 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGimmBO: Interactive Generative Image Model Merging via Bayesian Optimization
Jan 26, 2026Fine-tuning-based adaptation is widely used to customize diffusion-based image generation, leading to large collections of community-created adapters that capture diverse subjects and styles. Adapters derived from the same base model can be merged with weights, enabling the synthesis of new visual results within a vast and continuous design space. To explore this space, current workflows rely on manual slider-based tuning, an approach that scales poorly and makes weight selection difficult, even when the candidate set is limited to 20-30 adapters. We propose GimmBO to support interactive exploration of adapter merging for image generation through Preferential Bayesian Optimization (PBO). Motivated by observations from real-world usage, including sparsity and constrained weight ranges, we introduce a two-stage BO backend that improves sampling efficiency and convergence in high-dimensional spaces. We evaluate our approach with simulated users and a user study, demonstrating improved convergence, high success rates, and consistent gains over BO and line-search baselines, and further show the flexibility of the framework through several extensions.
Stochastic Preconditioning for Neural Field Optimization
May 26, 2025Neural fields are a highly effective representation across visual computing. This work observes that fitting these fields is greatly improved by incorporating spatial stochasticity during training, and that this simple technique can replace or even outperform custom-designed hierarchies and frequency space constructions. The approach is formalized as implicitly operating on a blurred version of the field, evaluated in-expectation by sampling with Gaussian-distributed offsets. Querying the blurred field during optimization greatly improves convergence and robustness, akin to the role of preconditioners in numerical linear algebra. This implicit, sampling-based perspective fits naturally into the neural field paradigm, comes at no additional cost, and is extremely simple to implement. We describe the basic theory of this technique, including details such as handling boundary conditions, and extending to a spatially-varying blur. Experiments demonstrate this approach on representations including coordinate MLPs, neural hashgrids, triplanes, and more, across tasks including surface reconstruction and radiance fields. In settings where custom-designed hierarchies have already been developed, stochastic preconditioning nearly matches or improves their performance with a simple and unified approach; in settings without existing hierarchies it provides an immediate boost to quality and robustness.
Rigid Body Adversarial Attacks
Feb 08, 2025



Due to their performance and simplicity, rigid body simulators are often used in applications where the objects of interest can considered very stiff. However, no material has infinite stiffness, which means there are potentially cases where the non-zero compliance of the seemingly rigid object can cause a significant difference between its trajectories when simulated in a rigid body or deformable simulator. Similarly to how adversarial attacks are developed against image classifiers, we propose an adversarial attack against rigid body simulators. In this adversarial attack, we solve an optimization problem to construct perceptually rigid adversarial objects that have the same collision geometry and moments of mass to a reference object, so that they behave identically in rigid body simulations but maximally different in more accurate deformable simulations. We demonstrate the validity of our method by comparing simulations of several examples in commercially available simulators.
A LoRA is Worth a Thousand Pictures
Dec 16, 2024Recent advances in diffusion models and parameter-efficient fine-tuning (PEFT) have made text-to-image generation and customization widely accessible, with Low Rank Adaptation (LoRA) able to replicate an artist's style or subject using minimal data and computation. In this paper, we examine the relationship between LoRA weights and artistic styles, demonstrating that LoRA weights alone can serve as an effective descriptor of style, without the need for additional image generation or knowledge of the original training set. Our findings show that LoRA weights yield better performance in clustering of artistic styles compared to traditional pre-trained features, such as CLIP and DINO, with strong structural similarities between LoRA-based and conventional image-based embeddings observed both qualitatively and quantitatively. We identify various retrieval scenarios for the growing collection of customized models and show that our approach enables more accurate retrieval in real-world settings where knowledge of the training images is unavailable and additional generation is required. We conclude with a discussion on potential future applications, such as zero-shot LoRA fine-tuning and model attribution.
RoMo: Robust Motion Segmentation Improves Structure from Motion
Nov 27, 2024
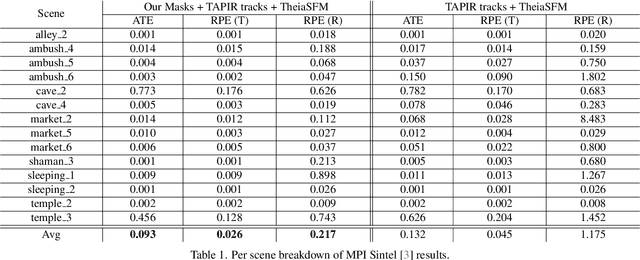


There has been extensive progress in the reconstruction and generation of 4D scenes from monocular casually-captured video. While these tasks rely heavily on known camera poses, the problem of finding such poses using structure-from-motion (SfM) often depends on robustly separating static from dynamic parts of a video. The lack of a robust solution to this problem limits the performance of SfM camera-calibration pipelines. We propose a novel approach to video-based motion segmentation to identify the components of a scene that are moving w.r.t. a fixed world frame. Our simple but effective iterative method, RoMo, combines optical flow and epipolar cues with a pre-trained video segmentation model. It outperforms unsupervised baselines for motion segmentation as well as supervised baselines trained from synthetic data. More importantly, the combination of an off-the-shelf SfM pipeline with our segmentation masks establishes a new state-of-the-art on camera calibration for scenes with dynamic content, outperforming existing methods by a substantial margin.
SpotlessSplats: Ignoring Distractors in 3D Gaussian Splatting
Jun 28, 2024
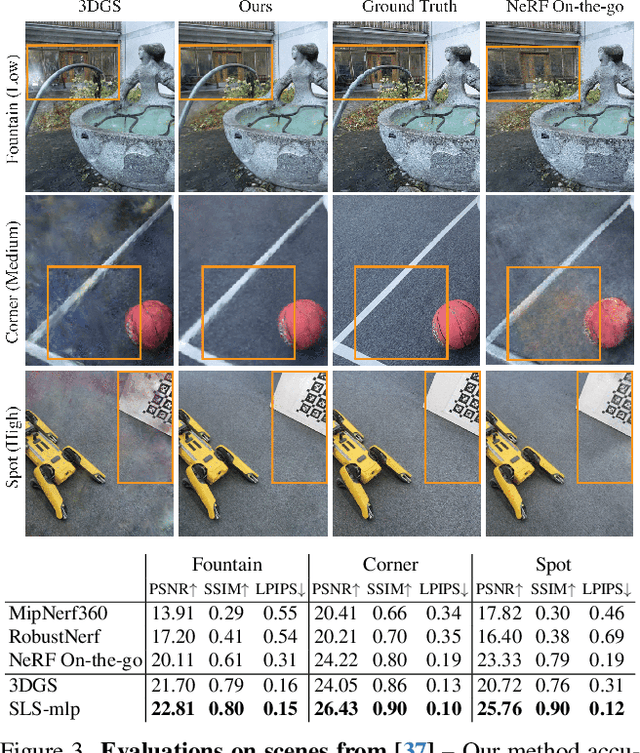

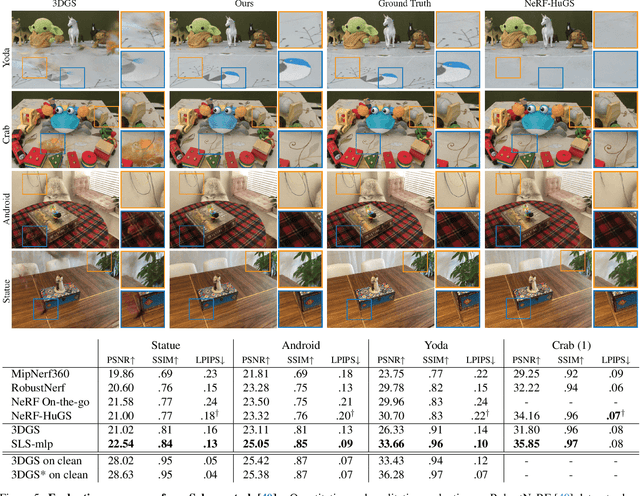
3D Gaussian Splatting (3DGS) is a promising technique for 3D reconstruction, offering efficient training and rendering speeds, making it suitable for real-time applications.However, current methods require highly controlled environments (no moving people or wind-blown elements, and consistent lighting) to meet the inter-view consistency assumption of 3DGS. This makes reconstruction of real-world captures problematic. We present SpotlessSplats, an approach that leverages pre-trained and general-purpose features coupled with robust optimization to effectively ignore transient distractors. Our method achieves state-of-the-art reconstruction quality both visually and quantitatively, on casual captures.
Text-guided Controllable Mesh Refinement for Interactive 3D Modeling
Jun 03, 2024We propose a novel technique for adding geometric details to an input coarse 3D mesh guided by a text prompt. Our method is composed of three stages. First, we generate a single-view RGB image conditioned on the input coarse geometry and the input text prompt. This single-view image generation step allows the user to pre-visualize the result and offers stronger conditioning for subsequent multi-view generation. Second, we use our novel multi-view normal generation architecture to jointly generate six different views of the normal images. The joint view generation reduces inconsistencies and leads to sharper details. Third, we optimize our mesh with respect to all views and generate a fine, detailed geometry as output. The resulting method produces an output within seconds and offers explicit user control over the coarse structure, pose, and desired details of the resulting 3D mesh. Project page: https://text-mesh-refinement.github.io.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023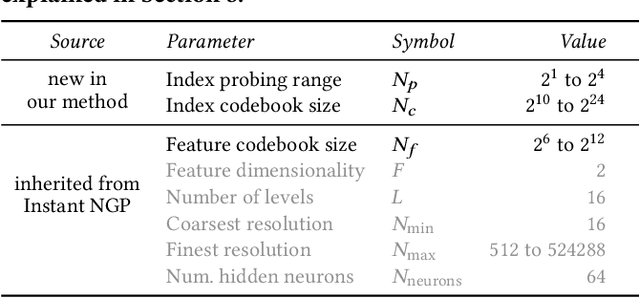



Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
VecFusion: Vector Font Generation with Diffusion
Dec 16, 2023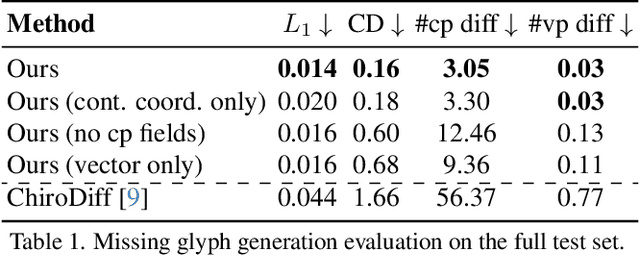

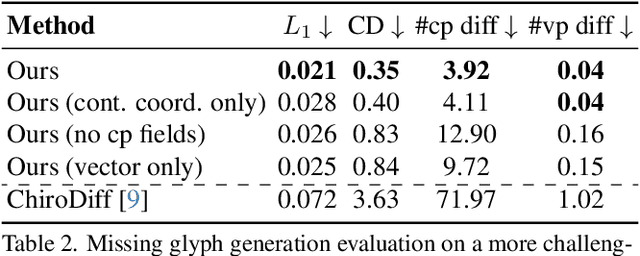

We present VecFusion, a new neural architecture that can generate vector fonts with varying topological structures and precise control point positions. Our approach is a cascaded diffusion model which consists of a raster diffusion model followed by a vector diffusion model. The raster model generates low-resolution, rasterized fonts with auxiliary control point information, capturing the global style and shape of the font, while the vector model synthesizes vector fonts conditioned on the low-resolution raster fonts from the first stage. To synthesize long and complex curves, our vector diffusion model uses a transformer architecture and a novel vector representation that enables the modeling of diverse vector geometry and the precise prediction of control points. Our experiments show that, in contrast to previous generative models for vector graphics, our new cascaded vector diffusion model generates higher quality vector fonts, with complex structures and diverse styles.
Neural Stochastic Screened Poisson Reconstruction
Sep 21, 2023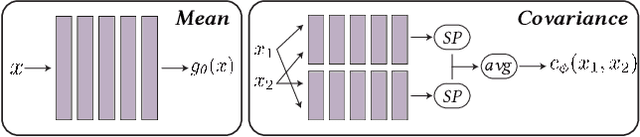


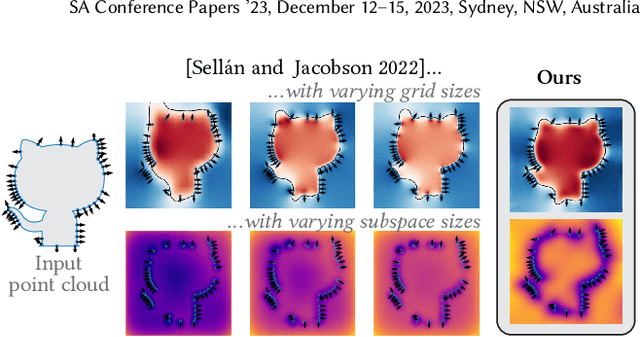
Reconstructing a surface from a point cloud is an underdetermined problem. We use a neural network to study and quantify this reconstruction uncertainty under a Poisson smoothness prior. Our algorithm addresses the main limitations of existing work and can be fully integrated into the 3D scanning pipeline, from obtaining an initial reconstruction to deciding on the next best sensor position and updating the reconstruction upon capturing more data.