 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Attention Flow Fields for Dynamic Scene Decomposition
Mar 02, 2023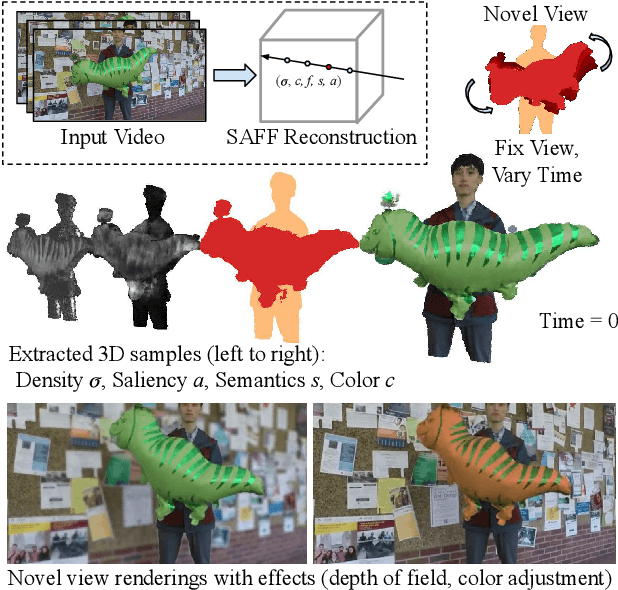
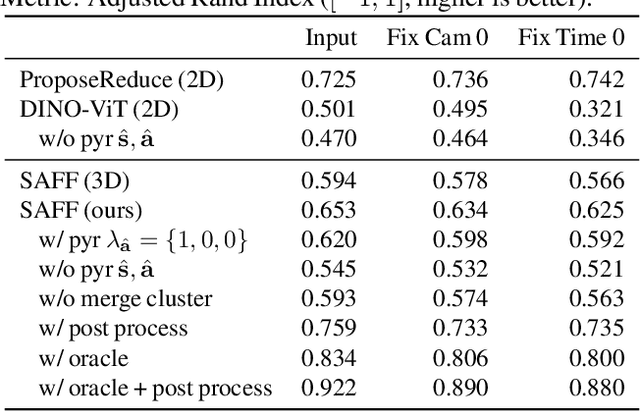
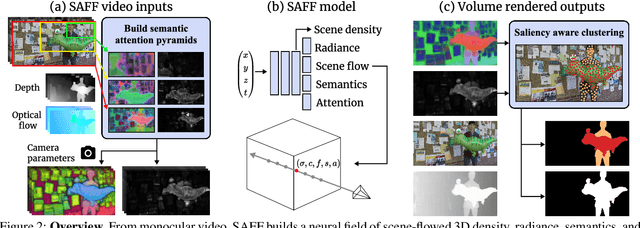
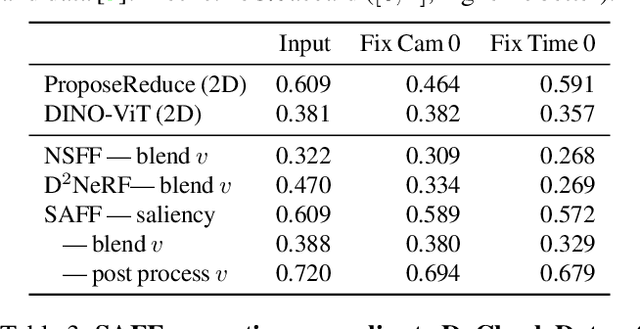
We present SAFF: a dynamic neural volume reconstruction of a casual monocular video that consists of time-varying color, density, scene flow, semantics, and attention information. The semantics and attention let us identify salient foreground objects separately from the background in arbitrary spacetime views. We add two network heads to represent the semantic and attention information. For optimization, we design semantic attention pyramids from DINO-ViT outputs that trade detail with whole-image context. After optimization, we perform a saliency-aware clustering to decompose the scene. For evaluation on real-world dynamic scene decomposition across spacetime, we annotate object masks in the NVIDIA Dynamic Scene Dataset. We demonstrate that SAFF can decompose dynamic scenes without affecting RGB or depth reconstruction quality, that volume-integrated SAFF outperforms 2D baselines, and that SAFF improves foreground/background segmentation over recent static/dynamic split methods. Project Webpage: https://visual.cs.brown.edu/saff