 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
Jan 28, 2026Item indexing, which maps a large corpus of items into compact discrete representations, is critical for both discriminative and generative recommender systems, yet existing Vector Quantization (VQ)-based approaches struggle with the highly skewed and non-stationary item distributions common in streaming industry recommenders, leading to poor assignment accuracy, imbalanced cluster occupancy, and insufficient cluster separation. To address these challenges, we propose MERGE, a next-generation item indexing paradigm that adaptively constructs clusters from scratch, dynamically monitors cluster occupancy, and forms hierarchical index structures via fine-to-coarse merging. Extensive experiments demonstrate that MERGE significantly improves assignment accuracy, cluster uniformity, and cluster separation compared with existing indexing methods, while online A/B tests show substantial gains in key business metrics, highlighting its potential as a foundational indexing approach for large-scale recommendation.
A DVL Aided Loosely Coupled Inertial Navigation Strategy for AUVs with Attitude Error Modeling and Variance Propagation
Jan 27, 2026In underwater navigation systems, strap-down inertial navigation system/Doppler velocity log (SINS/DVL)-based loosely coupled architectures are widely adopted. Conventional approaches project DVL velocities from the body coordinate system to the navigation coordinate system using SINS-derived attitude; however, accumulated attitude estimation errors introduce biases into velocity projection and degrade navigation performance during long-term operation. To address this issue, two complementary improvements are introduced. First, a vehicle attitude error-aware DVL velocity transformation model is formulated by incorporating attitude error terms into the observation equation to reduce projection-induced velocity bias. Second, a covariance matrix-based variance propagation method is developed to transform DVL measurement uncertainty across coordinate systems, introducing an expectation-based attitude error compensation term to achieve statistically consistent noise modeling. Simulation and field experiment results demonstrate that both improvements individually enhance navigation accuracy and confirm that accumulated attitude errors affect both projected velocity measurements and their associated uncertainty. When jointly applied, long-term error divergence is effectively suppressed. Field experimental results show that the proposed approach achieves a 78.3% improvement in 3D position RMSE and a 71.8% reduction in the maximum component-wise position error compared with the baseline IMU+DVL method, providing a robust solution for improving long-term SINS/DVL navigation performance.
Control System Design and Experiments for Autonomous Underwater Helicopter Docking Procedure Based on Acoustic-inertial-optical Guidance
Oct 09, 2024
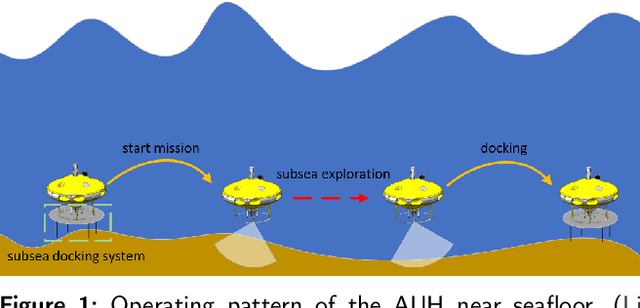
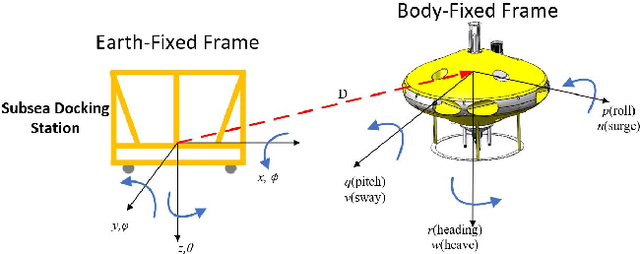

A control system structure for the underwater docking procedure of an Autonomous Underwater Helicopter (AUH) is proposed in this paper, which utilizes acoustic-inertial-optical guidance. Unlike conventional Autonomous Underwater Vehicles (AUVs), the maneuverability requirements for AUHs are more stringent during the docking procedure, requiring it to remain stationary or have minimal horizontal movement while moving vertically. The docking procedure is divided into two stages: Homing and Landing, each stage utilizing different guidance methods. Additionally, a segmented aligning strategy operating at various altitudes and a linear velocity decision are both adopted in Landing stage. Due to the unique structure of the Subsea Docking System (SDS), the AUH is required to dock onto the SDS in a fixed orientation with specific attitude and altitude. Therefore, a particular criterion is proposed to determine whether the AUH has successfully docked onto the SDS. Furthermore, the effectiveness and robustness of the proposed control method in AUH's docking procedure are demonstrated through pool experiments and sea trials.
SPIDR: SDF-based Neural Point Fields for Illumination and Deformation
Oct 15, 2022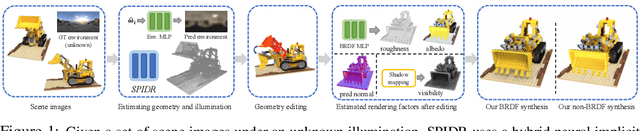
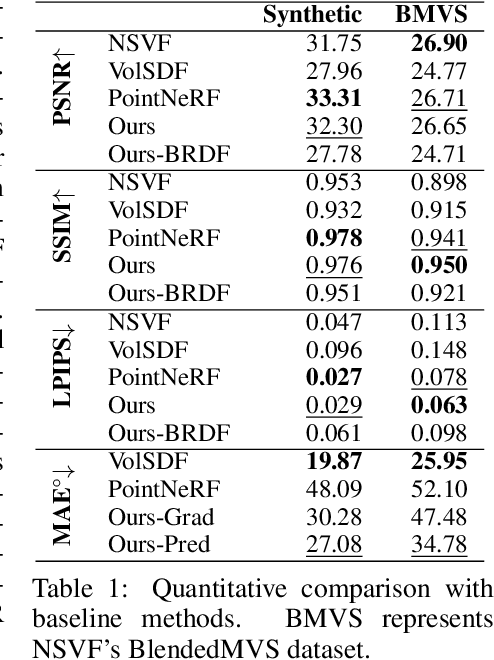

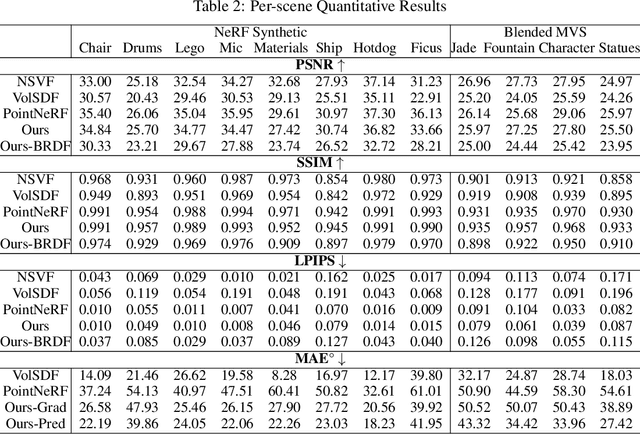
Implicit neural representations such as neural radiance fields (NeRFs) have recently emerged as a promising approach for 3D reconstruction and novel view synthesis. However, NeRF-based methods encode shape, reflectance, and illumination implicitly in their neural representations, and this makes it challenging for users to manipulate these properties in the rendered images explicitly. Existing approaches only enable limited editing of the scene and deformation of the geometry. Furthermore, no existing work enables accurate scene illumination after object deformation. In this work, we introduce SPIDR, a new hybrid neural SDF representation. SPIDR combines point cloud and neural implicit representations to enable the reconstruction of higher quality meshes and surfaces for object deformation and lighting estimation. To more accurately capture environment illumination for scene relighting, we propose a novel neural implicit model to learn environment light. To enable accurate illumination updates after deformation, we use the shadow mapping technique to efficiently approximate the light visibility updates caused by geometry editing. We demonstrate the effectiveness of SPIDR in enabling high quality geometry editing and deformation with accurate updates to the illumination of the scene. In comparison to prior work, we demonstrate significantly better rendering quality after deformation and lighting estimation.
Neural Shape Mating: Self-Supervised Object Assembly with Adversarial Shape Priors
May 30, 2022Learning to autonomously assemble shapes is a crucial skill for many robotic applications. While the majority of existing part assembly methods focus on correctly posing semantic parts to recreate a whole object, we interpret assembly more literally: as mating geometric parts together to achieve a snug fit. By focusing on shape alignment rather than semantic cues, we can achieve across-category generalization. In this paper, we introduce a novel task, pairwise 3D geometric shape mating, and propose Neural Shape Mating (NSM) to tackle this problem. Given the point clouds of two object parts of an unknown category, NSM learns to reason about the fit of the two parts and predict a pair of 3D poses that tightly mate them together. We couple the training of NSM with an implicit shape reconstruction task to make NSM more robust to imperfect point cloud observations. To train NSM, we present a self-supervised data collection pipeline that generates pairwise shape mating data with ground truth by randomly cutting an object mesh into two parts, resulting in a dataset that consists of 200K shape mating pairs from numerous object meshes with diverse cut types. We train NSM on the collected dataset and compare it with several point cloud registration methods and one part assembly baseline. Extensive experimental results and ablation studies under various settings demonstrate the effectiveness of the proposed algorithm. Additional material is available at: https://neural-shape-mating.github.io/
Decompose the Sounds and Pixels, Recompose the Events
Dec 21, 2021

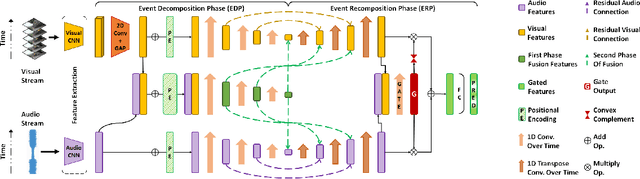
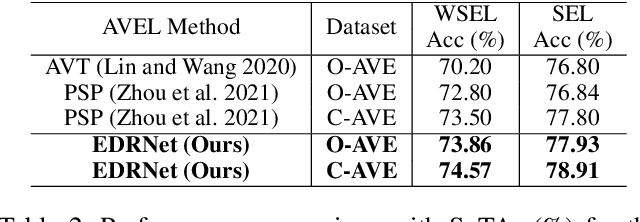
In this paper, we propose a framework centering around a novel architecture called the Event Decomposition Recomposition Network (EDRNet) to tackle the Audio-Visual Event (AVE) localization problem in the supervised and weakly supervised settings. AVEs in the real world exhibit common unravelling patterns (termed as Event Progress Checkpoints (EPC)), which humans can perceive through the cooperation of their auditory and visual senses. Unlike earlier methods which attempt to recognize entire event sequences, the EDRNet models EPCs and inter-EPC relationships using stacked temporal convolutions. Based on the postulation that EPC representations are theoretically consistent for an event category, we introduce the State Machine Based Video Fusion, a novel augmentation technique that blends source videos using different EPC template sequences. Additionally, we design a new loss function called the Land-Shore-Sea loss to compactify continuous foreground and background representations. Lastly, to alleviate the issue of confusing events during weak supervision, we propose a prediction stabilization method called Bag to Instance Label Correction. Experiments on the AVE dataset show that our collective framework outperforms the state-of-the-art by a sizable margin.