unleash the potential of HICom, we introduce a new conditional pre-training stage with our proposed dataset HICom-248K. Experiments show that our HICom can obtain distinguished video understanding ability with fewer tokens, increasing the performance by 2.43\% average on three multiple-choice QA benchmarks and saving 78.8\% tokens compared with the SOTA method. The code is available at https://github.com/lntzm/HICom.
Rethinking Video Tokenization: A Conditioned Diffusion-based Approach
Mar 05, 2025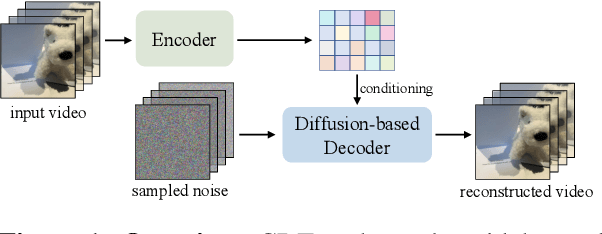
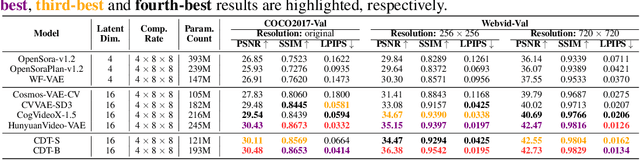
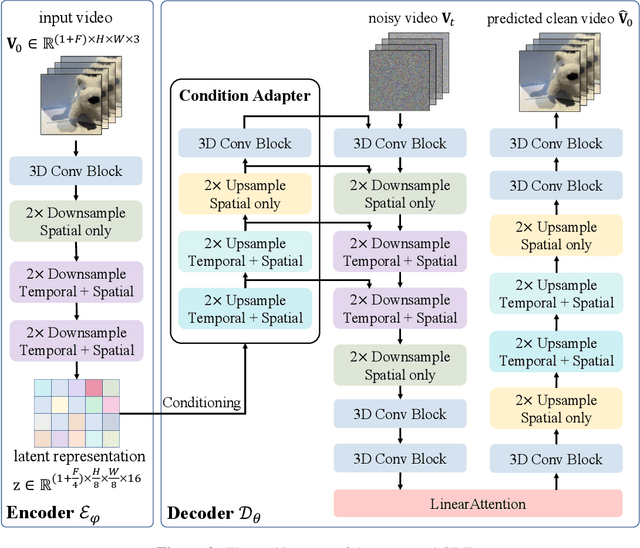
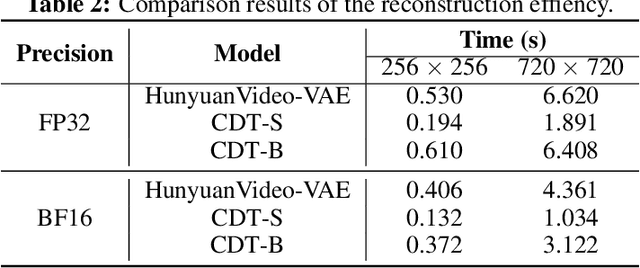
Video tokenizers, which transform videos into compact latent representations, are key to video generation. Existing video tokenizers are based on the VAE architecture and follow a paradigm where an encoder compresses videos into compact latents, and a deterministic decoder reconstructs the original videos from these latents. In this paper, we propose a novel \underline{\textbf{C}}onditioned \underline{\textbf{D}}iffusion-based video \underline{\textbf{T}}okenizer entitled \textbf{\ourmethod}, which departs from previous methods by replacing the deterministic decoder with a 3D causal diffusion model. The reverse diffusion generative process of the decoder is conditioned on the latent representations derived via the encoder. With a feature caching and sampling acceleration, the framework efficiently reconstructs high-fidelity videos of arbitrary lengths. Results show that {\ourmethod} achieves state-of-the-art performance in video reconstruction tasks using just a single-step sampling. Even a smaller version of {\ourmethod} still achieves reconstruction results on par with the top two baselines. Furthermore, the latent video generation model trained using {\ourmethod} also shows superior performance.
ContextHOI: Spatial Context Learning for Human-Object Interaction Detection
Dec 12, 2024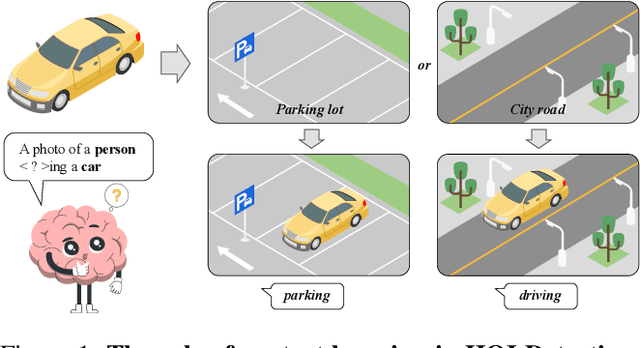
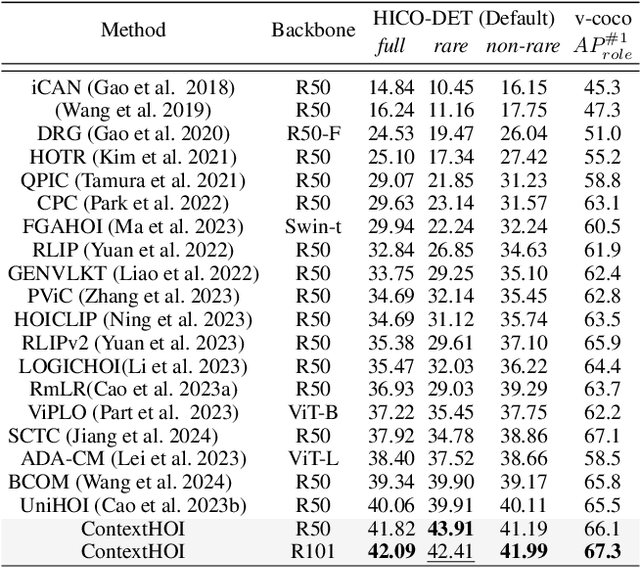
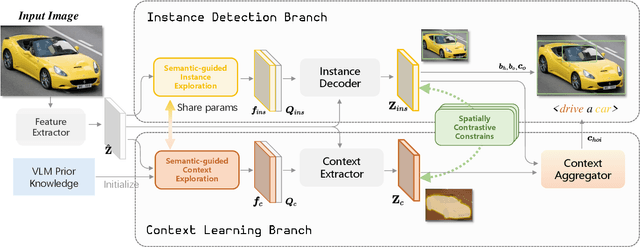
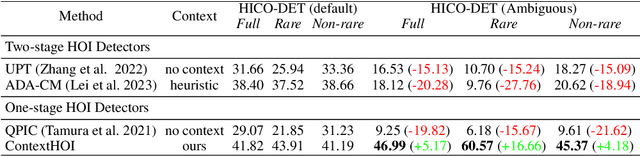
Spatial contexts, such as the backgrounds and surroundings, are considered critical in Human-Object Interaction (HOI) recognition, especially when the instance-centric foreground is blurred or occluded. Recent advancements in HOI detectors are usually built upon detection transformer pipelines. While such an object-detection-oriented paradigm shows promise in localizing objects, its exploration of spatial context is often insufficient for accurately recognizing human actions. To enhance the capabilities of object detectors for HOI detection, we present a dual-branch framework named ContextHOI, which efficiently captures both object detection features and spatial contexts. In the context branch, we train the model to extract informative spatial context without requiring additional hand-craft background labels. Furthermore, we introduce context-aware spatial and semantic supervision to the context branch to filter out irrelevant noise and capture informative contexts. ContextHOI achieves state-of-the-art performance on the HICO-DET and v-coco benchmarks. For further validation, we construct a novel benchmark, HICO-ambiguous, which is a subset of HICO-DET that contains images with occluded or impaired instance cues. Extensive experiments across all benchmarks, complemented by visualizations, underscore the enhancements provided by ContextHOI, especially in recognizing interactions involving occluded or blurred instances.
Orchestrating the Symphony of Prompt Distribution Learning for Human-Object Interaction Detection
Dec 11, 2024Human-object interaction (HOI) detectors with popular query-transformer architecture have achieved promising performance. However, accurately identifying uncommon visual patterns and distinguishing between ambiguous HOIs continue to be difficult for them. We observe that these difficulties may arise from the limited capacity of traditional detector queries in representing diverse intra-category patterns and inter-category dependencies. To address this, we introduce the Interaction Prompt Distribution Learning (InterProDa) approach. InterProDa learns multiple sets of soft prompts and estimates category distributions from various prompts. It then incorporates HOI queries with category distributions, making them capable of representing near-infinite intra-category dynamics and universal cross-category relationships. Our InterProDa detector demonstrates competitive performance on HICO-DET and vcoco benchmarks. Additionally, our method can be integrated into most transformer-based HOI detectors, significantly enhancing their performance with minimal additional parameters.
Improved Video VAE for Latent Video Diffusion Model
Nov 10, 2024



Variational Autoencoder (VAE) aims to compress pixel data into low-dimensional latent space, playing an important role in OpenAI's Sora and other latent video diffusion generation models. While most of existing video VAEs inflate a pretrained image VAE into the 3D causal structure for temporal-spatial compression, this paper presents two astonishing findings: (1) The initialization from a well-trained image VAE with the same latent dimensions suppresses the improvement of subsequent temporal compression capabilities. (2) The adoption of causal reasoning leads to unequal information interactions and unbalanced performance between frames. To alleviate these problems, we propose a keyframe-based temporal compression (KTC) architecture and a group causal convolution (GCConv) module to further improve video VAE (IV-VAE). Specifically, the KTC architecture divides the latent space into two branches, in which one half completely inherits the compression prior of keyframes from a lower-dimension image VAE while the other half involves temporal compression through 3D group causal convolution, reducing temporal-spatial conflicts and accelerating the convergence speed of video VAE. The GCConv in above 3D half uses standard convolution within each frame group to ensure inter-frame equivalence, and employs causal logical padding between groups to maintain flexibility in processing variable frame video. Extensive experiments on five benchmarks demonstrate the SOTA video reconstruction and generation capabilities of the proposed IV-VAE (https://wpy1999.github.io/IV-VAE/).
Control System Design and Experiments for Autonomous Underwater Helicopter Docking Procedure Based on Acoustic-inertial-optical Guidance
Oct 09, 2024
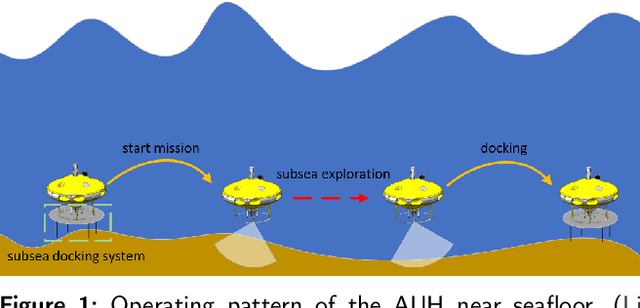
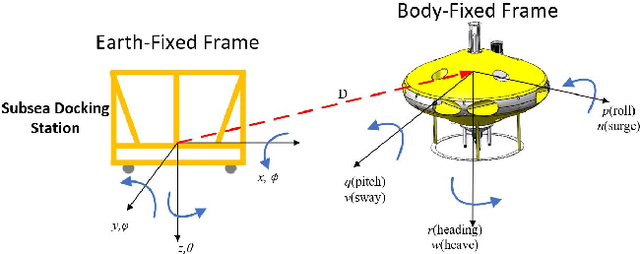

A control system structure for the underwater docking procedure of an Autonomous Underwater Helicopter (AUH) is proposed in this paper, which utilizes acoustic-inertial-optical guidance. Unlike conventional Autonomous Underwater Vehicles (AUVs), the maneuverability requirements for AUHs are more stringent during the docking procedure, requiring it to remain stationary or have minimal horizontal movement while moving vertically. The docking procedure is divided into two stages: Homing and Landing, each stage utilizing different guidance methods. Additionally, a segmented aligning strategy operating at various altitudes and a linear velocity decision are both adopted in Landing stage. Due to the unique structure of the Subsea Docking System (SDS), the AUH is required to dock onto the SDS in a fixed orientation with specific attitude and altitude. Therefore, a particular criterion is proposed to determine whether the AUH has successfully docked onto the SDS. Furthermore, the effectiveness and robustness of the proposed control method in AUH's docking procedure are demonstrated through pool experiments and sea trials.
Learning Restricted Boltzmann Machines with greedy quantum search
Sep 25, 2023
Restricted Boltzmann Machines (RBMs) are widely used probabilistic undirected graphical models with visible and latent nodes, playing an important role in statistics and machine learning. The task of structure learning for RBMs involves inferring the underlying graph by using samples from the visible nodes. Specifically, learning the two-hop neighbors of each visible node allows for the inference of the graph structure. Prior research has addressed the structure learning problem for specific classes of RBMs, namely ferromagnetic and locally consistent RBMs. In this paper, we extend the scope to the quantum computing domain and propose corresponding quantum algorithms for this problem. Our study demonstrates that the proposed quantum algorithms yield a polynomial speedup compared to the classical algorithms for learning the structure of these two classes of RBMs.
Provable learning of quantum states with graphical models
Sep 17, 2023The complete learning of an $n$-qubit quantum state requires samples exponentially in $n$. Several works consider subclasses of quantum states that can be learned in polynomial sample complexity such as stabilizer states or high-temperature Gibbs states. Other works consider a weaker sense of learning, such as PAC learning and shadow tomography. In this work, we consider learning states that are close to neural network quantum states, which can efficiently be represented by a graphical model called restricted Boltzmann machines (RBMs). To this end, we exhibit robustness results for efficient provable two-hop neighborhood learning algorithms for ferromagnetic and locally consistent RBMs. We consider the $L_p$-norm as a measure of closeness, including both total variation distance and max-norm distance in the limit. Our results allow certain quantum states to be learned with a sample complexity \textit{exponentially} better than naive tomography. We hence provide new classes of efficiently learnable quantum states and apply new strategies to learn them.
MomentDiff: Generative Video Moment Retrieval from Random to Real
Jul 06, 2023Video moment retrieval pursues an efficient and generalized solution to identify the specific temporal segments within an untrimmed video that correspond to a given language description. To achieve this goal, we provide a generative diffusion-based framework called MomentDiff, which simulates a typical human retrieval process from random browsing to gradual localization. Specifically, we first diffuse the real span to random noise, and learn to denoise the random noise to the original span with the guidance of similarity between text and video. This allows the model to learn a mapping from arbitrary random locations to real moments, enabling the ability to locate segments from random initialization. Once trained, MomentDiff could sample random temporal segments as initial guesses and iteratively refine them to generate an accurate temporal boundary. Different from discriminative works (e.g., based on learnable proposals or queries), MomentDiff with random initialized spans could resist the temporal location biases from datasets. To evaluate the influence of the temporal location biases, we propose two anti-bias datasets with location distribution shifts, named Charades-STA-Len and Charades-STA-Mom. The experimental results demonstrate that our efficient framework consistently outperforms state-of-the-art methods on three public benchmarks, and exhibits better generalization and robustness on the proposed anti-bias datasets. The code, model, and anti-bias evaluation datasets are available at https://github.com/IMCCretrieval/MomentDiff.