 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGimmBO: Interactive Generative Image Model Merging via Bayesian Optimization
Jan 26, 2026Fine-tuning-based adaptation is widely used to customize diffusion-based image generation, leading to large collections of community-created adapters that capture diverse subjects and styles. Adapters derived from the same base model can be merged with weights, enabling the synthesis of new visual results within a vast and continuous design space. To explore this space, current workflows rely on manual slider-based tuning, an approach that scales poorly and makes weight selection difficult, even when the candidate set is limited to 20-30 adapters. We propose GimmBO to support interactive exploration of adapter merging for image generation through Preferential Bayesian Optimization (PBO). Motivated by observations from real-world usage, including sparsity and constrained weight ranges, we introduce a two-stage BO backend that improves sampling efficiency and convergence in high-dimensional spaces. We evaluate our approach with simulated users and a user study, demonstrating improved convergence, high success rates, and consistent gains over BO and line-search baselines, and further show the flexibility of the framework through several extensions.
Stochastic Preconditioning for Neural Field Optimization
May 26, 2025Neural fields are a highly effective representation across visual computing. This work observes that fitting these fields is greatly improved by incorporating spatial stochasticity during training, and that this simple technique can replace or even outperform custom-designed hierarchies and frequency space constructions. The approach is formalized as implicitly operating on a blurred version of the field, evaluated in-expectation by sampling with Gaussian-distributed offsets. Querying the blurred field during optimization greatly improves convergence and robustness, akin to the role of preconditioners in numerical linear algebra. This implicit, sampling-based perspective fits naturally into the neural field paradigm, comes at no additional cost, and is extremely simple to implement. We describe the basic theory of this technique, including details such as handling boundary conditions, and extending to a spatially-varying blur. Experiments demonstrate this approach on representations including coordinate MLPs, neural hashgrids, triplanes, and more, across tasks including surface reconstruction and radiance fields. In settings where custom-designed hierarchies have already been developed, stochastic preconditioning nearly matches or improves their performance with a simple and unified approach; in settings without existing hierarchies it provides an immediate boost to quality and robustness.
Text-guided Controllable Mesh Refinement for Interactive 3D Modeling
Jun 03, 2024We propose a novel technique for adding geometric details to an input coarse 3D mesh guided by a text prompt. Our method is composed of three stages. First, we generate a single-view RGB image conditioned on the input coarse geometry and the input text prompt. This single-view image generation step allows the user to pre-visualize the result and offers stronger conditioning for subsequent multi-view generation. Second, we use our novel multi-view normal generation architecture to jointly generate six different views of the normal images. The joint view generation reduces inconsistencies and leads to sharper details. Third, we optimize our mesh with respect to all views and generate a fine, detailed geometry as output. The resulting method produces an output within seconds and offers explicit user control over the coarse structure, pose, and desired details of the resulting 3D mesh. Project page: https://text-mesh-refinement.github.io.
VectorAdam for Rotation Equivariant Geometry Optimization
May 26, 2022
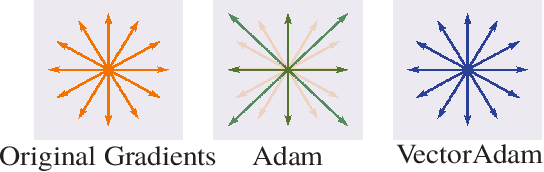

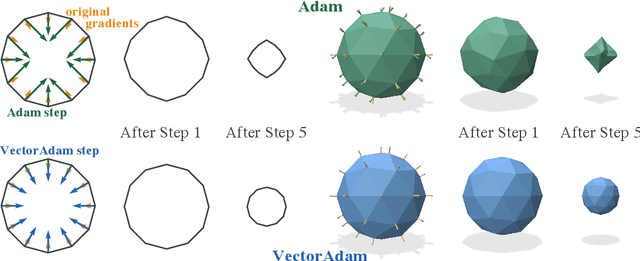
The rise of geometric problems in machine learning has necessitated the development of equivariant methods, which preserve their output under the action of rotation or some other transformation. At the same time, the Adam optimization algorithm has proven remarkably effective across machine learning and even traditional tasks in geometric optimization. In this work, we observe that naively applying Adam to optimize vector-valued data is not rotation equivariant, due to per-coordinate moment updates, and in fact this leads to significant artifacts and biases in practice. We propose to resolve this deficiency with VectorAdam, a simple modification which makes Adam rotation-equivariant by accounting for the vector structure of optimization variables. We demonstrate this approach on problems in machine learning and traditional geometric optimization, showing that equivariant VectorAdam resolves the artifacts and biases of traditional Adam when applied to vector-valued data, with equivalent or even improved rates of convergence.
Roominoes: Generating Novel 3D Floor Plans From Existing 3D Rooms
Dec 10, 2021Realistic 3D indoor scene datasets have enabled significant recent progress in computer vision, scene understanding, autonomous navigation, and 3D reconstruction. But the scale, diversity, and customizability of existing datasets is limited, and it is time-consuming and expensive to scan and annotate more. Fortunately, combinatorics is on our side: there are enough individual rooms in existing 3D scene datasets, if there was but a way to recombine them into new layouts. In this paper, we propose the task of generating novel 3D floor plans from existing 3D rooms. We identify three sub-tasks of this problem: generation of 2D layout, retrieval of compatible 3D rooms, and deformation of 3D rooms to fit the layout. We then discuss different strategies for solving the problem, and design two representative pipelines: one uses available 2D floor plans to guide selection and deformation of 3D rooms; the other learns to retrieve a set of compatible 3D rooms and combine them into novel layouts. We design a set of metrics that evaluate the generated results with respect to each of the three subtasks and show that different methods trade off performance on these subtasks. Finally, we survey downstream tasks that benefit from generated 3D scenes and discuss strategies in selecting the methods most appropriate for the demands of these tasks.
* Symposium on Geometry Processing (SGP) 2021
MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Aug 14, 2020We introduce a method to convert stereo 360{\deg} (omnidirectional stereo) imagery into a layered, multi-sphere image representation for six degree-of-freedom (6DoF) rendering. Stereo 360{\deg} imagery can be captured from multi-camera systems for virtual reality (VR), but lacks motion parallax and correct-in-all-directions disparity cues. Together, these can quickly lead to VR sickness when viewing content. One solution is to try and generate a format suitable for 6DoF rendering, such as by estimating depth. However, this raises questions as to how to handle disoccluded regions in dynamic scenes. Our approach is to simultaneously learn depth and disocclusions via a multi-sphere image representation, which can be rendered with correct 6DoF disparity and motion parallax in VR. This significantly improves comfort for the viewer, and can be inferred and rendered in real time on modern GPU hardware. Together, these move towards making VR video a more comfortable immersive medium.