 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored, Not Graded: Vision-Language Models Fail at Slant-from-Texture Perception
Jun 04, 2026Human perception of surface slant from texture exhibits systematic, graded biases that emerge reliably in psychophysical experiments. Prior work showed that unsupervised CNNs reproduce several human-like biases, while supervised CNNs do not. Do Vision-Language Models (VLMs) exhibit similar competences? Across multiple VLM families and model scales, zero-shot and in-context prompting both produce distinctive failures: slant is predicted at only a small set of anchors (e.g., 0\degree, $\pm$25\degree, $\pm$45\degree) with little dependence on stimulus field of view, optical slant, or surface curvature. Supervised fine-tuning partially remediates the failure, but residual anchoring persists. While success in high-level vision-language benchmarks might not require sensitivity to low-level geometric cues, we interpret anchoring as a failure at the representation-to-output language interface: Not necessarily an absence of geometric encoding, but a failure to express it in a graded form.
TreeDGS: Aerial Gaussian Splatting for Distant DBH Measurement
Jan 19, 2026Aerial remote sensing enables efficient large-area surveying, but accurate direct object-level measurement remains difficult in complex natural scenes. Recent advancements in 3D vision, particularly learned radiance-field representations such as NeRF and 3D Gaussian Splatting, have begun to raise the ceiling on reconstruction fidelity and densifiable geometry from posed imagery. Nevertheless, direct aerial measurement of important natural attributes such as tree diameter at breast height (DBH) remains challenging. Trunks in aerial forest scans are distant and sparsely observed in image views: at typical operating altitudes, stems may span only a few pixels. With these constraints, conventional reconstruction methods leave breast-height trunk geometry weakly constrained. We present TreeDGS, an aerial image reconstruction method that leverages 3D Gaussian Splatting as a continuous, densifiable scene representation for trunk measurement. After SfM-MVS initialization and Gaussian optimization, we extract a dense point set from the Gaussian field using RaDe-GS's depth-aware cumulative-opacity integration and associate each sample with a multi-view opacity reliability score. We then estimate DBH from trunk-isolated points using opacity-weighted solid-circle fitting. Evaluated on 10 plots with field-measured DBH, TreeDGS reaches 4.79,cm RMSE (about 2.6 pixels at this GSD) and outperforms a state-of-the-art LiDAR baseline (7.91,cm RMSE), demonstrating that densified splat-based geometry can enable accurate, low-cost aerial DBH measurement.
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
Time of the Flight of the Gaussians: Optimizing Depth Indirectly in Dynamic Radiance Fields
May 08, 2025We present a method to reconstruct dynamic scenes from monocular continuous-wave time-of-flight (C-ToF) cameras using raw sensor samples that achieves similar or better accuracy than neural volumetric approaches and is 100x faster. Quickly achieving high-fidelity dynamic 3D reconstruction from a single viewpoint is a significant challenge in computer vision. In C-ToF radiance field reconstruction, the property of interest-depth-is not directly measured, causing an additional challenge. This problem has a large and underappreciated impact upon the optimization when using a fast primitive-based scene representation like 3D Gaussian splatting, which is commonly used with multi-view data to produce satisfactory results and is brittle in its optimization otherwise. We incorporate two heuristics into the optimization to improve the accuracy of scene geometry represented by Gaussians. Experimental results show that our approach produces accurate reconstructions under constrained C-ToF sensing conditions, including for fast motions like swinging baseball bats. https://visual.cs.brown.edu/gftorf
Zero-Shot Monocular Scene Flow Estimation in the Wild
Jan 17, 2025Large models have shown generalization across datasets for many low-level vision tasks, like depth estimation, but no such general models exist for scene flow. Even though scene flow has wide potential use, it is not used in practice because current predictive models do not generalize well. We identify three key challenges and propose solutions for each.First, we create a method that jointly estimates geometry and motion for accurate prediction. Second, we alleviate scene flow data scarcity with a data recipe that affords us 1M annotated training samples across diverse synthetic scenes. Third, we evaluate different parameterizations for scene flow prediction and adopt a natural and effective parameterization. Our resulting model outperforms existing methods as well as baselines built on large-scale models in terms of 3D end-point error, and shows zero-shot generalization to the casually captured videos from DAVIS and the robotic manipulation scenes from RoboTAP. Overall, our approach makes scene flow prediction more practical in-the-wild.
The GAN is dead; long live the GAN! A Modern GAN Baseline
Jan 09, 2025
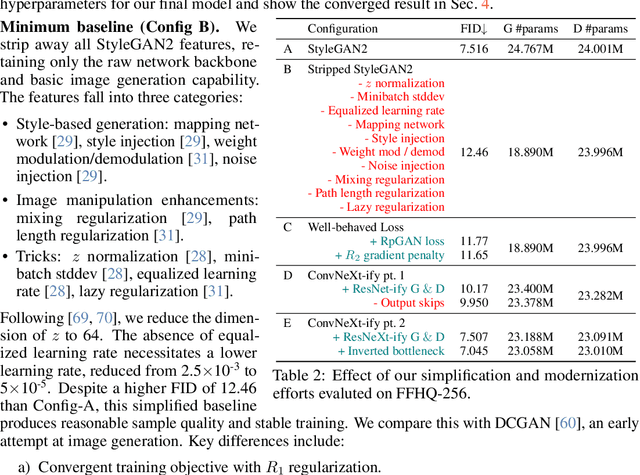


There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, our new loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline -- R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.
Monocular Dynamic Gaussian Splatting is Fast and Brittle but Smooth Motion Helps
Dec 05, 2024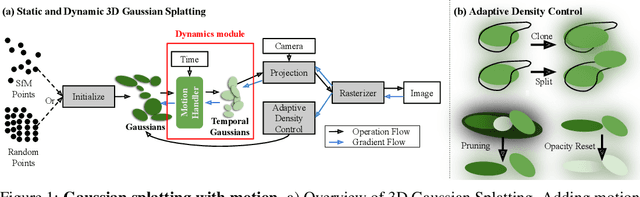
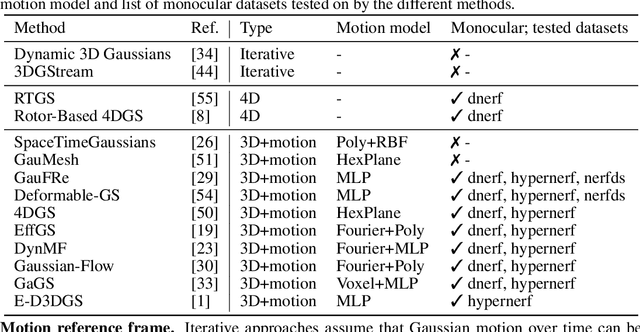

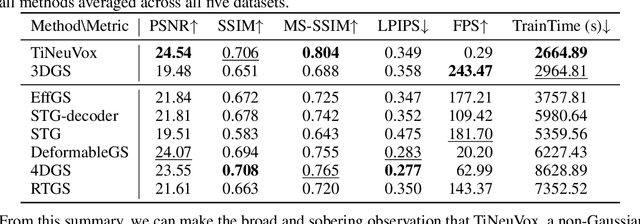
Gaussian splatting methods are emerging as a popular approach for converting multi-view image data into scene representations that allow view synthesis. In particular, there is interest in enabling view synthesis for dynamic scenes using only monocular input data -- an ill-posed and challenging problem. The fast pace of work in this area has produced multiple simultaneous papers that claim to work best, which cannot all be true. In this work, we organize, benchmark, and analyze many Gaussian-splatting-based methods, providing apples-to-apples comparisons that prior works have lacked. We use multiple existing datasets and a new instructive synthetic dataset designed to isolate factors that affect reconstruction quality. We systematically categorize Gaussian splatting methods into specific motion representation types and quantify how their differences impact performance. Empirically, we find that their rank order is well-defined in synthetic data, but the complexity of real-world data currently overwhelms the differences. Furthermore, the fast rendering speed of all Gaussian-based methods comes at the cost of brittleness in optimization. We summarize our experiments into a list of findings that can help to further progress in this lively problem setting. Project Webpage: https://lynl7130.github.io/MonoDyGauBench.github.io/
OmniSDF: Scene Reconstruction using Omnidirectional Signed Distance Functions and Adaptive Binoctrees
Mar 31, 2024We present a method to reconstruct indoor and outdoor static scene geometry and appearance from an omnidirectional video moving in a small circular sweep. This setting is challenging because of the small baseline and large depth ranges, making it difficult to find ray crossings. To better constrain the optimization, we estimate geometry as a signed distance field within a spherical binoctree data structure and use a complementary efficient tree traversal strategy based on a breadth-first search for sampling. Unlike regular grids or trees, the shape of this structure well-matches the camera setting, creating a better memory-quality trade-off. From an initial depth estimate, the binoctree is adaptively subdivided throughout the optimization; previous methods use a fixed depth that leaves the scene undersampled. In comparison with three neural optimization methods and two non-neural methods, ours shows decreased geometry error on average, especially in a detailed scene, while significantly reducing the required number of voxels to represent such details.
GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis
Dec 18, 2023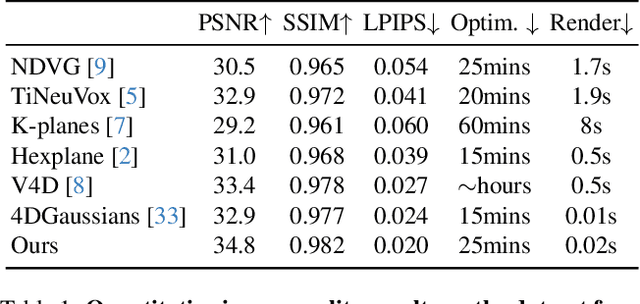
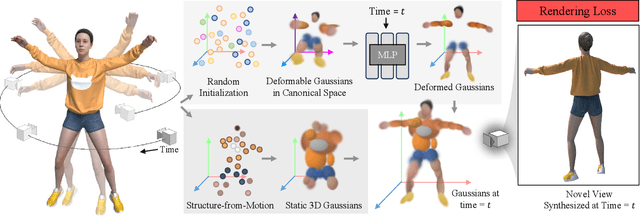
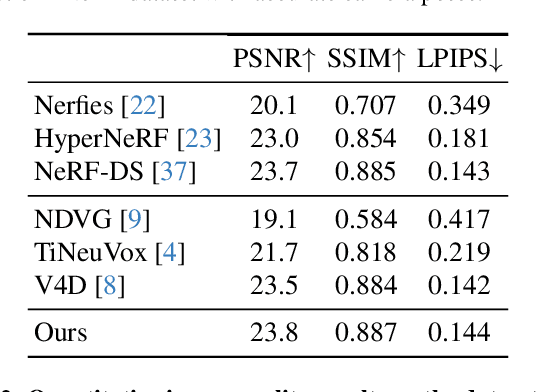
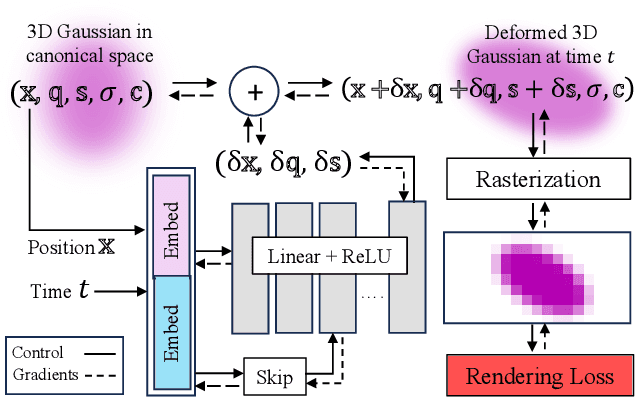
We propose a method for dynamic scene reconstruction using deformable 3D Gaussians that is tailored for monocular video. Building upon the efficiency of Gaussian splatting, our approach extends the representation to accommodate dynamic elements via a deformable set of Gaussians residing in a canonical space, and a time-dependent deformation field defined by a multi-layer perceptron (MLP). Moreover, under the assumption that most natural scenes have large regions that remain static, we allow the MLP to focus its representational power by additionally including a static Gaussian point cloud. The concatenated dynamic and static point clouds form the input for the Gaussian Splatting rasterizer, enabling real-time rendering. The differentiable pipeline is optimized end-to-end with a self-supervised rendering loss. Our method achieves results that are comparable to state-of-the-art dynamic neural radiance field methods while allowing much faster optimization and rendering. Project website: https://lynl7130.github.io/gaufre/index.html
'Tax-free' 3DMM Conditional Face Generation
May 22, 2023



3DMM conditioned face generation has gained traction due to its well-defined controllability; however, the trade-off is lower sample quality: Previous works such as DiscoFaceGAN and 3D-FM GAN show a significant FID gap compared to the unconditional StyleGAN, suggesting that there is a quality tax to pay for controllability. In this paper, we challenge the assumption that quality and controllability cannot coexist. To pinpoint the previous issues, we mathematically formalize the problem of 3DMM conditioned face generation. Then, we devise simple solutions to the problem under our proposed framework. This results in a new model that effectively removes the quality tax between 3DMM conditioned face GANs and the unconditional StyleGAN.